 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards symbolic regression for interpretable clinical decision scores
Dec 08, 2025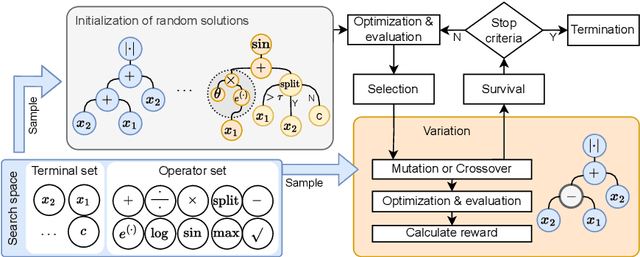

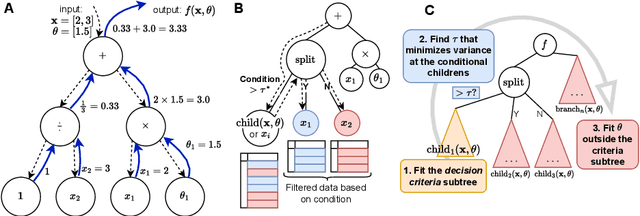

Medical decision-making makes frequent use of algorithms that combine risk equations with rules, providing clear and standardized treatment pathways. Symbolic regression (SR) traditionally limits its search space to continuous function forms and their parameters, making it difficult to model this decision-making. However, due to its ability to derive data-driven, interpretable models, SR holds promise for developing data-driven clinical risk scores. To that end we introduce Brush, an SR algorithm that combines decision-tree-like splitting algorithms with non-linear constant optimization, allowing for seamless integration of rule-based logic into symbolic regression and classification models. Brush achieves Pareto-optimal performance on SRBench, and was applied to recapitulate two widely used clinical scoring systems, achieving high accuracy and interpretable models. Compared to decision trees, random forests, and other SR methods, Brush achieves comparable or superior predictive performance while producing simpler models.
Equitable Survival Prediction: A Fairness-Aware Survival Modeling (FASM) Approach
Oct 23, 2025As machine learning models become increasingly integrated into healthcare, structural inequities and social biases embedded in clinical data can be perpetuated or even amplified by data-driven models. In survival analysis, censoring and time dynamics can further add complexity to fair model development. Additionally, algorithmic fairness approaches often overlook disparities in cross-group rankings, e.g., high-risk Black patients may be ranked below lower-risk White patients who do not experience the event of mortality. Such misranking can reinforce biological essentialism and undermine equitable care. We propose a Fairness-Aware Survival Modeling (FASM), designed to mitigate algorithmic bias regarding both intra-group and cross-group risk rankings over time. Using breast cancer prognosis as a representative case and applying FASM to SEER breast cancer data, we show that FASM substantially improves fairness while preserving discrimination performance comparable to fairness-unaware survival models. Time-stratified evaluations show that FASM maintains stable fairness over a 10-year horizon, with the greatest improvements observed during the mid-term of follow-up. Our approach enables the development of survival models that prioritize both accuracy and equity in clinical decision-making, advancing fairness as a core principle in clinical care.
Iterative Learning of Computable Phenotypes for Treatment Resistant Hypertension using Large Language Models
Aug 07, 2025



Large language models (LLMs) have demonstrated remarkable capabilities for medical question answering and programming, but their potential for generating interpretable computable phenotypes (CPs) is under-explored. In this work, we investigate whether LLMs can generate accurate and concise CPs for six clinical phenotypes of varying complexity, which could be leveraged to enable scalable clinical decision support to improve care for patients with hypertension. In addition to evaluating zero-short performance, we propose and test a synthesize, execute, debug, instruct strategy that uses LLMs to generate and iteratively refine CPs using data-driven feedback. Our results show that LLMs, coupled with iterative learning, can generate interpretable and reasonably accurate programs that approach the performance of state-of-the-art ML methods while requiring significantly fewer training examples.
Call for Action: towards the next generation of symbolic regression benchmark
May 06, 2025


