 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards symbolic regression for interpretable clinical decision scores
Dec 08, 2025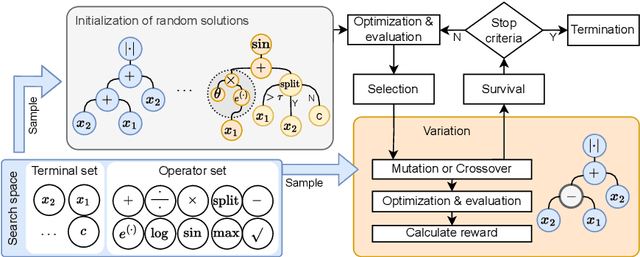

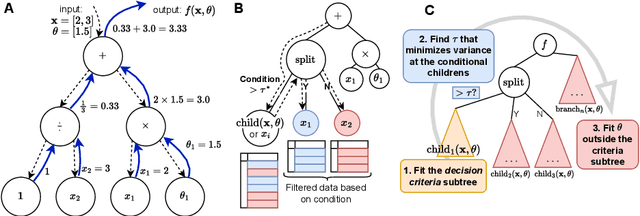

Medical decision-making makes frequent use of algorithms that combine risk equations with rules, providing clear and standardized treatment pathways. Symbolic regression (SR) traditionally limits its search space to continuous function forms and their parameters, making it difficult to model this decision-making. However, due to its ability to derive data-driven, interpretable models, SR holds promise for developing data-driven clinical risk scores. To that end we introduce Brush, an SR algorithm that combines decision-tree-like splitting algorithms with non-linear constant optimization, allowing for seamless integration of rule-based logic into symbolic regression and classification models. Brush achieves Pareto-optimal performance on SRBench, and was applied to recapitulate two widely used clinical scoring systems, achieving high accuracy and interpretable models. Compared to decision trees, random forests, and other SR methods, Brush achieves comparable or superior predictive performance while producing simpler models.
Iterative Learning of Computable Phenotypes for Treatment Resistant Hypertension using Large Language Models
Aug 07, 2025Large language models (LLMs) have demonstrated remarkable capabilities for medical question answering and programming, but their potential for generating interpretable computable phenotypes (CPs) is under-explored. In this work, we investigate whether LLMs can generate accurate and concise CPs for six clinical phenotypes of varying complexity, which could be leveraged to enable scalable clinical decision support to improve care for patients with hypertension. In addition to evaluating zero-short performance, we propose and test a synthesize, execute, debug, instruct strategy that uses LLMs to generate and iteratively refine CPs using data-driven feedback. Our results show that LLMs, coupled with iterative learning, can generate interpretable and reasonably accurate programs that approach the performance of state-of-the-art ML methods while requiring significantly fewer training examples.
Minimum variance threshold for epsilon-lexicase selection
Apr 08, 2024Parent selection plays an important role in evolutionary algorithms, and many strategies exist to select the parent pool before breeding the next generation. Methods often rely on average error over the entire dataset as a criterion to select the parents, which can lead to an information loss due to aggregation of all test cases. Under epsilon-lexicase selection, the population goes to a selection pool that is iteratively reduced by using each test individually, discarding individuals with an error higher than the elite error plus the median absolute deviation (MAD) of errors for that particular test case. In an attempt to better capture differences in performance of individuals on cases, we propose a new criteria that splits errors into two partitions that minimize the total variance within partitions. Our method was embedded into the FEAT symbolic regression algorithm, and evaluated with the SRBench framework, containing 122 black-box synthetic and real-world regression problems. The empirical results show a better performance of our approach compared to traditional epsilon-lexicase selection in the real-world datasets while showing equivalent performance on the synthetic dataset.
* 9 pages, 13 figures, accepted in Genetic and Evolutionary Computation Conference (GECCO '24)
Inexact Simplification of Symbolic Regression Expressions with Locality-sensitive Hashing
Apr 08, 2024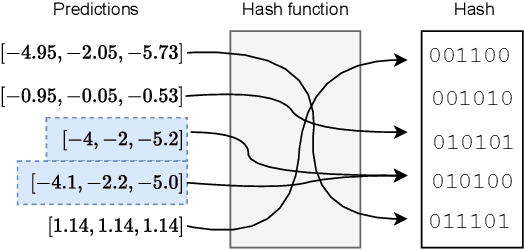

