 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDCDistance: A Supervised Text Document Feature extraction based on class labels
Paper and Code
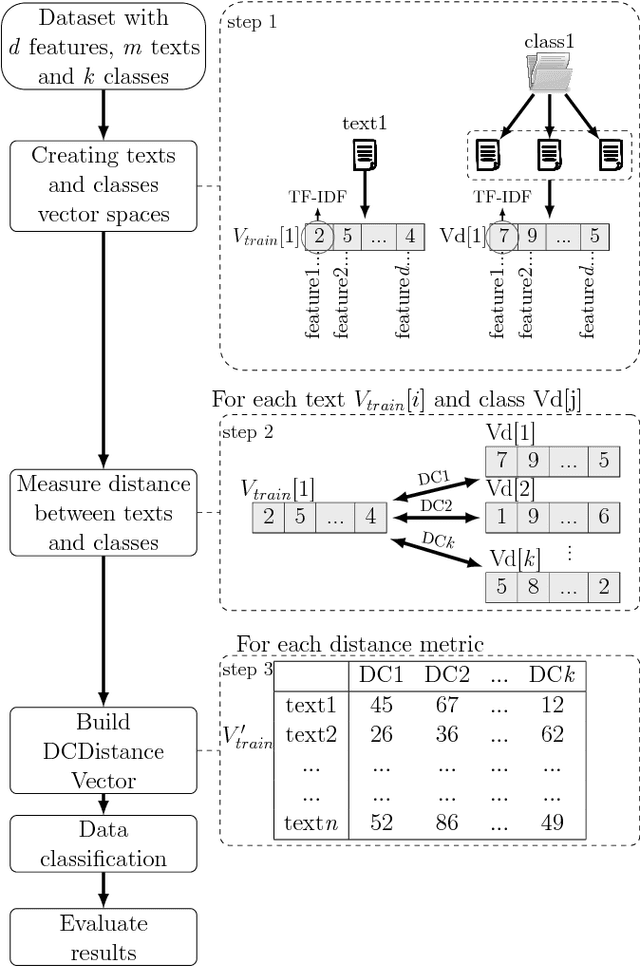
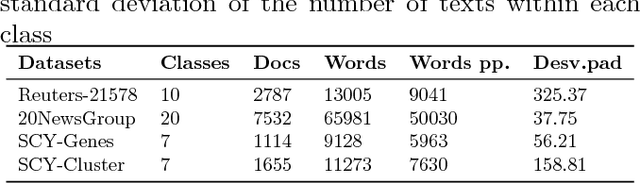
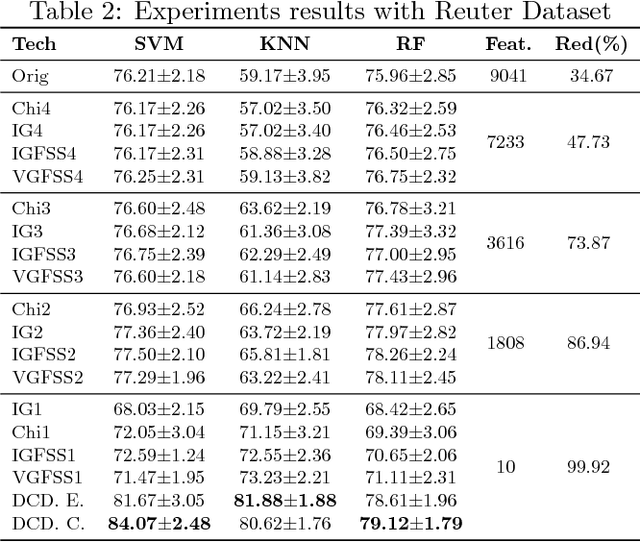

Text Mining is a field that aims at extracting information from textual data. One of the challenges of such field of study comes from the pre-processing stage in which a vector (and structured) representation should be extracted from unstructured data. The common extraction creates large and sparse vectors representing the importance of each term to a document. As such, this usually leads to the curse-of-dimensionality that plagues most machine learning algorithms. To cope with this issue, in this paper we propose a new supervised feature extraction and reduction algorithm, named DCDistance, that creates features based on the distance between a document to a representative of each class label. As such, the proposed technique can reduce the features set in more than 99% of the original set. Additionally, this algorithm was also capable of improving the classification accuracy over a set of benchmark datasets when compared to traditional and state-of-the-art features selection algorithms.