 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProportional Multicalibration
Sep 29, 2022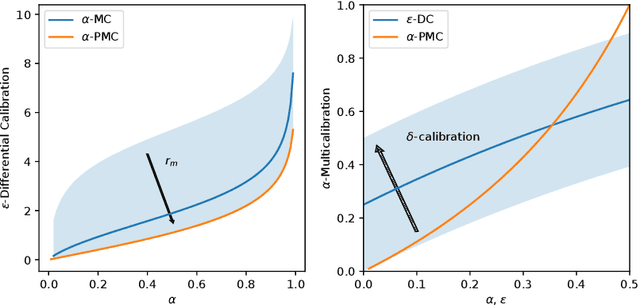

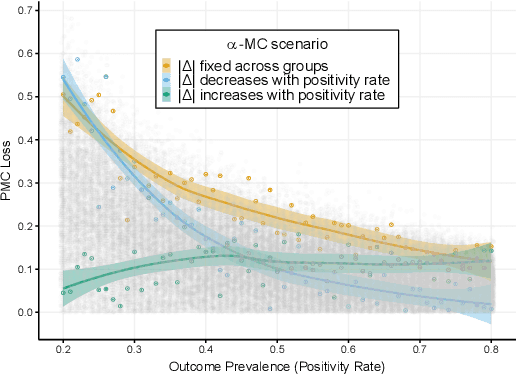
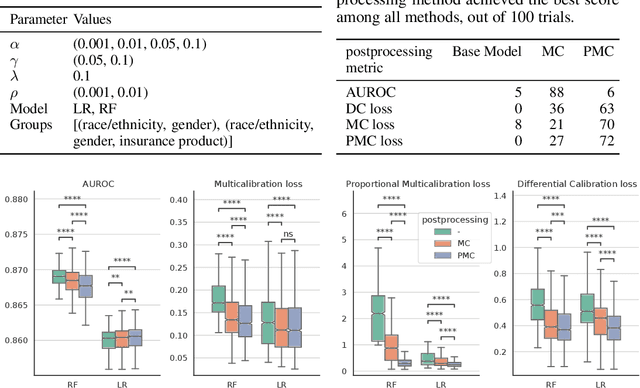
Multicalibration is a desirable fairness criteria that constrains calibration error among flexibly-defined groups in the data while maintaining overall calibration. However, when outcome probabilities are correlated with group membership, multicalibrated models can exhibit a higher percent calibration error among groups with lower base rates than groups with higher base rates. As a result, it remains possible for a decision-maker to learn to trust or distrust model predictions for specific groups. To alleviate this, we propose proportional multicalibration, a criteria that constrains the percent calibration error among groups and within prediction bins. We prove that satisfying proportional multicalibration bounds a model's multicalibration as well its differential calibration, a stronger fairness criteria inspired by the fairness notion of sufficiency. We provide an efficient algorithm for post-processing risk prediction models for proportional multicalibration and evaluate it empirically. We conduct simulation studies and investigate a real-world application of PMC-postprocessing to prediction of emergency department patient admissions. We observe that proportional multicalibration is a promising criteria for controlling simultenous measures of calibration fairness of a model over intersectional groups with virtually no cost in terms of classification performance.
