 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBRIGHTER: BRIdging the Gap in Human-Annotated Textual Emotion Recognition Datasets for 28 Languages
Feb 17, 2025



People worldwide use language in subtle and complex ways to express emotions. While emotion recognition -- an umbrella term for several NLP tasks -- significantly impacts different applications in NLP and other fields, most work in the area is focused on high-resource languages. Therefore, this has led to major disparities in research and proposed solutions, especially for low-resource languages that suffer from the lack of high-quality datasets. In this paper, we present BRIGHTER-- a collection of multilabeled emotion-annotated datasets in 28 different languages. BRIGHTER covers predominantly low-resource languages from Africa, Asia, Eastern Europe, and Latin America, with instances from various domains annotated by fluent speakers. We describe the data collection and annotation processes and the challenges of building these datasets. Then, we report different experimental results for monolingual and crosslingual multi-label emotion identification, as well as intensity-level emotion recognition. We investigate results with and without using LLMs and analyse the large variability in performance across languages and text domains. We show that BRIGHTER datasets are a step towards bridging the gap in text-based emotion recognition and discuss their impact and utility.
Enhanced word embeddings using multi-semantic representation through lexical chains
Jan 22, 2021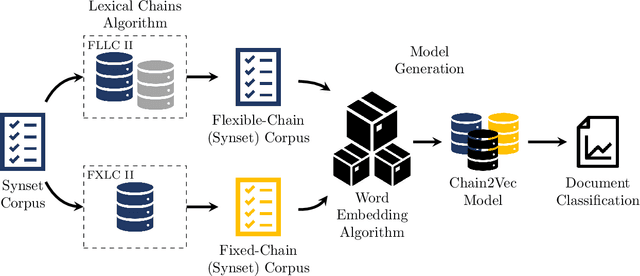

