 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-sense embeddings through a word sense disambiguation process
Jan 21, 2021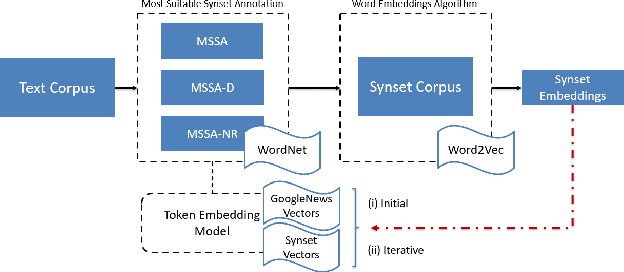
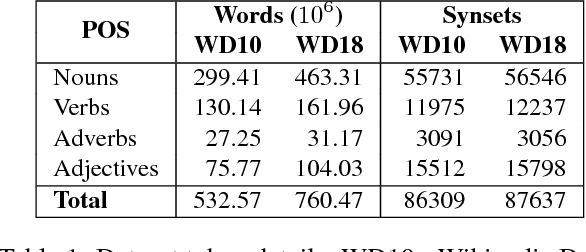
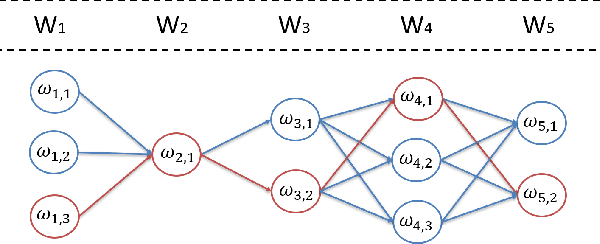
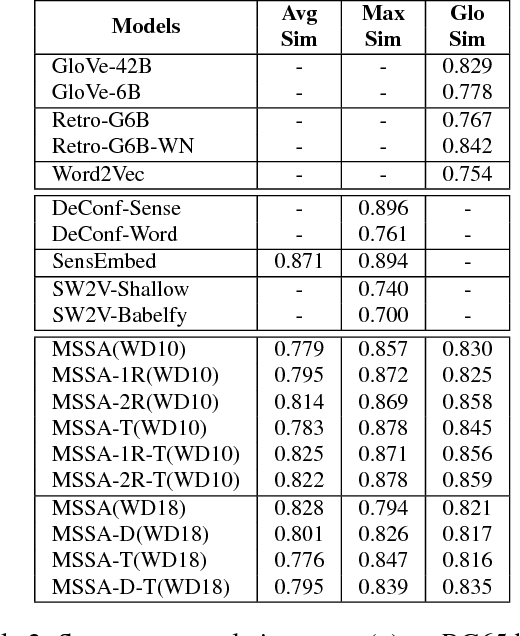
Natural Language Understanding has seen an increasing number of publications in the last few years, especially after robust word embeddings models became prominent, when they proved themselves able to capture and represent semantic relationships from massive amounts of data. Nevertheless, traditional models often fall short in intrinsic issues of linguistics, such as polysemy and homonymy. Any expert system that makes use of natural language in its core, can be affected by a weak semantic representation of text, resulting in inaccurate outcomes based on poor decisions. To mitigate such issues, we propose a novel approach called Most Suitable Sense Annotation (MSSA), that disambiguates and annotates each word by its specific sense, considering the semantic effects of its context. Our approach brings three main contributions to the semantic representation scenario: (i) an unsupervised technique that disambiguates and annotates words by their senses, (ii) a multi-sense embeddings model that can be extended to any traditional word embeddings algorithm, and (iii) a recurrent methodology that allows our models to be re-used and their representations refined. We test our approach on six different benchmarks for the word similarity task, showing that our approach can produce state-of-the-art results and outperforms several more complex state-of-the-art systems.