Population Diversity Leads to Short Running Times of Lexicase Selection
Apr 13, 2022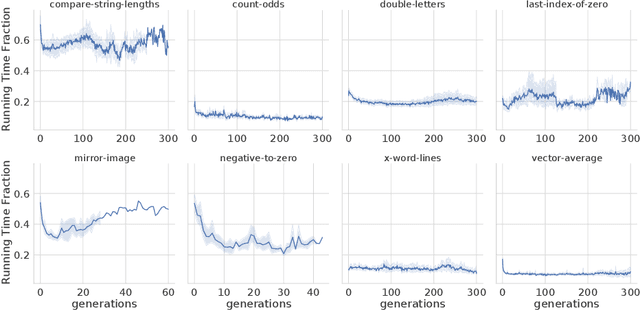
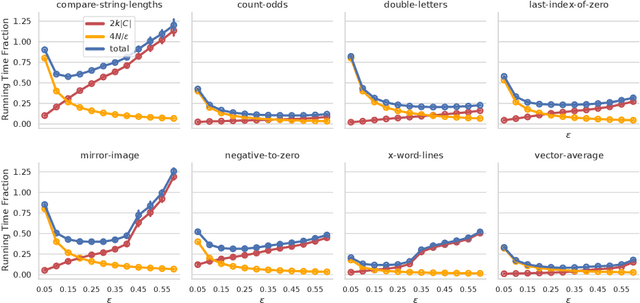
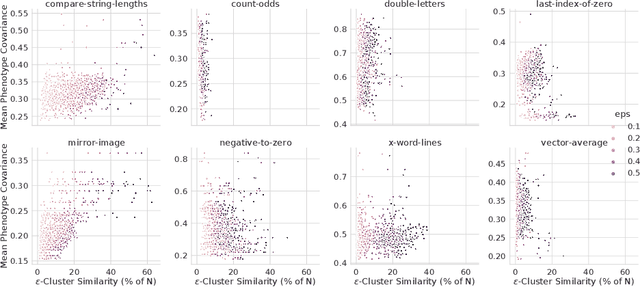
In this paper we investigate why the running time of lexicase parent selection is empirically much lower than its worst-case bound of O(N*C). We define a measure of population diversity and prove that high diversity leads to low running times O(N + C) of lexicase selection. We then show empirically that genetic programming populations evolved under lexicase selection are diverse for several program synthesis problems, and explore the resulting differences in running time bounds.
Contemporary Symbolic Regression Methods and their Relative Performance
Jul 29, 2021



Many promising approaches to symbolic regression have been presented in recent years, yet progress in the field continues to suffer from a lack of uniform, robust, and transparent benchmarking standards. In this paper, we address this shortcoming by introducing an open-source, reproducible benchmarking platform for symbolic regression. We assess 14 symbolic regression methods and 7 machine learning methods on a set of 252 diverse regression problems. Our assessment includes both real-world datasets with no known model form as well as ground-truth benchmark problems, including physics equations and systems of ordinary differential equations. For the real-world datasets, we benchmark the ability of each method to learn models with low error and low complexity relative to state-of-the-art machine learning methods. For the synthetic problems, we assess each method's ability to find exact solutions in the presence of varying levels of noise. Under these controlled experiments, we conclude that the best performing methods for real-world regression combine genetic algorithms with parameter estimation and/or semantic search drivers. When tasked with recovering exact equations in the presence of noise, we find that deep learning and genetic algorithm-based approaches perform similarly. We provide a detailed guide to reproducing this experiment and contributing new methods, and encourage other researchers to collaborate with us on a common and living symbolic regression benchmark.
PMLB v1.0: an open source dataset collection for benchmarking machine learning methods
Nov 30, 2020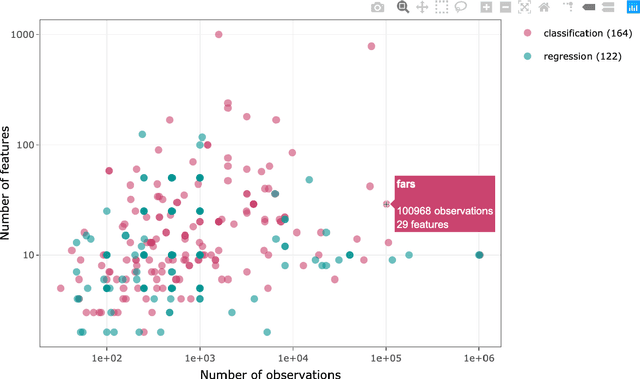

PMLB (Penn Machine Learning Benchmark) is an open-source data repository containing a curated collection of datasets for evaluating and comparing machine learning (ML) algorithms. Compiled from a broad range of existing ML benchmark collections, PMLB synthesizes and standardizes hundreds of publicly available datasets from diverse sources such as the UCI ML repository and OpenML, enabling systematic assessment of different ML methods. These datasets cover a range of applications, from binary/multi-class classification to regression problems with combinations of categorical and continuous features. PMLB has both a Python interface (pmlb) and an R interface (pmlbr), both with detailed documentation that allows the user to access cleaned and formatted datasets using a single function call. PMLB also provides a comprehensive description of each dataset and advanced functions to explore the dataset space, allowing for smoother user experience and handling of data. The resource is designed to facilitate open-source contributions in the form of datasets as well as improvements to curation.
