 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic variation operators for multidimensional genetic programming
Paper and Code
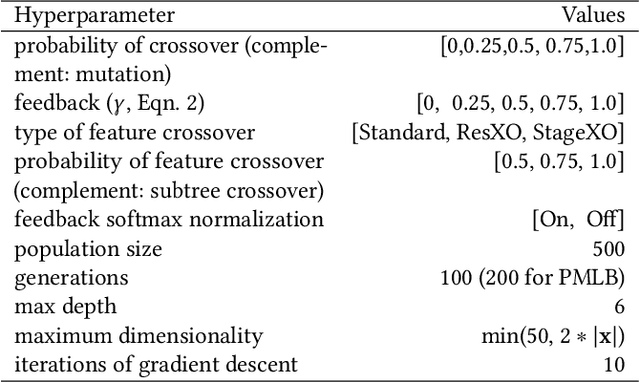


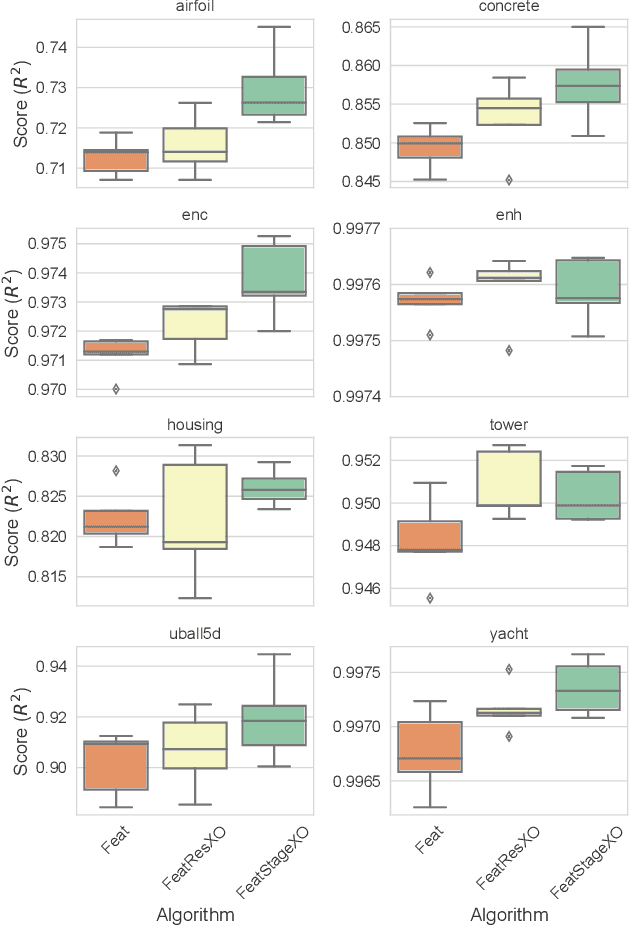
Multidimensional genetic programming represents candidate solutions as sets of programs, and thereby provides an interesting framework for exploiting building block identification. Towards this goal, we investigate the use of machine learning as a way to bias which components of programs are promoted, and propose two semantic operators to choose where useful building blocks are placed during crossover. A forward stagewise crossover operator we propose leads to significant improvements on a set of regression problems, and produces state-of-the-art results in a large benchmark study. We discuss this architecture and others in terms of their propensity for allowing heuristic search to utilize information during the evolutionary process. Finally, we look at the collinearity and complexity of the data representations that result from these architectures, with a view towards disentangling factors of variation in application.