 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuiding Multi-Objective Genetic Programming with Description Length Improves Symbolic Regression Solutions
May 21, 2026Symbolic regression with genetic programming (GPSR) may suffer from overfitting and structural bloat, especially when noise is present. In this paper we evaluate description length (DL) and fractional Bayes factor (FBF) criteria as principled, data-efficient alternatives to heuristics for selecting compact expressions that generalise well. We implement DL using a Fisher-information-based parameter encoding and compare it to AIC and BIC across multiple datasets, including noisy synthetic benchmarks and real-world regression problems. We study three search/selection strategies: (i) multi-objective search for accuracy and program length followed by DL/FBF selection; (ii) multi-objective search using DL directly as an objective; and (iii) single-objective optimisation with DL/FBF as the fitness. Across datasets we find that DL/FBF post-selection improves test performance compared to AIC/BIC baseline and that BIC in combination with the same function complexity penalty from DL/FBF produces similar results. In contrast, using DL/FBF directly as a fitness function in single-objective GPSR frequently induces premature convergence to overly simple models. We conclude with practical guidance for using DL/FBF as robust model-selection tools in genetic programming workflows.
Introduction to Symbolic Regression in the Physical Sciences
Dec 17, 2025Symbolic regression (SR) has emerged as a powerful method for uncovering interpretable mathematical relationships from data, offering a novel route to both scientific discovery and efficient empirical modelling. This article introduces the Special Issue on Symbolic Regression for the Physical Sciences, motivated by the Royal Society discussion meeting held in April 2025. The contributions collected here span applications from automated equation discovery and emergent-phenomena modelling to the construction of compact emulators for computationally expensive simulations. The introductory review outlines the conceptual foundations of SR, contrasts it with conventional regression approaches, and surveys its main use cases in the physical sciences, including the derivation of effective theories, empirical functional forms and surrogate models. We summarise methodological considerations such as search-space design, operator selection, complexity control, feature selection, and integration with modern AI approaches. We also highlight ongoing challenges, including scalability, robustness to noise, overfitting and computational complexity. Finally we emphasise emerging directions, particularly the incorporation of symmetry constraints, asymptotic behaviour and other theoretical information. Taken together, the papers in this Special Issue illustrate the accelerating progress of SR and its growing relevance across the physical sciences.
(Exhaustive) Symbolic Regression and model selection by minimum description length
Jul 17, 2025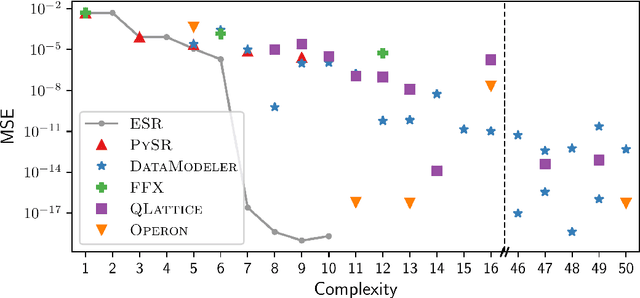
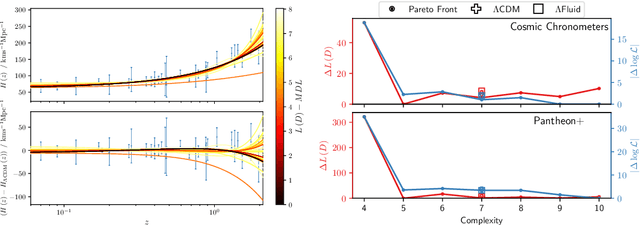
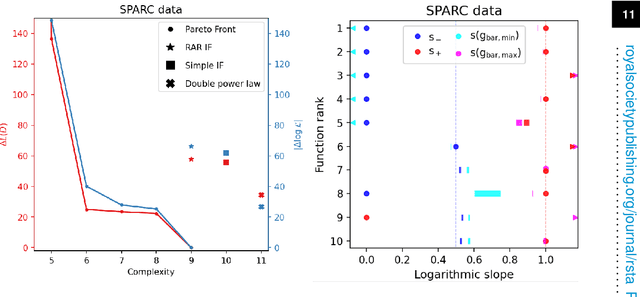
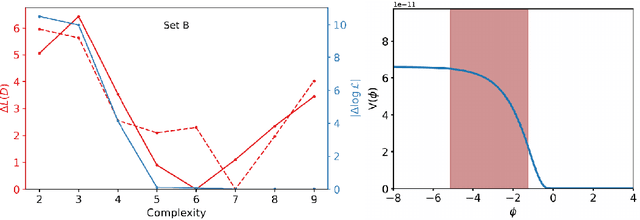
Symbolic regression is the machine learning method for learning functions from data. After a brief overview of the symbolic regression landscape, I will describe the two main challenges that traditional algorithms face: they have an unknown (and likely significant) probability of failing to find any given good function, and they suffer from ambiguity and poorly-justified assumptions in their function-selection procedure. To address these I propose an exhaustive search and model selection by the minimum description length principle, which allows accuracy and complexity to be directly traded off by measuring each in units of information. I showcase the resulting publicly available Exhaustive Symbolic Regression algorithm on three open problems in astrophysics: the expansion history of the universe, the effective behaviour of gravity in galaxies and the potential of the inflaton field. In each case the algorithm identifies many functions superior to the literature standards. This general purpose methodology should find widespread utility in science and beyond.