Genetic programming approaches to learning fair classifiers
Apr 28, 2020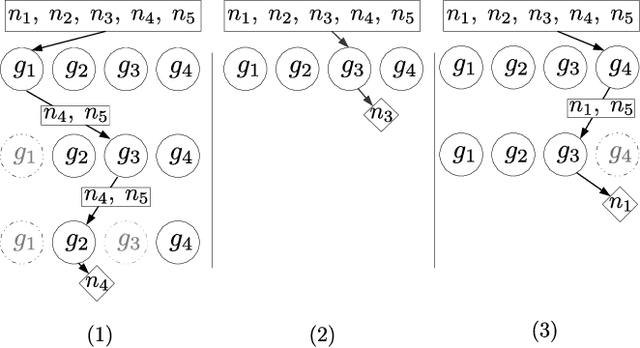


Society has come to rely on algorithms like classifiers for important decision making, giving rise to the need for ethical guarantees such as fairness. Fairness is typically defined by asking that some statistic of a classifier be approximately equal over protected groups within a population. In this paper, current approaches to fairness are discussed and used to motivate algorithmic proposals that incorporate fairness into genetic programming for classification. We propose two ideas. The first is to incorporate a fairness objective into multi-objective optimization. The second is to adapt lexicase selection to define cases dynamically over intersections of protected groups. We describe why lexicase selection is well suited to pressure models to perform well across the potentially infinitely many subgroups over which fairness is desired. We use a recent genetic programming approach to construct models on four datasets for which fairness constraints are necessary, and empirically compare performance to prior methods utilizing game-theoretic solutions. Methods are assessed based on their ability to generate trade-offs of subgroup fairness and accuracy that are Pareto optimal. The result show that genetic programming methods in general, and random search in particular, are well suited to this task.
Evaluating recommender systems for AI-driven data science
Jun 07, 2019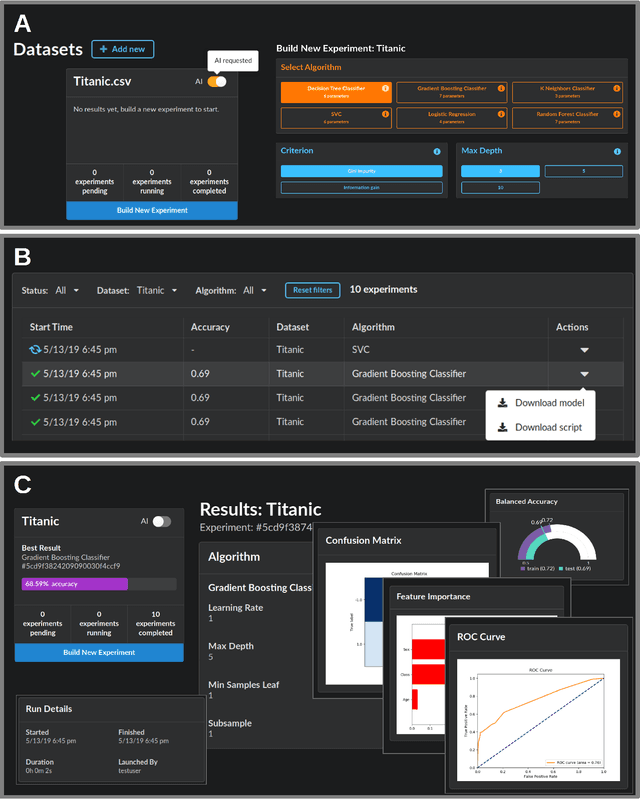
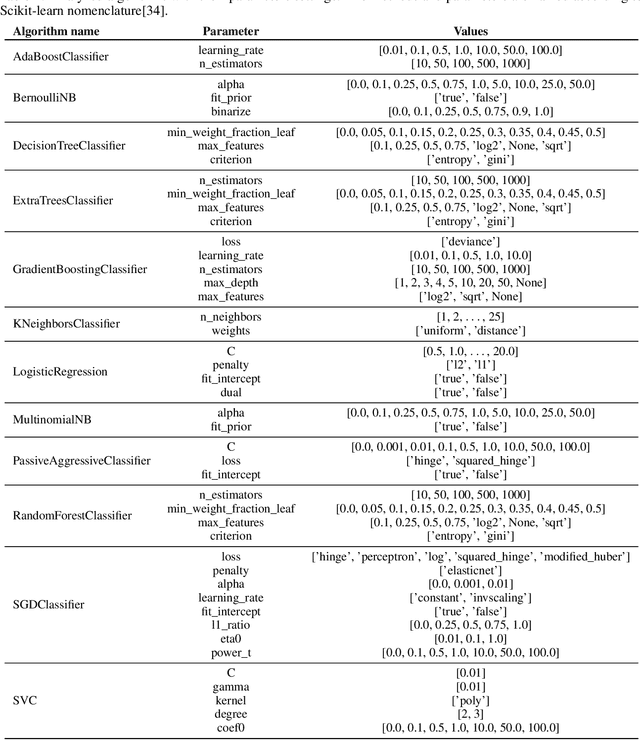
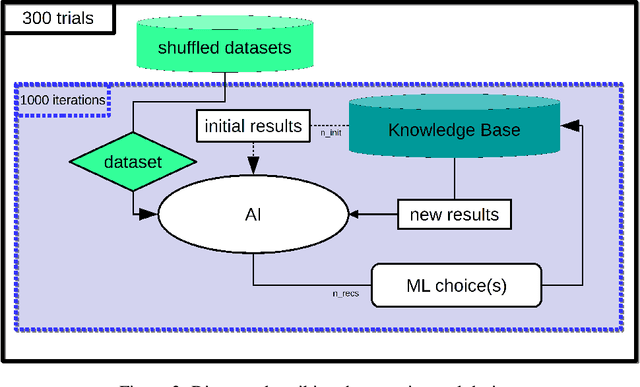
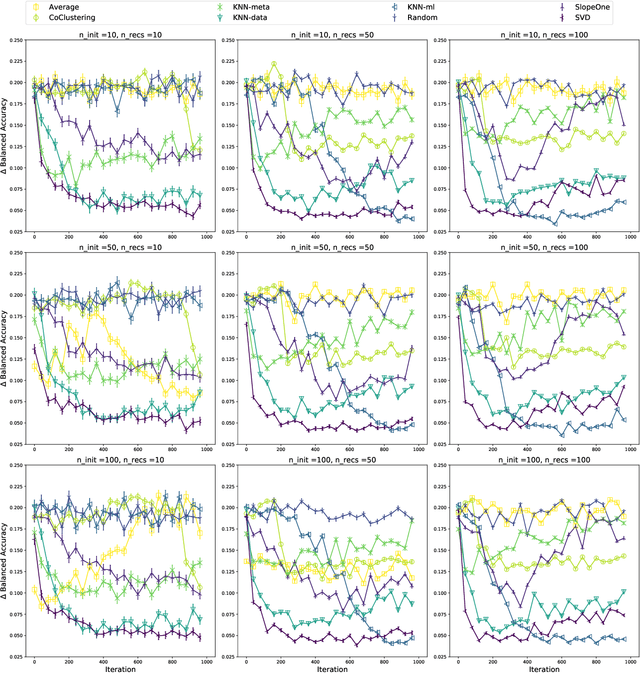
We present a free and open-source platform to allow researchers to easily apply supervised machine learning to their data. A key component of this system is a recommendation engine that is bootstrapped with machine learning results generated on a repository of open-source datasets. The recommendation system chooses which analyses to run for the user, and allows the