 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhanced word embeddings using multi-semantic representation through lexical chains
Jan 22, 2021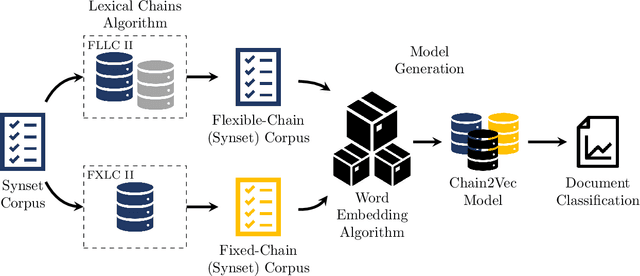

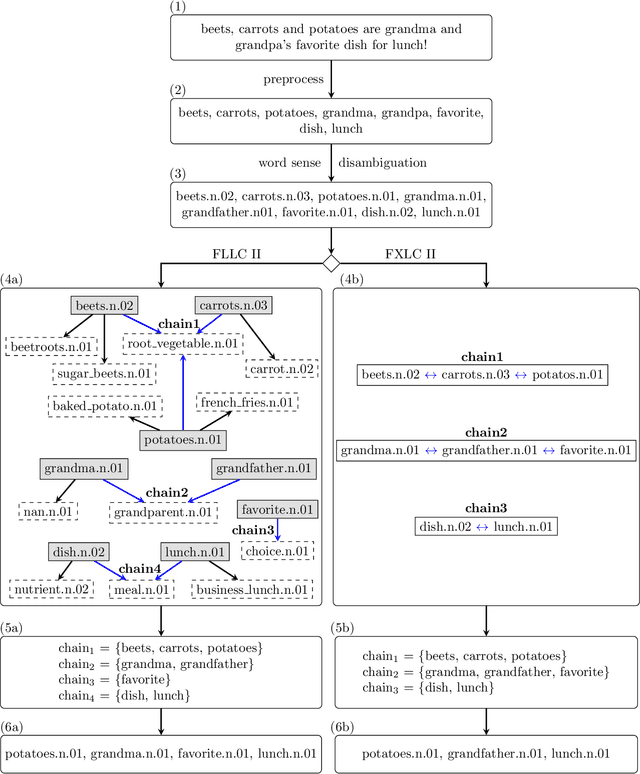

The relationship between words in a sentence often tells us more about the underlying semantic content of a document than its actual words, individually. In this work, we propose two novel algorithms, called Flexible Lexical Chain II and Fixed Lexical Chain II. These algorithms combine the semantic relations derived from lexical chains, prior knowledge from lexical databases, and the robustness of the distributional hypothesis in word embeddings as building blocks forming a single system. In short, our approach has three main contributions: (i) a set of techniques that fully integrate word embeddings and lexical chains; (ii) a more robust semantic representation that considers the latent relation between words in a document; and (iii) lightweight word embeddings models that can be extended to any natural language task. We intend to assess the knowledge of pre-trained models to evaluate their robustness in the document classification task. The proposed techniques are tested against seven word embeddings algorithms using five different machine learning classifiers over six scenarios in the document classification task. Our results show the integration between lexical chains and word embeddings representations sustain state-of-the-art results, even against more complex systems.