 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre you sure? A Comprehensive and Comprehensible Survey of Uncertainty Quantification in Symbolic Regression
Jun 04, 2026Symbolic regression (SR) is a class of methods that systematically explore the space of mathematical functions to discover models that accurately capture the underlying relationships in a dataset. Despite recent advances in the field, a lack of support for uncertainty quantification (UQ) limits its adoption in real-world decision processes. In regression analysis, UQ provides important information about the model reliability, which can both help to avoid overfitting by accounting for uncertainty in the data, and provide insights for decision-making. This survey is the first to clearly address this issue, with the objective of introducing essential UQ concepts and reviewing the current literature on UQ in SR, which can be broadly organized into three research directions: frequentist, Bayesian, and model selection. Despite its importance, UQ in SR is still underexplored, which motivates further research into reliable UQ methods for SR.
Guiding Multi-Objective Genetic Programming with Description Length Improves Symbolic Regression Solutions
May 21, 2026Symbolic regression with genetic programming (GPSR) may suffer from overfitting and structural bloat, especially when noise is present. In this paper we evaluate description length (DL) and fractional Bayes factor (FBF) criteria as principled, data-efficient alternatives to heuristics for selecting compact expressions that generalise well. We implement DL using a Fisher-information-based parameter encoding and compare it to AIC and BIC across multiple datasets, including noisy synthetic benchmarks and real-world regression problems. We study three search/selection strategies: (i) multi-objective search for accuracy and program length followed by DL/FBF selection; (ii) multi-objective search using DL directly as an objective; and (iii) single-objective optimisation with DL/FBF as the fitness. Across datasets we find that DL/FBF post-selection improves test performance compared to AIC/BIC baseline and that BIC in combination with the same function complexity penalty from DL/FBF produces similar results. In contrast, using DL/FBF directly as a fitness function in single-objective GPSR frequently induces premature convergence to overly simple models. We conclude with practical guidance for using DL/FBF as robust model-selection tools in genetic programming workflows.
Towards symbolic regression for interpretable clinical decision scores
Dec 08, 2025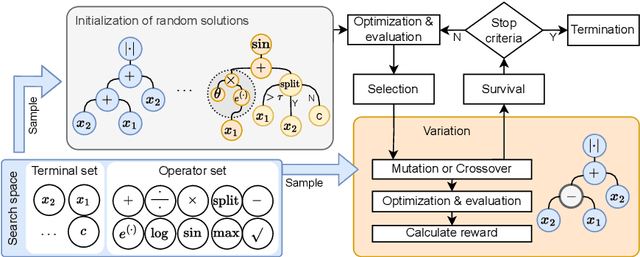


Medical decision-making makes frequent use of algorithms that combine risk equations with rules, providing clear and standardized treatment pathways. Symbolic regression (SR) traditionally limits its search space to continuous function forms and their parameters, making it difficult to model this decision-making. However, due to its ability to derive data-driven, interpretable models, SR holds promise for developing data-driven clinical risk scores. To that end we introduce Brush, an SR algorithm that combines decision-tree-like splitting algorithms with non-linear constant optimization, allowing for seamless integration of rule-based logic into symbolic regression and classification models. Brush achieves Pareto-optimal performance on SRBench, and was applied to recapitulate two widely used clinical scoring systems, achieving high accuracy and interpretable models. Compared to decision trees, random forests, and other SR methods, Brush achieves comparable or superior predictive performance while producing simpler models.
Improving Genetic Programming for Symbolic Regression with Equality Graphs
Jan 29, 2025



The search for symbolic regression models with genetic programming (GP) has a tendency of revisiting expressions in their original or equivalent forms. Repeatedly evaluating equivalent expressions is inefficient, as it does not immediately lead to better solutions. However, evolutionary algorithms require diversity and should allow the accumulation of inactive building blocks that can play an important role at a later point. The equality graph is a data structure capable of compactly storing expressions and their equivalent forms allowing an efficient verification of whether an expression has been visited in any of their stored equivalent forms. We exploit the e-graph to adapt the subtree operators to reduce the chances of revisiting expressions. Our adaptation, called eggp, stores every visited expression in the e-graph, allowing us to filter out from the available selection of subtrees all the combinations that would create already visited expressions. Results show that, for small expressions, this approach improves the performance of a simple GP algorithm to compete with PySR and Operon without increasing computational cost. As a highlight, eggp was capable of reliably delivering short and at the same time accurate models for a selected set of benchmarks from SRBench and a set of real-world datasets.
