 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCall for Action: towards the next generation of symbolic regression benchmark
May 06, 2025


Symbolic Regression (SR) is a powerful technique for discovering interpretable mathematical expressions. However, benchmarking SR methods remains challenging due to the diversity of algorithms, datasets, and evaluation criteria. In this work, we present an updated version of SRBench. Our benchmark expands the previous one by nearly doubling the number of evaluated methods, refining evaluation metrics, and using improved visualizations of the results to understand the performances. Additionally, we analyze trade-offs between model complexity, accuracy, and energy consumption. Our results show that no single algorithm dominates across all datasets. We propose a call for action from SR community in maintaining and evolving SRBench as a living benchmark that reflects the state-of-the-art in symbolic regression, by standardizing hyperparameter tuning, execution constraints, and computational resource allocation. We also propose deprecation criteria to maintain the benchmark's relevance and discuss best practices for improving SR algorithms, such as adaptive hyperparameter tuning and energy-efficient implementations.
Multi-View Symbolic Regression
Feb 16, 2024



Symbolic regression (SR) searches for analytical expressions representing the relationship between a set of explanatory and response variables. Current SR methods assume a single dataset extracted from a single experiment. Nevertheless, frequently, the researcher is confronted with multiple sets of results obtained from experiments conducted with different setups. Traditional SR methods may fail to find the underlying expression since the parameters of each experiment can be different. In this work we present Multi-View Symbolic Regression (MvSR), which takes into account multiple datasets simultaneously, mimicking experimental environments, and outputs a general parametric solution. This approach fits the evaluated expression to each independent dataset and returns a parametric family of functions f(x; \theta) simultaneously capable of accurately fitting all datasets. We demonstrate the effectiveness of MvSR using data generated from known expressions, as well as real-world data from astronomy, chemistry and economy, for which an a priori analytical expression is not available. Results show that MvSR obtains the correct expression more frequently and is robust to hyperparameters change. In real-world data, it is able to grasp the group behaviour, recovering known expressions from the literature as well as promising alternatives, thus enabling the use SR to a large range of experimental scenarios.
HOTGP -- Higher-Order Typed Genetic Programming
Apr 06, 2023
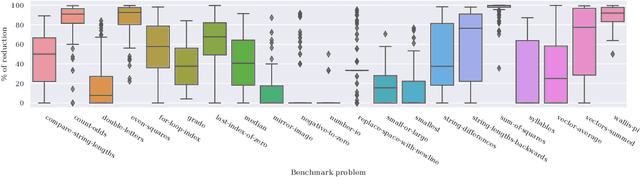
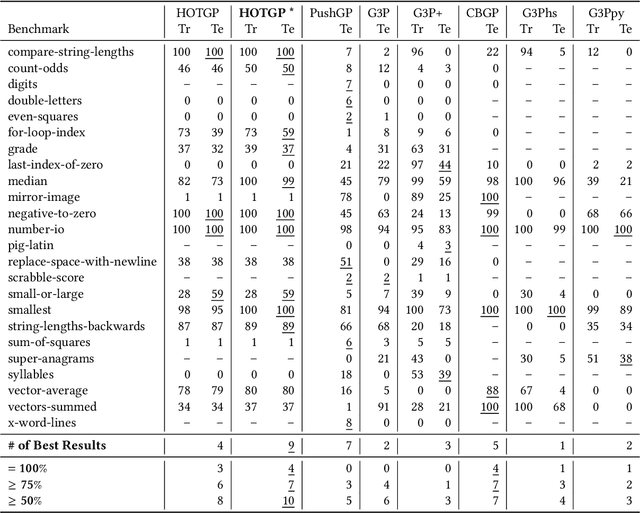
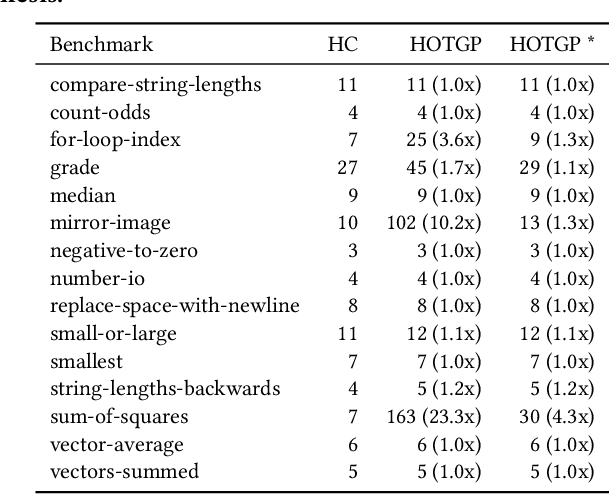
Program synthesis is the process of generating a computer program following a set of specifications, which can be a high-level description of the problem and/or a set of input-output examples. The synthesis can be modeled as a search problem in which the search space is the set of all the programs valid under a grammar. As the search space is vast, brute force is usually not viable and search heuristics, such as genetic programming, also have difficulty navigating it without any guidance. In this paper we present HOTGP, a new genetic programming algorithm that synthesizes pure, typed, and functional programs. HOTGP leverages the knowledge provided by the rich data-types associated with the specification and the built-in grammar to constrain the search space and improve the performance of the synthesis. The grammar is based on Haskell's standard base library (the synthesized code can be directly compiled using any standard Haskell compiler) and includes support for higher-order functions, $\lambda$-functions, and parametric polymorphism. Experimental results show that, when compared to $6$ state-of-the-art algorithms using a standard set of benchmarks, HOTGP is competitive and capable of synthesizing the correct programs more frequently than any other of the evaluated algorithms.
Contemporary Symbolic Regression Methods and their Relative Performance
Jul 29, 2021



