 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhanced word embeddings using multi-semantic representation through lexical chains
Jan 22, 2021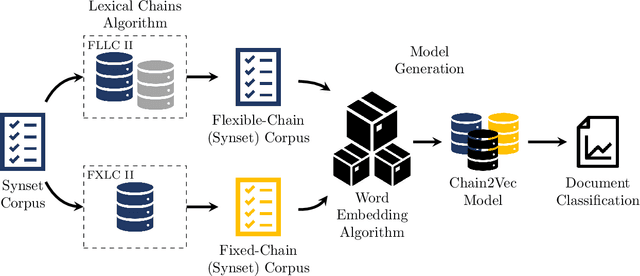

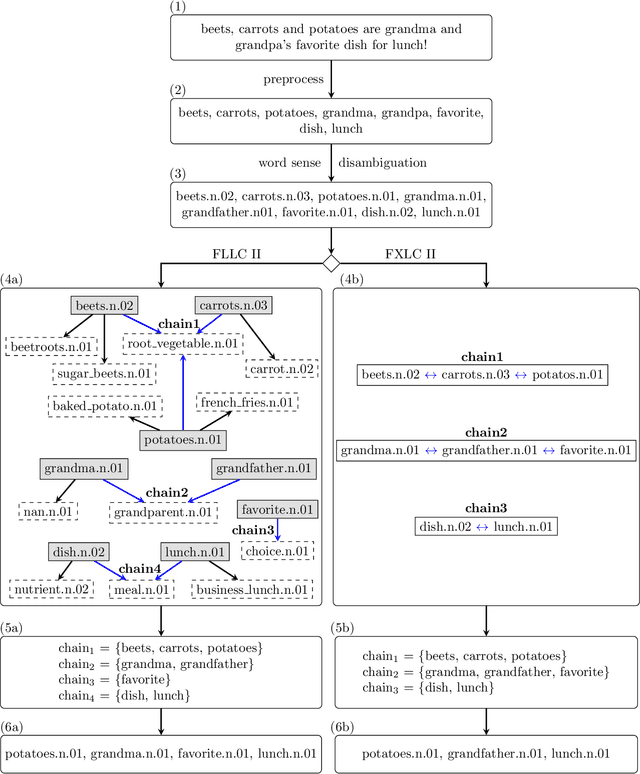

The relationship between words in a sentence often tells us more about the underlying semantic content of a document than its actual words, individually. In this work, we propose two novel algorithms, called Flexible Lexical Chain II and Fixed Lexical Chain II. These algorithms combine the semantic relations derived from lexical chains, prior knowledge from lexical databases, and the robustness of the distributional hypothesis in word embeddings as building blocks forming a single system. In short, our approach has three main contributions: (i) a set of techniques that fully integrate word embeddings and lexical chains; (ii) a more robust semantic representation that considers the latent relation between words in a document; and (iii) lightweight word embeddings models that can be extended to any natural language task. We intend to assess the knowledge of pre-trained models to evaluate their robustness in the document classification task. The proposed techniques are tested against seven word embeddings algorithms using five different machine learning classifiers over six scenarios in the document classification task. Our results show the integration between lexical chains and word embeddings representations sustain state-of-the-art results, even against more complex systems.
Multi-sense embeddings through a word sense disambiguation process
Jan 21, 2021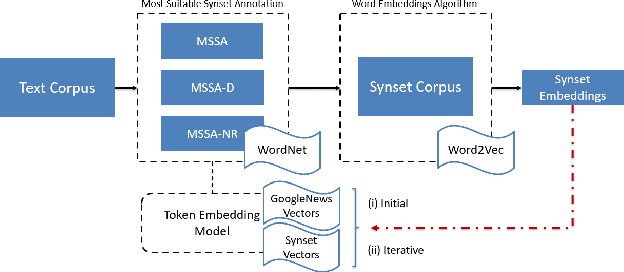
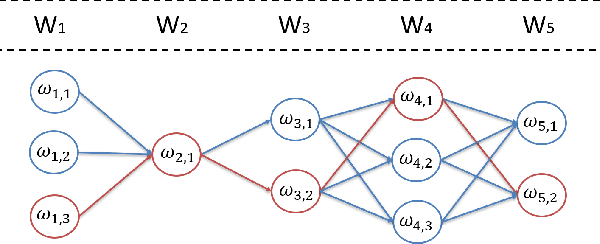
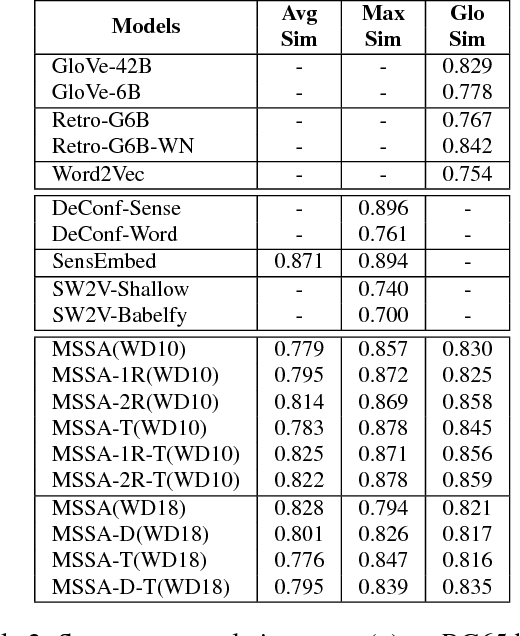
Natural Language Understanding has seen an increasing number of publications in the last few years, especially after robust word embeddings models became prominent, when they proved themselves able to capture and represent semantic relationships from massive amounts of data. Nevertheless, traditional models often fall