rEGGression: an Interactive and Agnostic Tool for the Exploration of Symbolic Regression Models
Jan 29, 2025Regression analysis is used for prediction and to understand the effect of independent variables on dependent variables. Symbolic regression (SR) automates the search for non-linear regression models, delivering a set of hypotheses that balances accuracy with the possibility to understand the phenomena. Many SR implementations return a Pareto front allowing the choice of the best trade-off. However, this hides alternatives that are close to non-domination, limiting these choices. Equality graphs (e-graphs) allow to represent large sets of expressions compactly by efficiently handling duplicated parts occurring in multiple expressions. E-graphs allow to store and query all SR solution candidates visited in one or multiple GP runs efficiently and open the possibility to analyse much larger sets of SR solution candidates. We introduce rEGGression, a tool using e-graphs to enable the exploration of a large set of symbolic expressions which provides querying, filtering, and pattern matching features creating an interactive experience to gain insights about SR models. The main highlight is its focus in the exploration of the building blocks found during the search that can help the experts to find insights about the studied phenomena.This is possible by exploiting the pattern matching capability of the e-graph data structure.
Alleviating Overfitting in Transformation-Interaction-Rational Symbolic Regression with Multi-Objective Optimization
Jan 03, 2025The Transformation-Interaction-Rational is a representation for symbolic regression that limits the search space of functions to the ratio of two nonlinear functions each one defined as the linear regression of transformed variables. This representation has the main objective to bias the search towards simpler expressions while keeping the approximation power of standard approaches. The performance of using Genetic Programming with this representation was substantially better than with its predecessor (Interaction-Transformation) and ranked close to the state-of-the-art on a contemporary Symbolic Regression benchmark. On a closer look at these results, we observed that the performance could be further improved with an additional selective pressure for smaller expressions when the dataset contains just a few data points. The introduction of a penalization term applied to the fitness measure improved the results on these smaller datasets. One problem with this approach is that it introduces two additional hyperparameters: i) a criteria to when the penalization should be activated and, ii) the amount of penalization to the fitness function. In this paper, we extend Transformation-Interaction-Rational to support multi-objective optimization, specifically the NSGA-II algorithm, and apply that to the same benchmark. A detailed analysis of the results show that the use of multi-objective optimization benefits the overall performance on a subset of the benchmarks while keeping the results similar to the single-objective approach on the remainder of the datasets. Specifically to the small datasets, we observe a small (and statistically insignificant) improvement of the results suggesting that further strategies must be explored.
* 25 pages, 8 figures, 4 tables, Genetic Programming and Evolvable Machines, vol 24, no 2
The Inefficiency of Genetic Programming for Symbolic Regression -- Extended Version
Apr 26, 2024
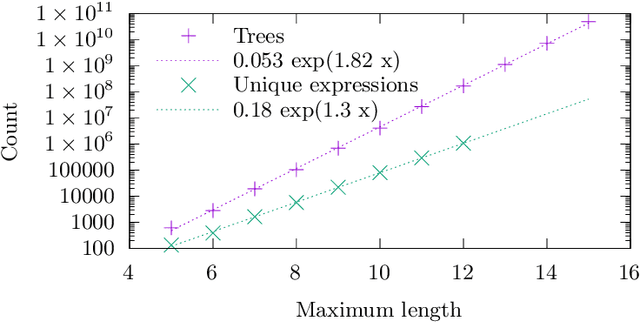

We analyse the search behaviour of genetic programming for symbolic regression in practically relevant but limited settings, allowing exhaustive enumeration of all solutions. This enables us to quantify the success probability of finding the best possible expressions, and to compare the search efficiency of genetic programming to random search in the space of semantically unique expressions. This analysis is made possible by improved algorithms for equality saturation, which we use to improve the Exhaustive Symbolic Regression algorithm; this produces the set of semantically unique expression structures, orders of magnitude smaller than the full symbolic regression search space. We compare the efficiency of random search in the set of unique expressions and genetic programming. For our experiments we use two real-world datasets where symbolic regression has been used to produce well-fitting univariate expressions: the Nikuradse dataset of flow in rough pipes and the Radial Acceleration Relation of galaxy dynamics. The results show that genetic programming in such limited settings explores only a small fraction of all unique expressions, and evaluates expressions repeatedly that are congruent to already visited expressions.
