 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy Machines Cannot Learn Mathematics, Yet
Paper and Code
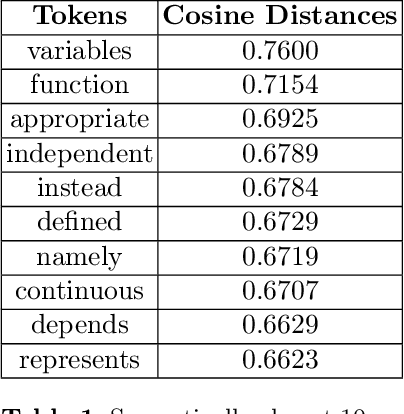

Nowadays, Machine Learning (ML) is seen as the universal solution to improve the effectiveness of information retrieval (IR) methods. However, while mathematics is a precise and accurate science, it is usually expressed by less accurate and imprecise descriptions, contributing to the relative dearth of machine learning applications for IR in this domain. Generally, mathematical documents communicate their knowledge with an ambiguous, context-dependent, and non-formal language. Given recent advances in ML, it seems canonical to apply ML techniques to represent and retrieve mathematics semantically. In this work, we apply popular text embedding techniques to the arXiv collection of STEM documents and explore how these are unable to properly understand mathematics from that corpus. In addition, we also investigate the missing aspects that would allow mathematics to be learned by computers.