user to view analyses, download reproducible code or fitted models, and visualize results via a web browser. The recommender system learns online as results are generated. In this paper we benchmark several recommendation strategies, including collaborative filtering and metalearning approaches, for their ability to learn to select and run optimal algorithm configurations for various datasets as results are generated. We find that a matrix factorization-based recommendation system learns to choose increasingly accurate models from few initial results.
Epsilon-Lexicase Selection for Regression
May 30, 2019



Lexicase selection is a parent selection method that considers test cases separately, rather than in aggregate, when performing parent selection. It performs well in discrete error spaces but not on the continuous-valued problems that compose most system identification tasks. In this paper, we develop a new form of lexicase selection for symbolic regression, named epsilon-lexicase selection, that redefines the pass condition for individuals on each test case in a more effective way. We run a series of experiments on real-world and synthetic problems with several treatments of epsilon and quantify how epsilon affects parent selection and model performance. epsilon-lexicase selection is shown to be effective for regression, producing better fit models compared to other techniques such as tournament selection and age-fitness Pareto optimization. We demonstrate that epsilon can be adapted automatically for individual test cases based on the population performance distribution. Our experiments show that epsilon-lexicase selection with automatic epsilon produces the most accurate models across tested problems with negligible computational overhead. We show that behavioral diversity is exceptionally high in lexicase selection treatments, and that epsilon-lexicase selection makes use of more fitness cases when selecting parents than lexicase selection, which helps explain the performance improvement.
