 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTinyverseGP: Towards a Modular Cross-domain Benchmarking Framework for Genetic Programming
Apr 14, 2025Over the years, genetic programming (GP) has evolved, with many proposed variations, especially in how they represent a solution. Being essentially a program synthesis algorithm, it is capable of tackling multiple problem domains. Current benchmarking initiatives are fragmented, as the different representations are not compared with each other and their performance is not measured across the different domains. In this work, we propose a unified framework, dubbed TinyverseGP (inspired by tinyGP), which provides support to multiple representations and problem domains, including symbolic regression, logic synthesis and policy search.
* Accepted for presentation as a poster at the Genetic and Evolutionary Computation Conference (GECCO) and will appear in the GECCO'25 companion. GECCO'25 will be held July 14-18, 2025 in M\'alaga, Spain
Using Shape Constraints for Improving Symbolic Regression Models
Jul 20, 2021
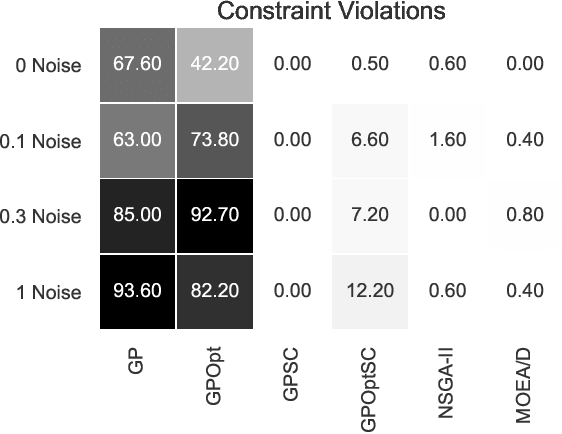
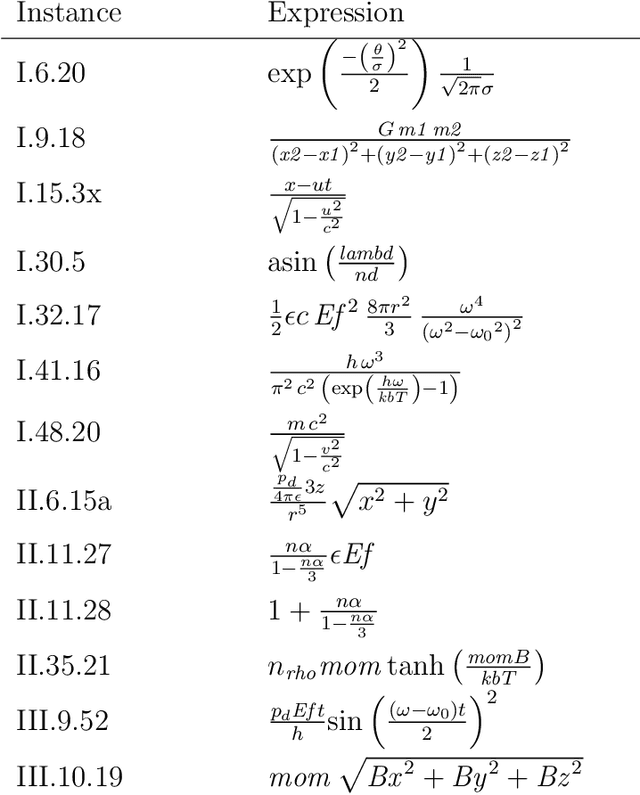
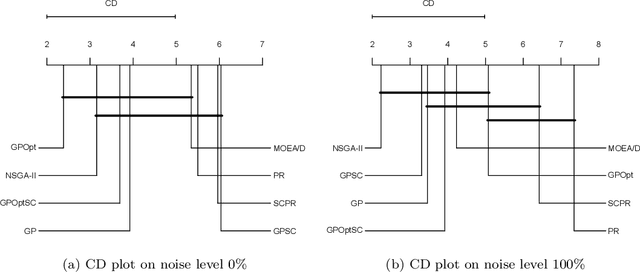
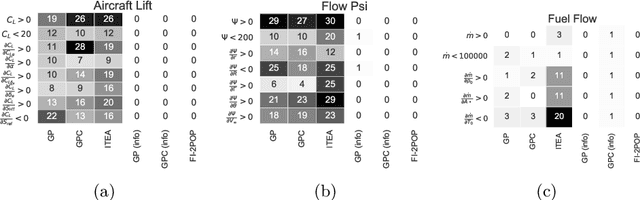
We describe and analyze algorithms for shape-constrained symbolic regression, which allows the inclusion of prior knowledge about the shape of the regression function. This is relevant in many areas of engineering -- in particular whenever a data-driven model obtained from measurements must have certain properties (e.g. positivity, monotonicity or convexity/concavity). We implement shape constraints using a soft-penalty approach which uses multi-objective algorithms to minimize constraint violations and training error. We use the non-dominated sorting genetic algorithm (NSGA-II) as well as the multi-objective