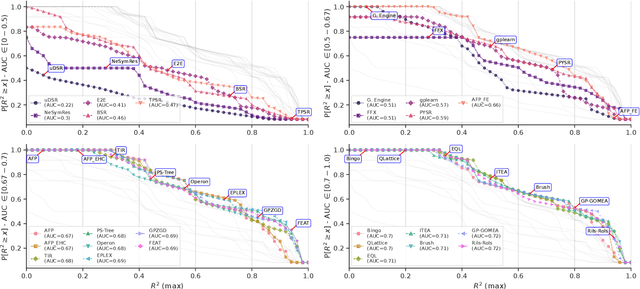
Symbolic Regression (SR) is a powerful technique for discovering interpretable mathematical expressions. However, benchmarking SR methods remains challenging due to the diversity of algorithms, datasets, and evaluation criteria. In this work, we present an updated version of SRBench. Our benchmark expands the previous one by nearly doubling the number of evaluated methods, refining evaluation metrics, and using improved visualizations of the results to understand the performances. Additionally, we analyze trade-offs between model complexity, accuracy, and energy consumption. Our results show that no single algorithm dominates across all datasets. We propose a call for action from SR community in maintaining and evolving SRBench as a living benchmark that reflects the state-of-the-art in symbolic regression, by standardizing hyperparameter tuning, execution constraints, and computational resource allocation. We also propose deprecation criteria to maintain the benchmark's relevance and discuss best practices for improving SR algorithms, such as adaptive hyperparameter tuning and energy-efficient implementations.
Benchmarking mortality risk prediction from electrocardiograms
Jun 26, 2024Several recent high-impact studies leverage large hospital-owned electrocardiographic (ECG) databases to model and predict patient mortality. MIMIC-IV, released September 2023, is the first comparable public dataset and includes 800,000 ECGs from a U.S. hospital system. Previously, the largest public ECG dataset was Code-15, containing 345,000 ECGs collected during routine care in Brazil. These datasets now provide an excellent resource for a broader audience to explore ECG survival modeling. Here, we benchmark survival model performance on Code-15 and MIMIC-IV with two neural network architectures, compare four deep survival modeling approaches to Cox regressions trained on classifier outputs, and evaluate performance at one to ten years. Our results yield AUROC and concordance scores comparable to past work (circa 0.8) and reasonable AUPRC scores (MIMIC-IV: 0.4-0.5, Code-15: 0.05-0.13) considering the fraction of ECG samples linked to a mortality (MIMIC-IV: 27\%, Code-15: 4\%). When evaluating models on the opposite dataset, AUROC and concordance values drop by 0.1-0.15, which may be due to cohort differences. All code and results are made public.
Cross-Care: Assessing the Healthcare Implications of Pre-training Data on Language Model Bias
May 09, 2024