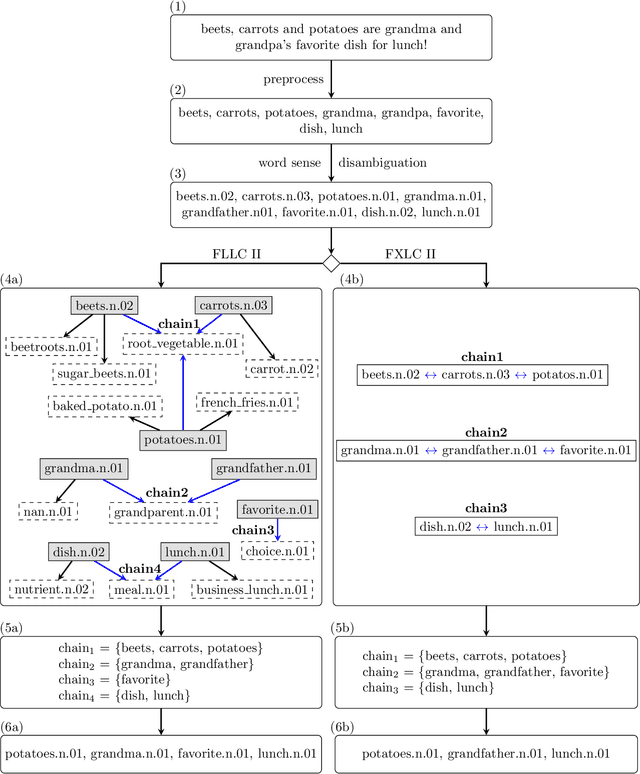

The relationship between words in a sentence often tells us more about the underlying semantic content of a document than its actual words, individually. In this work, we propose two novel algorithms, called Flexible Lexical Chain II and Fixed Lexical Chain II. These algorithms combine the semantic relations derived from lexical chains, prior knowledge from lexical databases, and the robustness of the distributional hypothesis in word embeddings as building blocks forming a single system. In short, our approach has three main contributions: (i) a set of techniques that fully integrate word embeddings and lexical chains; (ii) a more robust semantic representation that considers the latent relation between words in a document; and (iii) lightweight word embeddings models that can be extended to any natural language task. We intend to assess the knowledge of pre-trained models to evaluate their robustness in the document classification task. The proposed techniques are tested against seven word embeddings algorithms using five different machine learning classifiers over six scenarios in the document classification task. Our results show the integration between lexical chains and word embeddings representations sustain state-of-the-art results, even against more complex systems.
DCDistance: A Supervised Text Document Feature extraction based on class labels
Jan 14, 2018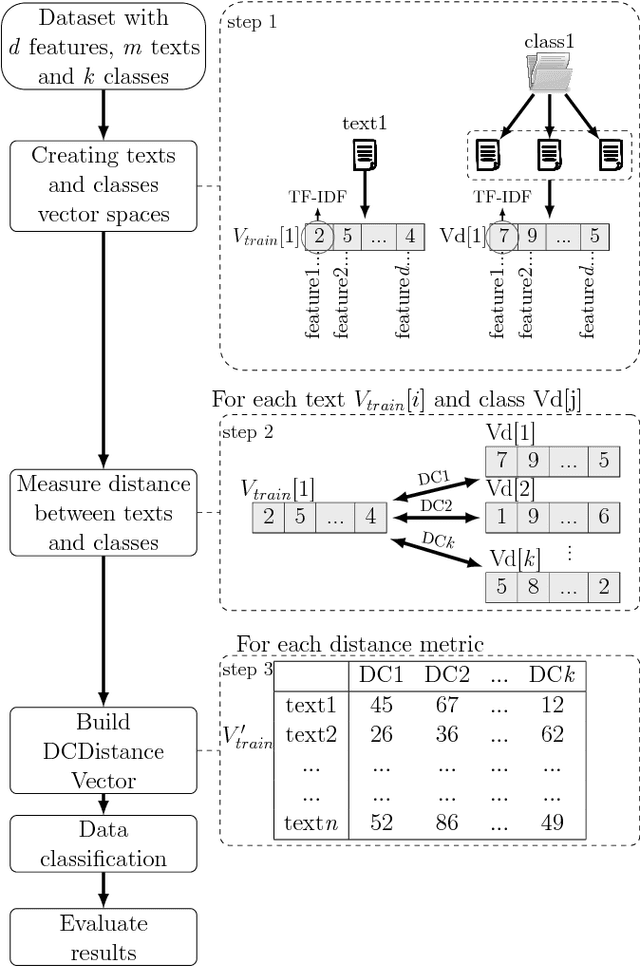
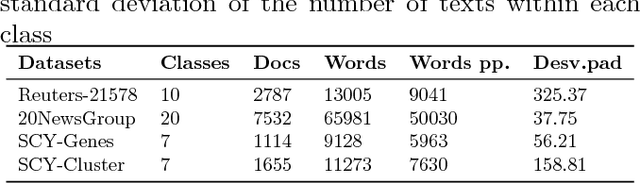
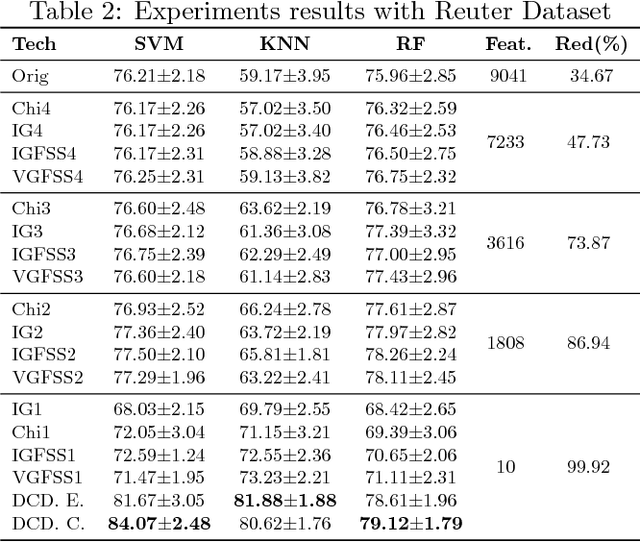

Text Mining is a field that aims at extracting information from textual data. One of the challenges of such field of study comes from the pre-processing stage in which a vector (and structured) representation should be extracted from unstructured data. The common extraction creates large and sparse vectors representing the importance of each term to a document. As such, this usually leads to the curse-of-dimensionality that plagues most machine learning algorithms. To cope with this issue, in this paper we propose a new supervised feature extraction and reduction algorithm, named DCDistance, that creates features based on the distance between a document to a representative of each class label. As such, the proposed technique can reduce the features set in more than 99% of the original set. Additionally, this algorithm was also capable of improving the classification accuracy over a set of benchmark datasets when compared to traditional and state-of-the-art features selection algorithms.