evolutionary algorithm based on decomposition (MOEA/D). We use a set of models from physics textbooks to test the algorithms and compare against earlier results with single-objective algorithms. The results show that all algorithms are able to find models which conform to all shape constraints. Using shape constraints helps to improve extrapolation behavior of the models.
Shape-constrained Symbolic Regression -- Improving Extrapolation with Prior Knowledge
Mar 29, 2021
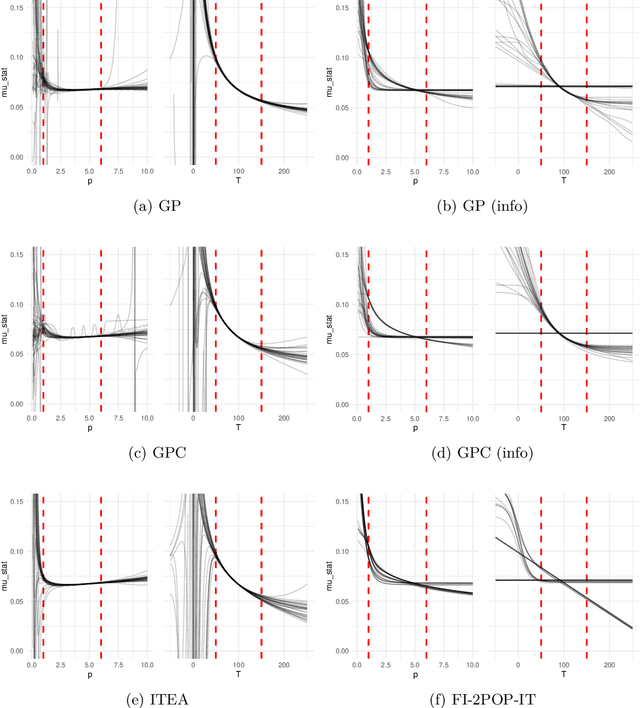
We investigate the addition of constraints on the function image and its derivatives for the incorporation of prior knowledge in symbolic regression. The approach is called shape-constrained symbolic regression and allows us to enforce e.g. monotonicity of the function over selected inputs. The aim is to find models which conform to expected behaviour and which have improved extrapolation capabilities. We demonstrate the feasibility of the idea and propose and compare two evolutionary algorithms for shape-constrained symbolic regression: i) an extension of tree-based genetic programming which discards infeasible solutions in the selection step, and ii) a two population evolutionary algorithm that separates the feasible from the infeasible solutions. In both algorithms we use interval arithmetic to approximate bounds for models and their partial derivatives. The algorithms are tested on a set of 19 synthetic and four real-world regression problems. Both algorithms are able to identify models which conform to shape constraints which is not the case for the unmodified symbolic regression algorithms. However, the predictive accuracy of models with constraints is worse on the training set and the test set. Shape-constrained polynomial regression produces the best results for the test set but also significantly larger models.