Large language models (LLMs) are increasingly essential in processing natural languages, yet their application is frequently compromised by biases and inaccuracies originating in their training data. In this study, we introduce Cross-Care, the first benchmark framework dedicated to assessing biases and real world knowledge in LLMs, specifically focusing on the representation of disease prevalence across diverse demographic groups. We systematically evaluate how demographic biases embedded in pre-training corpora like $ThePile$ influence the outputs of LLMs. We expose and quantify discrepancies by juxtaposing these biases against actual disease prevalences in various U.S. demographic groups. Our results highlight substantial misalignment between LLM representation of disease prevalence and real disease prevalence rates across demographic subgroups, indicating a pronounced risk of bias propagation and a lack of real-world grounding for medical applications of LLMs. Furthermore, we observe that various alignment methods minimally resolve inconsistencies in the models' representation of disease prevalence across different languages. For further exploration and analysis, we make all data and a data visualization tool available at: www.crosscare.net.
Minimum variance threshold for epsilon-lexicase selection
Apr 08, 2024Parent selection plays an important role in evolutionary algorithms, and many strategies exist to select the parent pool before breeding the next generation. Methods often rely on average error over the entire dataset as a criterion to select the parents, which can lead to an information loss due to aggregation of all test cases. Under epsilon-lexicase selection, the population goes to a selection pool that is iteratively reduced by using each test individually, discarding individuals with an error higher than the elite error plus the median absolute deviation (MAD) of errors for that particular test case. In an attempt to better capture differences in performance of individuals on cases, we propose a new criteria that splits errors into two partitions that minimize the total variance within partitions. Our method was embedded into the FEAT symbolic regression algorithm, and evaluated with the SRBench framework, containing 122 black-box synthetic and real-world regression problems. The empirical results show a better performance of our approach compared to traditional epsilon-lexicase selection in the real-world datasets while showing equivalent performance on the synthetic dataset.
* 9 pages, 13 figures, accepted in Genetic and Evolutionary Computation Conference (GECCO '24)
Inexact Simplification of Symbolic Regression Expressions with Locality-sensitive Hashing
Apr 08, 2024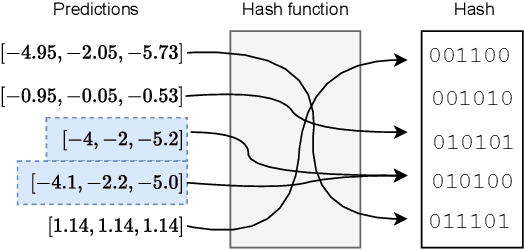

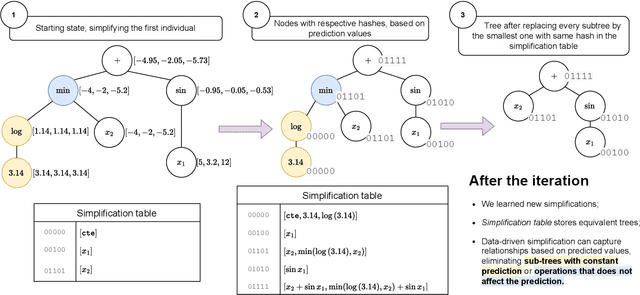
Symbolic regression (SR) searches for parametric models that accurately fit a dataset, prioritizing simplicity and interpretability. Despite this secondary objective, studies point out that the models are often overly complex due to redundant operations, introns, and bloat that arise during the iterative process, and can hinder the search with repeated exploration of bloated segments. Applying a fast heuristic algebraic simplification may not fully simplify the expression and exact methods can be infeasible depending on size or complexity of the expressions. We propose a novel agnostic simplification and bloat control for SR employing an efficient memoization with locality-sensitive hashing (LHS). The idea is that expressions and their sub-expressions traversed during the iterative simplification process are stored in a dictionary using LHS, enabling efficient retrieval of similar structures. We iterate through the expression, replacing subtrees with others of same hash if they result in a smaller expression. Empirical results shows that applying this simplification during evolution performs equal or better than without simplification in minimization of error, significantly reducing the number of nonlinear functions. This technique can learn simplification rules that work in general or for a specific problem, and improves convergence while reducing model complexity.
* 9 pages, 10 figures, accepted to GECCO-24
Optimizing fairness tradeoffs in machine learning with multiobjective meta-models
Apr 21, 2023



Improving the fairness of machine learning models is a nuanced task that requires decision makers to reason about multiple, conflicting criteria. The majority of fair machine learning methods transform the error-fairness trade-off into a single objective problem with a parameter controlling the relative importance of error versus fairness. We propose instead to directly optimize the error-fairness tradeoff by using multi-objective optimization. We present a flexible framework for defining the fair machine learning task as a weighted classification problem with multiple cost functions. This framework is agnostic to the underlying prediction model as well as the metrics. We use multiobjective optimization to define the sample weights used in model training for a given machine learner, and adapt the weights to optimize multiple metrics of fairness and accuracy across a set of tasks. To reduce the number of optimized parameters, and to constrain their complexity with respect to population subgroups, we propose a novel meta-model approach that learns to map protected attributes to sample weights, rather than optimizing those weights directly. On a set of real-world problems, this approach outperforms current state-of-the-art methods by finding solution sets with preferable error/fairness trade-offs.