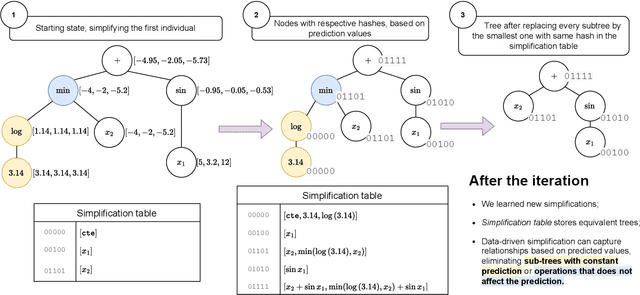
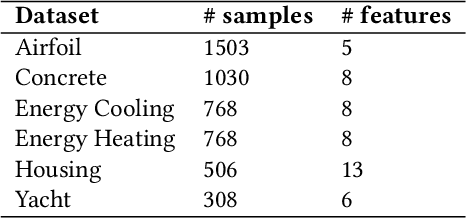
Symbolic regression (SR) searches for parametric models that accurately fit a dataset, prioritizing simplicity and interpretability. Despite this secondary objective, studies point out that the models are often overly complex due to redundant operations, introns, and bloat that arise during the iterative process, and can hinder the search with repeated exploration of bloated segments. Applying a fast heuristic algebraic simplification may not fully simplify the expression and exact methods can be infeasible depending on size or complexity of the expressions. We propose a novel agnostic simplification and bloat control for SR employing an efficient memoization with locality-sensitive hashing (LHS). The idea is that expressions and their sub-expressions traversed during the iterative simplification process are stored in a dictionary using LHS, enabling efficient retrieval of similar structures. We iterate through the expression, replacing subtrees with others of same hash if they result in a smaller expression. Empirical results shows that applying this simplification during evolution performs equal or better than without simplification in minimization of error, significantly reducing the number of nonlinear functions. This technique can learn simplification rules that work in general or for a specific problem, and improves convergence while reducing model complexity.
* 9 pages, 10 figures, accepted to GECCO-24
Interpretability in Symbolic Regression: a benchmark of Explanatory Methods using the Feynman data set
Apr 08, 2024In some situations, the interpretability of the machine learning models plays a role as important as the model accuracy. Interpretability comes from the need to trust the prediction model, verify some of its properties, or even enforce them to improve fairness. Many model-agnostic explanatory methods exists to provide explanations for black-box models. In the regression task, the practitioner can use white-boxes or gray-boxes models to achieve more interpretable results, which is the case of symbolic regression. When using an explanatory method, and since interpretability lacks a rigorous definition, there is a need to evaluate and compare the quality and different explainers. This paper proposes a benchmark scheme to evaluate explanatory methods to explain regression models, mainly symbolic regression models. Experiments were performed using 100 physics equations with different interpretable and non-interpretable regression methods and popular explanation methods, evaluating the performance of the explainers performance with several explanation measures. In addition, we further analyzed four benchmarks from the GP community. The results have shown that Symbolic Regression models can be an interesting alternative to white-box and black-box models that is capable of returning accurate models with appropriate explanations. Regarding the explainers, we observed that Partial Effects and SHAP were the most robust explanation models, with Integrated Gradients being unstable only with tree-based models. This benchmark is publicly available for further experiments.
* 47 pages, 10 figures. This is a post peer-review, pre-copyedit version of an article published in Genetic Programming and Evolvable Machines Volume 23, pages 309-349, (2022). The final version is available on https://link.springer.com/article/10.1007/s10710-022-09435-x
Interaction-Transformation Evolutionary Algorithm for Symbolic Regression
Feb 11, 2019



The Interaction-Transformation (IT) is a new representation for Symbolic Regression that restricts the search space into simpler, but expressive, function forms. This representation has the advantage of creating a smoother search space unlike the space generated by Expression Trees, the common representation used in Genetic Programming. This paper introduces an Evolutionary Algorithm capable of evolving a population of IT expressions supported only by the mutation operator. The results show that this representation is capable of finding better approximations to real-world data sets when compared to traditional approaches and a state-of-the-art Genetic Programming algorithm.