DCDistance: A Supervised Text Document Feature extraction based on class labels
Jan 14, 2018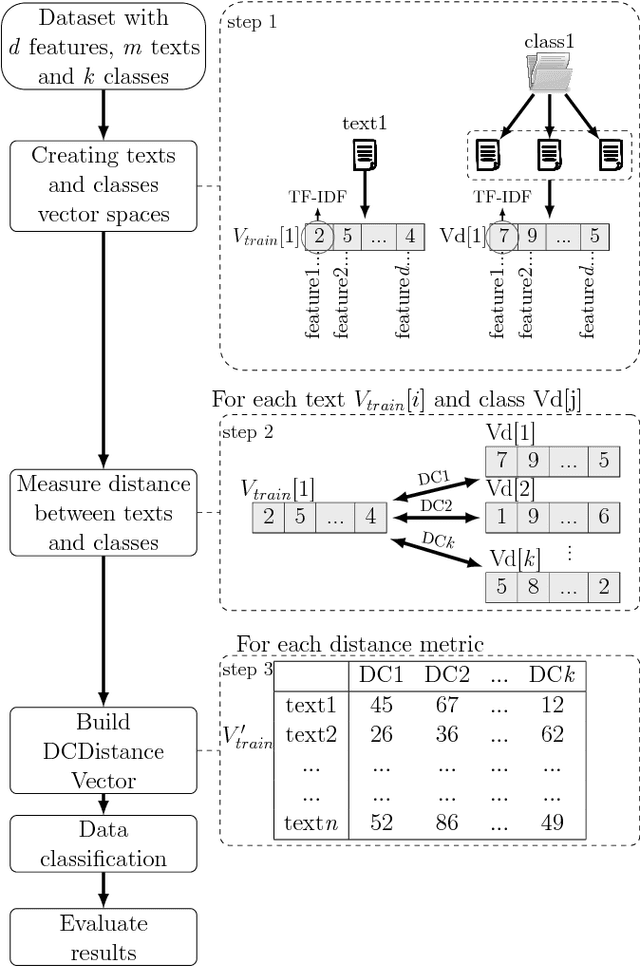
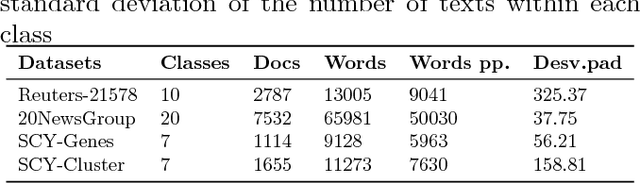
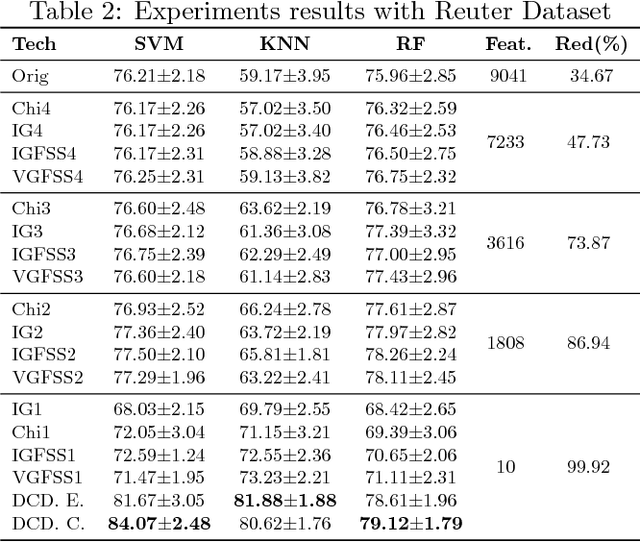

Text Mining is a field that aims at extracting information from textual data. One of the challenges of such field of study comes from the pre-processing stage in which a vector (and structured) representation should be extracted from unstructured data. The common extraction creates large and sparse vectors representing the importance of each term to a document. As such, this usually leads to the curse-of-dimensionality that plagues most machine learning algorithms. To cope with this issue, in this paper we propose a new supervised feature extraction and reduction algorithm, named DCDistance, that creates features based on the distance between a document to a representative of each class label. As such, the proposed technique can reduce the features set in more than 99% of the original set. Additionally, this algorithm was also capable of improving the classification accuracy over a set of benchmark datasets when compared to traditional and state-of-the-art features selection algorithms.