syren-baryon: Analytic emulators for the impact of baryons on the matter power spectrum
Jun 10, 2025Baryonic physics has a considerable impact on the distribution of matter in our Universe on scales probed by current and future cosmological surveys, acting as a key systematic in such analyses. We seek simple symbolic parametrisations for the impact of baryonic physics on the matter power spectrum for a range of physically motivated models, as a function of wavenumber, redshift, cosmology, and parameters controlling the baryonic feedback. We use symbolic regression to construct analytic approximations for the ratio of the matter power spectrum in the presence of baryons to that without such effects. We obtain separate functions of each of four distinct sub-grid prescriptions of baryonic physics from the CAMELS suite of hydrodynamical simulations (Astrid, IllustrisTNG, SIMBA and Swift-EAGLE) as well as for a baryonification algorithm. We also provide functions which describe the uncertainty on these predictions, due to both the stochastic nature of baryonic physics and the errors on our fits. The error on our approximations to the hydrodynamical simulations is comparable to the sample variance estimated through varying initial conditions, and our baryonification expression has a root mean squared error of better than one percent, although this increases on small scales. These errors are comparable to those of previous numerical emulators for these models. Our expressions are enforced to have the physically correct behaviour on large scales and at high redshift. Due to their analytic form, we are able to directly interpret the impact of varying cosmology and feedback parameters, and we can identify parameters which have little to no effect. Each function is based on a different implementation of baryonic physics, and can therefore be used to discriminate between these models when applied to real data. We provide publicly available code for all symbolic approximations found.
syren-new: Precise formulae for the linear and nonlinear matter power spectra with massive neutrinos and dynamical dark energy
Oct 18, 2024



Current and future large scale structure surveys aim to constrain the neutrino mass and the equation of state of dark energy. We aim to construct accurate and interpretable symbolic approximations to the linear and nonlinear matter power spectra as a function of cosmological parameters in extended $\Lambda$CDM models which contain massive neutrinos and non-constant equations of state for dark energy. This constitutes an extension of the syren-halofit emulators to incorporate these two effects, which we call syren-new (SYmbolic-Regression-ENhanced power spectrum emulator with NEutrinos and $W_0-w_a$). We also obtain a simple approximation to the derived parameter $\sigma_8$ as a function of the cosmological parameters for these models. Our results for the linear power spectrum are designed to emulate CLASS, whereas for the nonlinear case we aim to match the results of EuclidEmulator2. We compare our results to existing emulators and $N$-body simulations. Our analytic emulators for $\sigma_8$, the linear and nonlinear power spectra achieve root mean squared errors of 0.1%, 0.3% and 1.3%, respectively, across a wide range of cosmological parameters, redshifts and wavenumbers. We verify that emulator-related discrepancies are subdominant compared to observational errors and other modelling uncertainties when computing shear power spectra for LSST-like surveys. Our expressions have similar accuracy to existing (numerical) emulators, but are at least an order of magnitude faster, both on a CPU and GPU. Our work greatly improves the accuracy, speed and range of applicability of current symbolic approximations to the linear and nonlinear matter power spectra. We provide publicly available code for all symbolic approximations found.
