 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePMLB v1.0: an open source dataset collection for benchmarking machine learning methods
Nov 30, 2020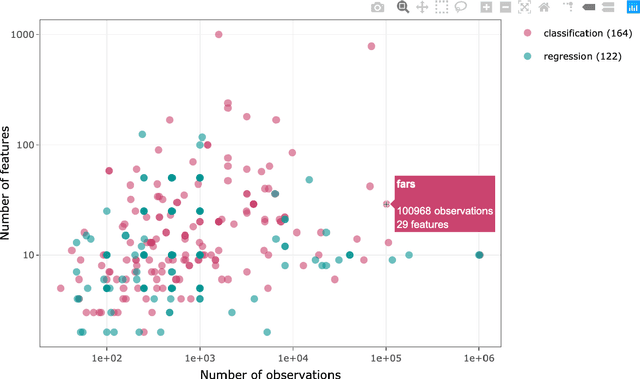

PMLB (Penn Machine Learning Benchmark) is an open-source data repository containing a curated collection of datasets for evaluating and comparing machine learning (ML) algorithms. Compiled from a broad range of existing ML benchmark collections, PMLB synthesizes and standardizes hundreds of publicly available datasets from diverse sources such as the UCI ML repository and OpenML, enabling systematic assessment of different ML methods. These datasets cover a range of applications, from binary/multi-class classification to regression problems with combinations of categorical and continuous features. PMLB has both a Python interface (pmlb) and an R interface (pmlbr), both with detailed documentation that allows the user to access cleaned and formatted datasets using a single function call. PMLB also provides a comprehensive description of each dataset and advanced functions to explore the dataset space, allowing for smoother user experience and handling of data. The resource is designed to facilitate open-source contributions in the form of datasets as well as improvements to curation.
Is deep learning necessary for simple classification tasks?
Jun 11, 2020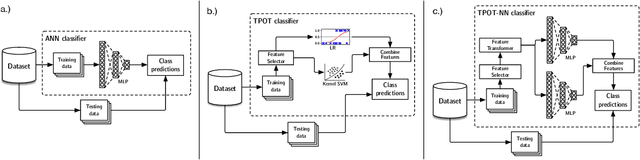
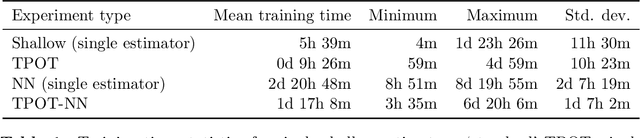


Automated machine learning (AutoML) and deep learning (DL) are two cutting-edge paradigms used to solve a myriad of inductive learning tasks. In spite of their successes, little guidance exists for when to choose one approach over the other in the context of specific real-world problems. Furthermore, relatively few tools exist that allow the integration of both AutoML and DL in the same analysis to yield results combining both of their strengths. Here, we seek to address