A Hash-based Co-Clustering Algorithm for Categorical Data
Jul 29, 2014
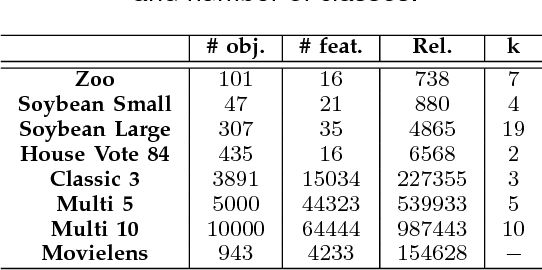
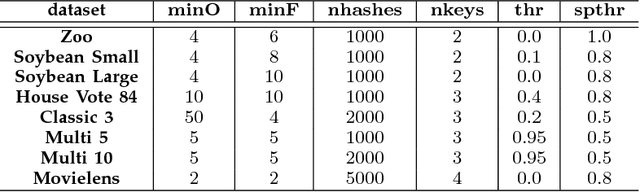
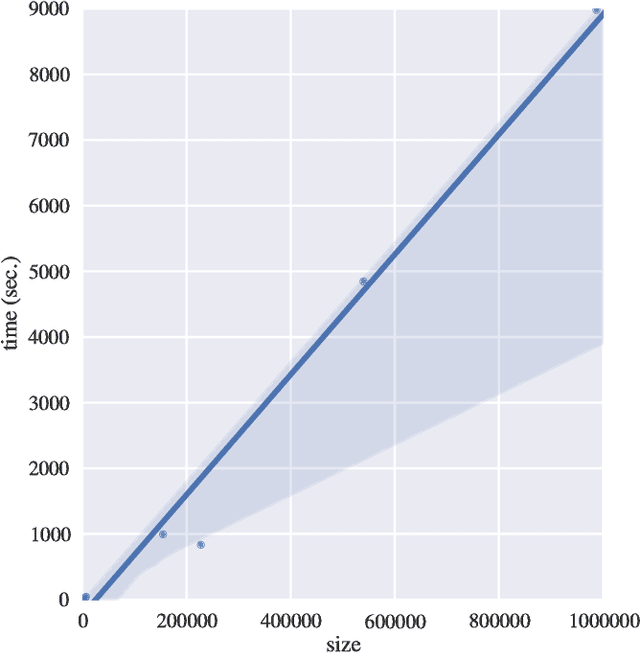
Many real-life data are described by categorical attributes without a pre-classification. A common data mining method used to extract information from this type of data is clustering. This method group together the samples from the data that are more similar than all other samples. But, categorical data pose a challenge when extracting information because: the calculation of two objects similarity is usually done by measuring the number of common features, but ignore a possible importance weighting; if the data may be divided differently according to different subsets of the features, the algorithm may find clusters with different meanings from each other, difficulting the post analysis. Data Co-Clustering of categorical data is the technique that tries to find subsets of samples that share a subset of features in common. By doing so, not only a sample may belong to more than one cluster but, the feature selection of each cluster describe its own characteristics. In this paper a novel Co-Clustering technique for categorical data is proposed by using Locality Sensitive Hashing technique in order to preprocess a list of Co-Clusters seeds based on a previous research. Results indicate this technique is capable of finding high quality Co-Clusters in many different categorical data sets and scales linearly with the data set size.