Semantic variation operators for multidimensional genetic programming
Apr 18, 2019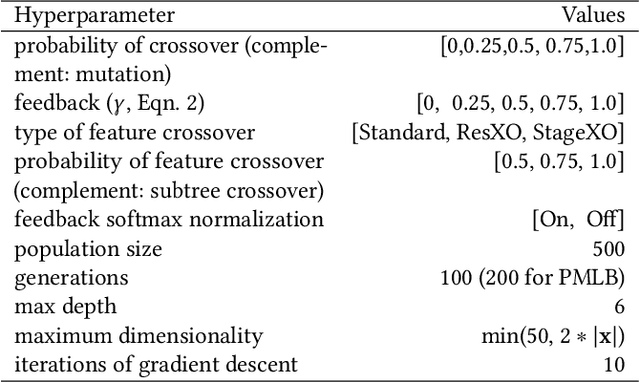


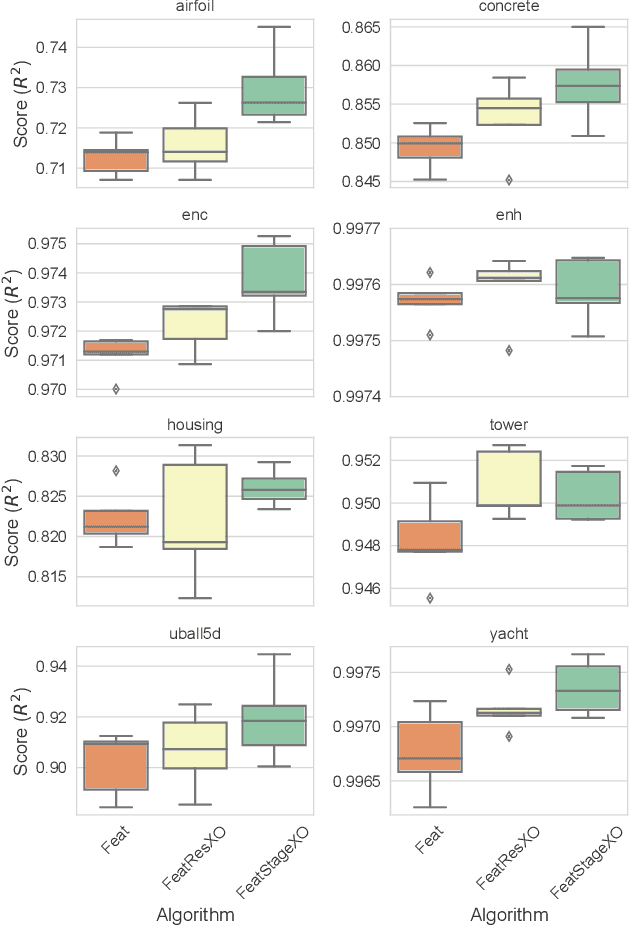
Multidimensional genetic programming represents candidate solutions as sets of programs, and thereby provides an interesting framework for exploiting building block identification. Towards this goal, we investigate the use of machine learning as a way to bias which components of programs are promoted, and propose two semantic operators to choose where useful building blocks are placed during crossover. A forward stagewise crossover operator we propose leads to significant improvements on a set of regression problems, and produces state-of-the-art results in a large benchmark study. We discuss this architecture and others in terms of their propensity for allowing heuristic search to utilize information during the evolutionary process. Finally, we look at the collinearity and complexity of the data representations that result from these architectures, with a view towards disentangling factors of variation in application.