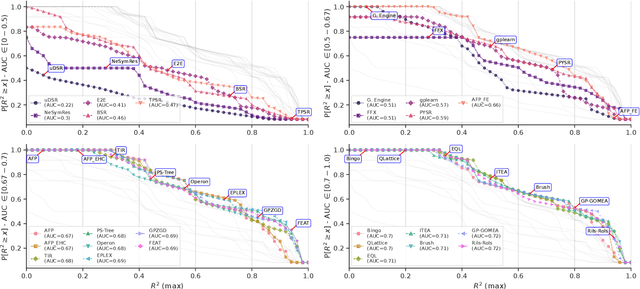
Many promising approaches to symbolic regression have been presented in recent years, yet progress in the field continues to suffer from a lack of uniform, robust, and transparent benchmarking standards. In this paper, we address this shortcoming by introducing an open-source, reproducible benchmarking platform for symbolic regression. We assess 14 symbolic regression methods and 7 machine learning methods on a set of 252 diverse regression problems. Our assessment includes both real-world datasets with no known model form as well as ground-truth benchmark problems, including physics equations and systems of ordinary differential equations. For the real-world datasets, we benchmark the ability of each method to learn models with low error and low complexity relative to state-of-the-art machine learning methods. For the synthetic problems, we assess each method's ability to find exact solutions in the presence of varying levels of noise. Under these controlled experiments, we conclude that the best performing methods for real-world regression combine genetic algorithms with parameter estimation and/or semantic search drivers. When tasked with recovering exact equations in the presence of noise, we find that deep learning and genetic algorithm-based approaches perform similarly. We provide a detailed guide to reproducing this experiment and contributing new methods, and encourage other researchers to collaborate with us on a common and living symbolic regression benchmark.
Enhanced word embeddings using multi-semantic representation through lexical chains
Jan 22, 2021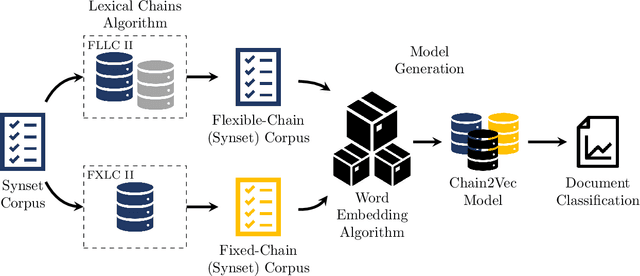