Inexact Simplification of Symbolic Regression Expressions with Locality-sensitive Hashing
Apr 08, 2024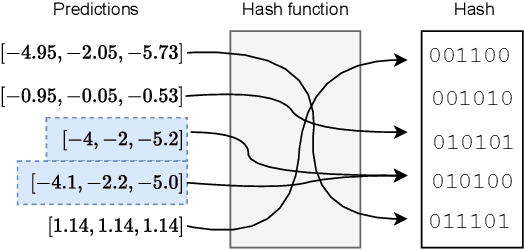

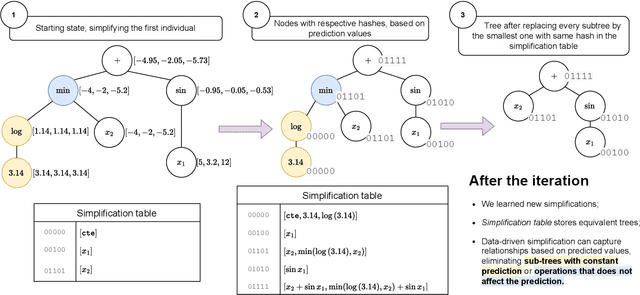
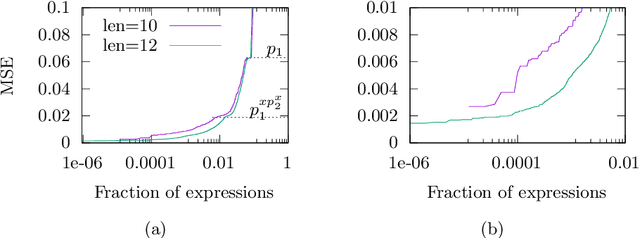
Symbolic regression (SR) searches for parametric models that accurately fit a dataset, prioritizing simplicity and interpretability. Despite this secondary objective, studies point out that the models are often overly complex due to redundant operations, introns, and bloat that arise during the iterative process, and can hinder the search with repeated exploration of bloated segments. Applying a fast heuristic algebraic simplification may not fully simplify the expression and exact methods can be infeasible depending on size or complexity of the expressions. We propose a novel agnostic simplification and bloat control for SR employing an efficient memoization with locality-sensitive hashing (LHS). The idea is that expressions and their sub-expressions traversed during the iterative simplification process are stored in a dictionary using LHS, enabling efficient retrieval of similar structures. We iterate through the expression, replacing subtrees with others of same hash if they result in a smaller expression. Empirical results shows that applying this simplification during evolution performs equal or better than without simplification in minimization of error, significantly reducing the number of nonlinear functions. This technique can learn simplification rules that work in general or for a specific problem, and improves convergence while reducing model complexity.
* 9 pages, 10 figures, accepted to GECCO-24
Minimum variance threshold for epsilon-lexicase selection
Apr 08, 2024Parent selection plays an important role in evolutionary algorithms, and many strategies exist to select the parent pool before breeding the next generation. Methods often rely on average error over the entire dataset as a criterion to select the parents, which can lead to an information loss due to aggregation of all test cases. Under epsilon-lexicase selection, the population goes to a selection pool that is iteratively reduced by using each test individually, discarding individuals with an error higher than the elite error plus the median absolute deviation (MAD) of errors for that particular test case. In an attempt to better capture differences in performance of individuals on cases, we propose a new criteria that splits errors into two partitions that minimize the total variance within partitions. Our method was embedded into the FEAT symbolic regression algorithm, and evaluated with the SRBench framework, containing 122 black-box synthetic and real-world regression problems. The empirical results show a better performance of our approach compared to traditional epsilon-lexicase selection in the real-world datasets while showing equivalent performance on the synthetic dataset.
* 9 pages, 13 figures, accepted in Genetic and Evolutionary Computation Conference (GECCO '24)
Interpretability in Symbolic Regression: a benchmark of Explanatory Methods using the Feynman data set
Apr 08, 2024In some situations, the interpretability of the machine learning models plays a role as important as the model accuracy. Interpretability comes from the need to trust the prediction model, verify some of its properties, or even enforce them to improve fairness. Many model-agnostic explanatory methods exists to provide explanations for black-box models. In the regression task, the practitioner can use white-boxes or gray-boxes models to achieve more interpretable results, which is the case of symbolic regression. When using an explanatory method, and since interpretability lacks a rigorous definition, there is a need to evaluate and compare the quality and different explainers. This paper proposes a benchmark scheme to evaluate explanatory methods to explain regression models, mainly symbolic regression models. Experiments were performed using 100 physics equations with different interpretable and non-interpretable regression methods and popular explanation methods, evaluating the performance of the explainers performance with several explanation measures. In addition, we further analyzed four benchmarks from the GP community. The results have shown that Symbolic Regression models can be an interesting alternative to white-box and black-box models that is capable of returning accurate models with appropriate explanations. Regarding the explainers, we observed that Partial Effects and SHAP were the most robust explanation models, with Integrated Gradients being unstable only with tree-based models. This benchmark is publicly available for further experiments.
* 47 pages, 10 figures. This is a post peer-review, pre-copyedit version of an article published in Genetic Programming and Evolvable Machines Volume 23, pages 309-349, (2022). The final version is available on https://link.springer.com/article/10.1007/s10710-022-09435-x