Interpretation of machine learning predictions for patient outcomes in electronic health records
Mar 14, 2019
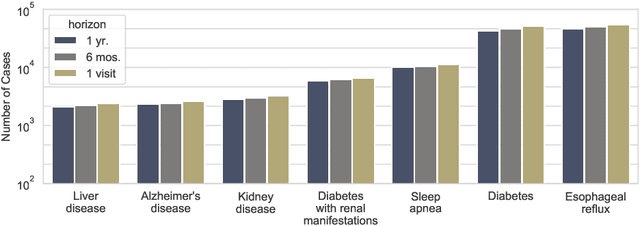
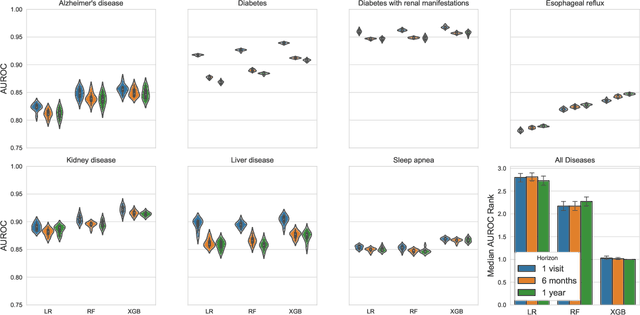
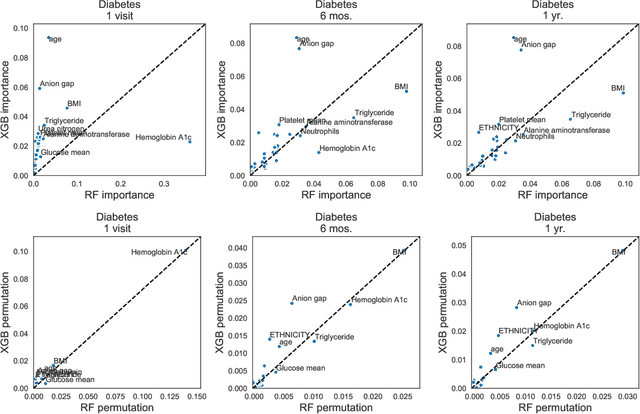
Electronic health records are an increasingly important resource for understanding the interactions between patient health, environment, and clinical decisions. In this paper we report an empirical study of predictive modeling of several patient outcomes using three state-of-the-art machine learning methods. Our primary goal is to validate the models by interpreting the importance of predictors in the final models. Central to interpretation is the use of feature importance scores, which vary depending on the underlying methodology. In order to assess feature importance, we compared univariate statistical tests, information-theoretic measures, permutation testing, and normalized coefficients from multivariate logistic regression models. In general we found poor correlation between methods in their assessment of feature importance, even when their performance is comparable and relatively good. However, permutation tests applied to random forest and gradient boosting models showed the most agreement, and the importance scores matched the clinical interpretation most frequently.
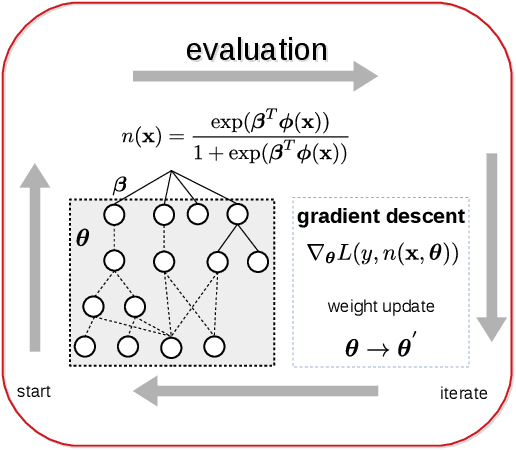
Learning concise representations for regression by evolving networks of trees
Oct 05, 2018
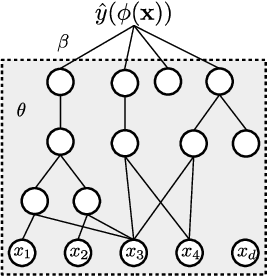


We propose and study a method for learning interpretable representations for the task of regression. Features are represented as networks of multi-type expression trees comprised of activation functions common in neural networks in addition to other elementary functions. Differentiable features are trained via gradient descent, and the performance of features in a linear model is used to weight the rate of change among subcomponents of each representation. The search process maintains an archive of representations with accuracy-complexity trade-offs to assist in generalization and interpretation. We compare several stochastic optimization approaches within this framework. We benchmark these variants on 99 open-source regression problems in comparison to state-of-the-art machine learning approaches. Our main finding is that this approach produces the highest average test scores across problems while producing representations that are orders of magnitude smaller than the next best performing method (gradient boosting). We also report a negative result in which attempts to directly optimize the disentanglement of the representation results in more highly correlated features.