 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Algorithmic Approach for Causal Health Equity: A Look at Race Differentials in Intensive Care Unit (ICU) Outcomes
Jan 09, 2025
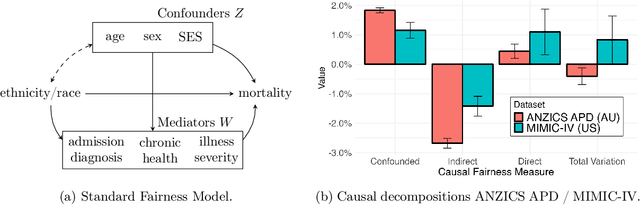
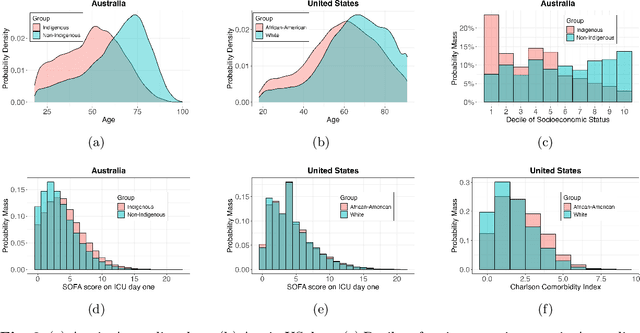

The new era of large-scale data collection and analysis presents an opportunity for diagnosing and understanding the causes of health inequities. In this study, we describe a framework for systematically analyzing health disparities using causal inference. The framework is illustrated by investigating racial and ethnic disparities in intensive care unit (ICU) outcome between majority and minority groups in Australia (Indigenous vs. Non-Indigenous) and the United States (African-American vs. White). We demonstrate that commonly used statistical measures for quantifying inequity are insufficient, and focus on attributing the observed disparity to the causal mechanisms that generate it. We find that minority patients are younger at admission, have worse chronic health, are more likely to be admitted for urgent and non-elective reasons, and have higher illness severity. At the same time, however, we find a protective direct effect of belonging to a minority group, with minority patients showing improved survival compared to their majority counterparts, with all other variables kept equal. We demonstrate that this protective effect is related to the increased probability of being admitted to ICU, with minority patients having an increased risk of ICU admission. We also find that minority patients, while showing improved survival, are more likely to be readmitted to ICU. Thus, due to worse access to primary health care, minority patients are more likely to end up in ICU for preventable conditions, causing a reduction in the mortality rates and creating an effect that appears to be protective. Since the baseline risk of ICU admission may serve as proxy for lack of access to primary care, we developed the Indigenous Intensive Care Equity (IICE) Radar, a monitoring system for tracking the over-utilization of ICU resources by the Indigenous population of Australia across geographical areas.
Cross-Care: Assessing the Healthcare Implications of Pre-training Data on Language Model Bias
May 09, 2024



Large language models (LLMs) are increasingly essential in processing natural languages, yet their application is frequently compromised by biases and inaccuracies originating in their training data. In this study, we introduce Cross-Care, the first benchmark framework dedicated to assessing biases and real world knowledge in LLMs, specifically focusing on the representation of disease prevalence across diverse demographic groups. We systematically evaluate how demographic biases embedded in pre-training corpora like $ThePile$ influence the outputs of LLMs. We expose and quantify discrepancies by juxtaposing these biases against actual disease prevalences in various U.S. demographic groups. Our results highlight substantial misalignment between LLM representation of disease prevalence and real disease prevalence rates across demographic subgroups, indicating a pronounced risk of bias propagation and a lack of real-world grounding for medical applications of LLMs. Furthermore, we observe that various alignment methods minimally resolve inconsistencies in the models' representation of disease prevalence across different languages. For further exploration and analysis, we make all data and a data visualization tool available at: www.crosscare.net.