short in intrinsic issues of linguistics, such as polysemy and homonymy. Any expert system that makes use of natural language in its core, can be affected by a weak semantic representation of text, resulting in inaccurate outcomes based on poor decisions. To mitigate such issues, we propose a novel approach called Most Suitable Sense Annotation (MSSA), that disambiguates and annotates each word by its specific sense, considering the semantic effects of its context. Our approach brings three main contributions to the semantic representation scenario: (i) an unsupervised technique that disambiguates and annotates words by their senses, (ii) a multi-sense embeddings model that can be extended to any traditional word embeddings algorithm, and (iii) a recurrent methodology that allows our models to be re-used and their representations refined. We test our approach on six different benchmarks for the word similarity task, showing that our approach can produce state-of-the-art results and outperforms several more complex state-of-the-art systems.
Why Machines Cannot Learn Mathematics, Yet
May 20, 2019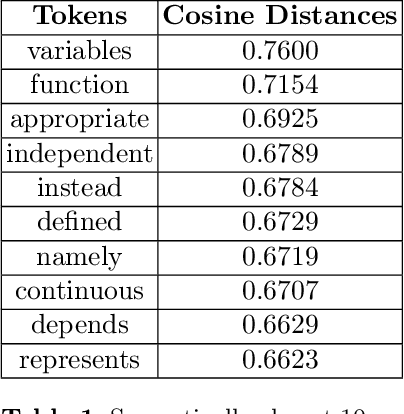

Nowadays, Machine Learning (ML) is seen as the universal solution to improve the effectiveness of information retrieval (IR) methods. However, while mathematics is a precise and accurate science, it is usually expressed by less accurate and imprecise descriptions, contributing to the relative dearth of machine learning applications for IR in this domain. Generally, mathematical documents communicate their knowledge with an ambiguous, context-dependent, and non-formal language. Given recent advances in ML, it seems canonical to apply ML techniques to represent and retrieve mathematics semantically. In this work, we apply popular text embedding techniques to the arXiv collection of STEM documents and explore how these are unable to properly understand mathematics from that corpus. In addition, we also investigate the missing aspects that would allow mathematics to be learned by computers.