Statistical Patterns in the Equations of Physics and the Emergence of a Meta-Law of Nature
Aug 12, 2024Physics, as a fundamental science, aims to understand the laws of Nature and describe them in mathematical equations. While the physical reality manifests itself in a wide range of phenomena with varying levels of complexity, the equations that describe them display certain statistical regularities and patterns, which we begin to explore here. By drawing inspiration from linguistics, where Zipf's law states that the frequency of any word in a large corpus of text is roughly inversely proportional to its rank in the frequency table, we investigate whether similar patterns for the distribution of operators emerge in the equations of physics. We analyse three corpora of formulae and find, using sophisticated implicit-likelihood methods, that the frequency of operators as a function of their rank in the frequency table is best described by an exponential law with a stable exponent, in contrast with Zipf's inverse power-law. Understanding the underlying reasons behind this statistical pattern may shed light on Nature's modus operandi or reveal recurrent patterns in physicists' attempts to formalise the laws of Nature. It may also provide crucial input for symbolic regression, potentially augmenting language models to generate symbolic models for physical phenomena. By pioneering the study of statistical regularities in the equations of physics, our results open the door for a meta-law of Nature, a (probabilistic) law that all physical laws obey.
The Inefficiency of Genetic Programming for Symbolic Regression -- Extended Version
Apr 26, 2024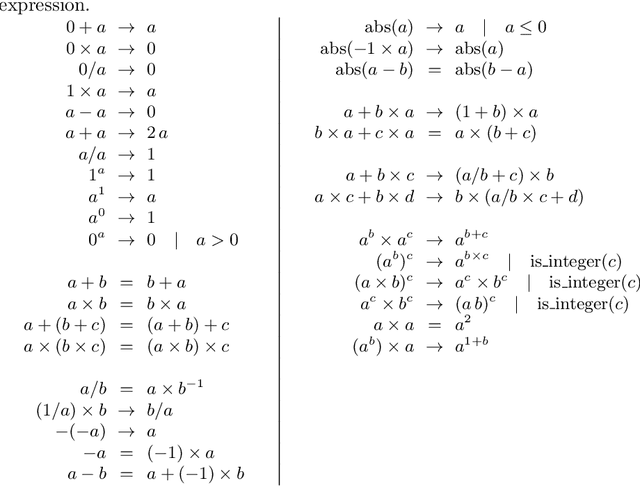
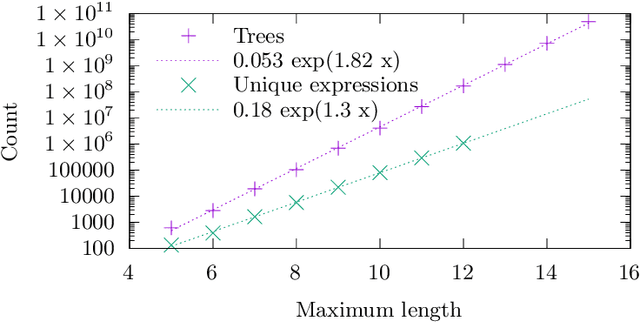

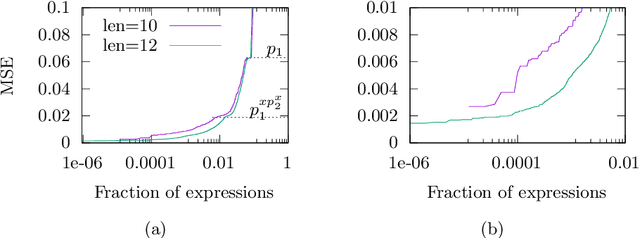
We analyse the search behaviour of genetic programming for symbolic regression in practically relevant but limited settings, allowing exhaustive enumeration of all solutions. This enables us to quantify the success probability of finding the best possible expressions, and to compare the search efficiency of genetic programming to random search in the space of semantically unique expressions. This analysis is made possible by improved algorithms for equality saturation, which we use to improve the Exhaustive Symbolic Regression algorithm; this produces the set of semantically unique expression structures, orders of magnitude smaller than the full symbolic regression search space. We compare the efficiency of random search in the set of unique expressions and genetic programming. For our experiments we use two real-world datasets where symbolic regression has been used to produce well-fitting univariate expressions: the Nikuradse dataset of flow in rough pipes and the Radial Acceleration Relation of galaxy dynamics. The results show that genetic programming in such limited settings explores only a small fraction of all unique expressions, and evaluates expressions repeatedly that are congruent to already visited expressions.