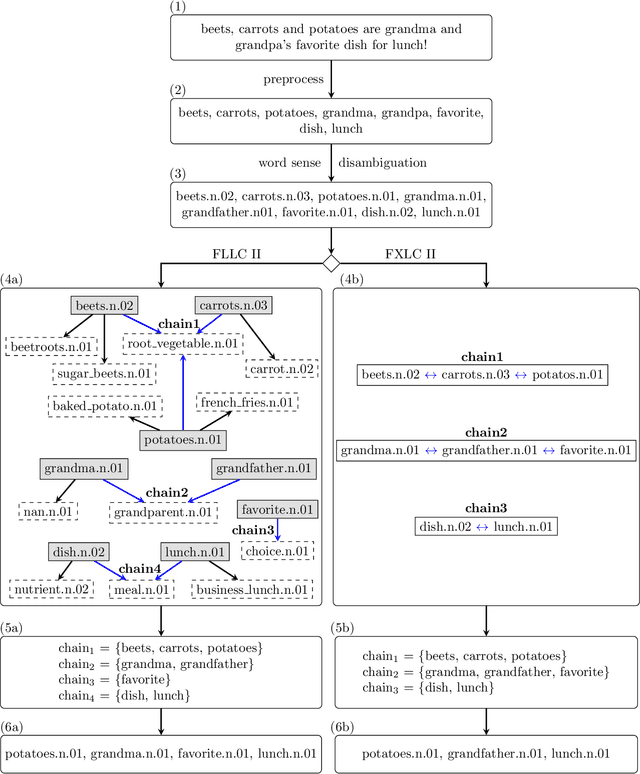

The relationship between words in a sentence often tells us more about the underlying semantic content of a document than its actual words, individually. In this work, we propose two novel algorithms, called Flexible Lexical Chain II and Fixed Lexical Chain II. These algorithms combine the semantic relations derived from lexical chains, prior knowledge from lexical databases, and the robustness of the distributional hypothesis in word embeddings as building blocks forming a single system. In short, our approach has three main contributions: (i) a set of techniques that fully integrate word embeddings and lexical chains; (ii) a more robust semantic representation that considers the latent relation between words in a document; and (iii) lightweight word embeddings models that can be extended to any natural language task. We intend to assess the knowledge of pre-trained models to evaluate their robustness in the document classification task. The proposed techniques are tested against seven word embeddings algorithms using five different machine learning classifiers over six scenarios in the document classification task. Our results show the integration between lexical chains and word embeddings representations sustain state-of-the-art results, even against more complex systems.
An electronic-game framework for evaluating coevolutionary algorithms
Apr 11, 2016



One of the common artificial intelligence applications in electronic games consists of making an artificial agent learn how to execute some determined task successfully in a game environment. One way to perform this task is through machine learning algorithms capable of learning the sequence of actions required to win in a given game environment. There are several supervised learning techniques able to learn the correct answer for a problem through examples. However, when learning how to play electronic games, the correct answer might only be known by the end of the game, after all the actions were already taken. Thus, not being possible to measure the accuracy of each individual action to be taken at each time step. A way for dealing with this problem is through Neuroevolution, a method which trains Artificial Neural Networks using evolutionary algorithms. In this article, we introduce a framework for testing optimization algorithms with artificial agent controllers in electronic games, called EvoMan, which is inspired in the action-platformer game Mega Man II. The environment can be configured to run in different experiment modes, as single evolution, coevolution and others. To demonstrate some challenges regarding the proposed platform, as initial experiments we applied Neuroevolution using Genetic Algorithms and the NEAT algorithm, in the context of competitively coevolving two distinct agents in this game.