syren-halofit: A fast, interpretable, high-precision formula for the $Λ$CDM nonlinear matter power spectrum
Feb 27, 2024Rapid and accurate evaluation of the nonlinear matter power spectrum, $P(k)$, as a function of cosmological parameters and redshift is of fundamental importance in cosmology. Analytic approximations provide an interpretable solution, yet current approximations are neither fast nor accurate relative to black-box numerical emulators. We use symbolic regression to obtain simple analytic approximations to the nonlinear scale, $k_\sigma$, the effective spectral index, $n_{\rm eff}$, and the curvature, $C$, which are required for the halofit model. We then re-optimise the coefficients of halofit to fit a wide range of cosmologies and redshifts. We then again exploit symbolic regression to explore the space of analytic expressions to fit the residuals between $P(k)$ and the optimised predictions of halofit. All methods are validated against $N$-body simulations. Our symbolic expressions for $k_\sigma$, $n_{\rm eff}$ and $C$ have root mean squared fractional errors of 0.8%, 0.2% and 0.3%, respectively, for redshifts below 3 and a wide range of cosmologies. The re-optimised halofit parameters reduce the root mean squared fractional error from 3% to below 2% for wavenumbers $k=9\times10^{-3}-9 \, h{\rm Mpc^{-1}}$. We introduce syren-halofit (symbolic-regression-enhanced halofit), an extension to halofit containing a short symbolic correction which improves this error to 1%. Our method is 2350 and 3170 times faster than current halofit and hmcode implementations, respectively, and 2680 and 64 times faster than EuclidEmulator2 (which requires running class) and the BACCO emulator. We obtain comparable accuracy to EuclidEmulator2 and the BACCO emulator when tested on $N$-body simulations. Our work greatly increases the speed and accuracy of symbolic approximations to $P(k)$, making them significantly faster than their numerical counterparts without loss of accuracy.
A precise symbolic emulator of the linear matter power spectrum
Nov 27, 2023



Computing the matter power spectrum, $P(k)$, as a function of cosmological parameters can be prohibitively slow in cosmological analyses, hence emulating this calculation is desirable. Previous analytic approximations are insufficiently accurate for modern applications, so black-box, uninterpretable emulators are often used. We utilise an efficient genetic programming based symbolic regression framework to explore the space of potential mathematical expressions which can approximate the power spectrum and $\sigma_8$. We learn the ratio between an existing low-accuracy fitting function for $P(k)$ and that obtained by solving the Boltzmann equations and thus still incorporate the physics which motivated this earlier approximation. We obtain an analytic approximation to the linear power spectrum with a root mean squared fractional error of 0.2% between $k = 9\times10^{-3} - 9 \, h{\rm \, Mpc^{-1}}$ and across a wide range of cosmological parameters, and we provide physical interpretations for various terms in the expression. We also provide a simple analytic approximation for $\sigma_8$ with a similar accuracy, with a root mean squared fractional error of just 0.4% when evaluated across the same range of cosmologies. This function is easily invertible to obtain $A_{\rm s}$ as a function of $\sigma_8$ and the other cosmological parameters, if preferred. It is possible to obtain symbolic approximations to a seemingly complex function at a precision required for current and future cosmological analyses without resorting to deep-learning techniques, thus avoiding their black-box nature and large number of parameters. Our emulator will be usable long after the codes on which numerical approximations are built become outdated.
The Simplest Inflationary Potentials
Oct 25, 2023



Inflation is a highly favoured theory for the early Universe. It is compatible with current observations of the cosmic microwave background and large scale structure and is a driver in the quest to detect primordial gravitational waves. It is also, given the current quality of the data, highly under-determined with a large number of candidate implementations. We use a new method in symbolic regression to generate all possible simple scalar field potentials for one of two possible basis sets of operators. Treating these as single-field, slow-roll inflationary models we then score them with an information-theoretic metric ("minimum description length") that quantifies their efficiency in compressing the information in the Planck data. We explore two possible priors on the parameter space of potentials, one related to the functions' structural complexity and one that uses a Katz back-off language model to prefer functions that may be theoretically motivated. This enables us to identify the inflaton potentials that optimally balance simplicity with accuracy at explaining the Planck data, which may subsequently find theoretical motivation. Our exploratory study opens the door to extraction of fundamental physics directly from data, and may be augmented with more refined theoretical priors in the quest for a complete understanding of the early Universe.