both of these issues, by (1.) providing a head-to-head comparison of AutoML and DL in the context of binary classification on 6 well-characterized public datasets, and (2.) evaluating a new tool for genetic programming-based AutoML that incorporates deep estimators. Our observations suggest that AutoML outperforms simple DL classifiers when trained on similar datasets for binary classification but integrating DL into AutoML improves classification performance even further. However, the substantial time needed to train AutoML+DL pipelines will likely outweigh performance advantages in many applications.
Evaluating recommender systems for AI-driven data science
Jun 07, 2019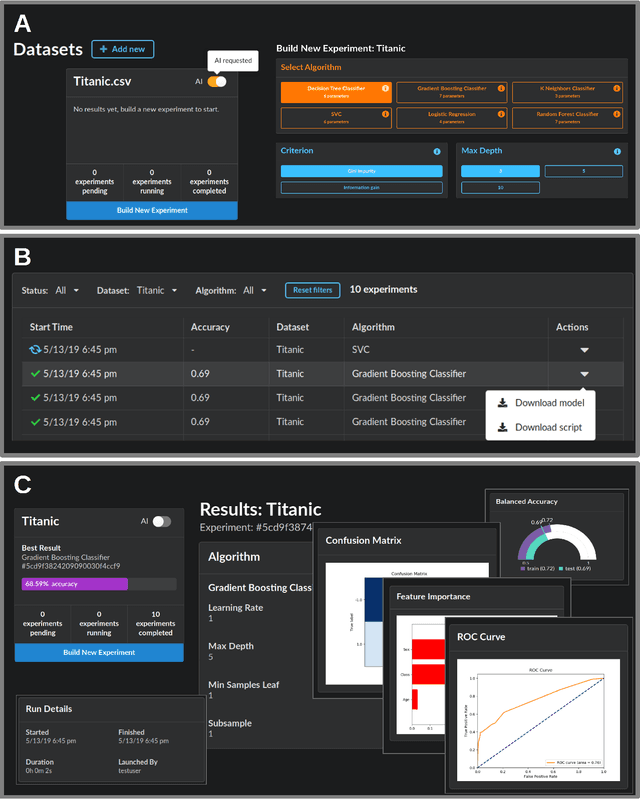
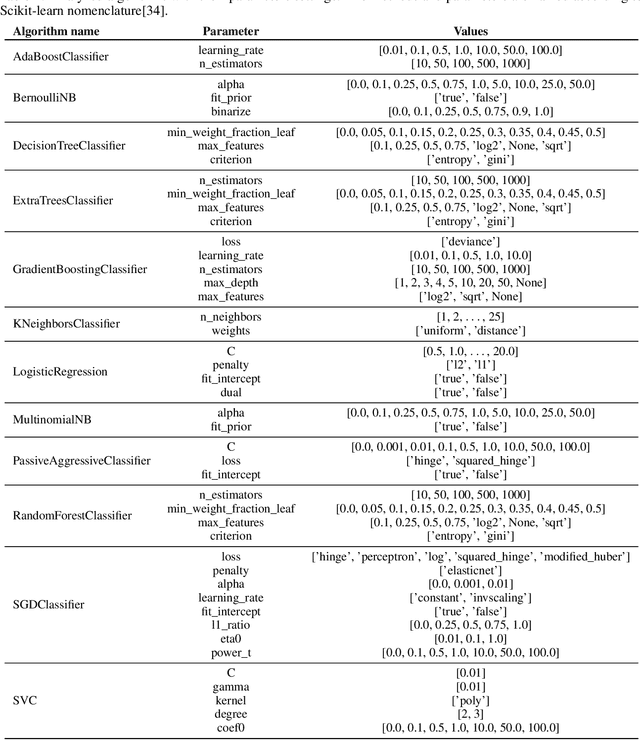
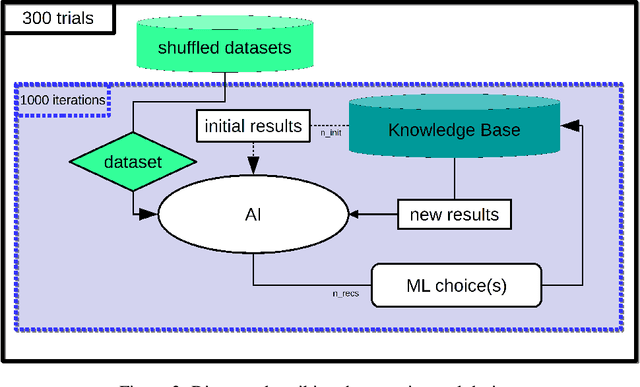
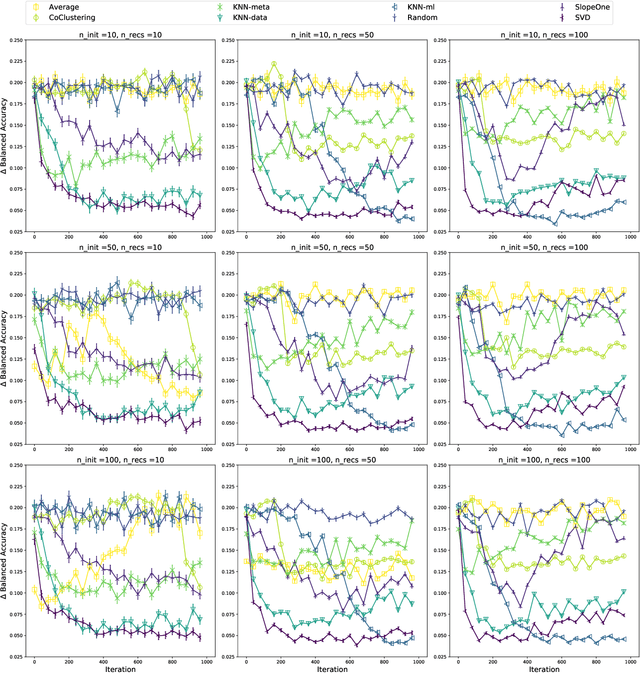
We present a free and open-source platform to allow researchers to easily apply supervised machine learning to their data. A key component of this system is a recommendation engine that is bootstrapped with machine learning results generated on a repository of open-source datasets. The recommendation system chooses which analyses to run for the user, and allows the user to view analyses, download reproducible code or fitted models, and visualize results via a web browser. The recommender system learns online as results are generated. In this paper we benchmark several recommendation strategies, including collaborative filtering and metalearning approaches, for their ability to learn to select and run optimal algorithm configurations for various datasets as results are generated. We find that a matrix factorization-based recommendation system learns to choose increasingly accurate models from few initial results.
Investigating the Parameter Space of Evolutionary Algorithms
Oct 10, 2017
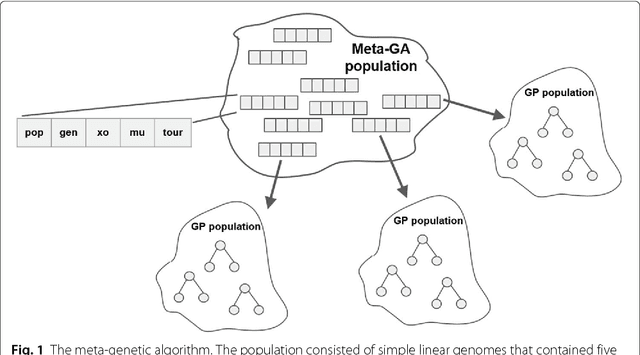
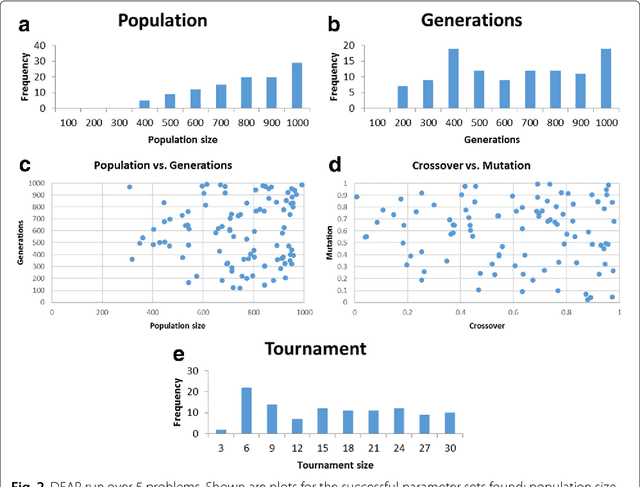
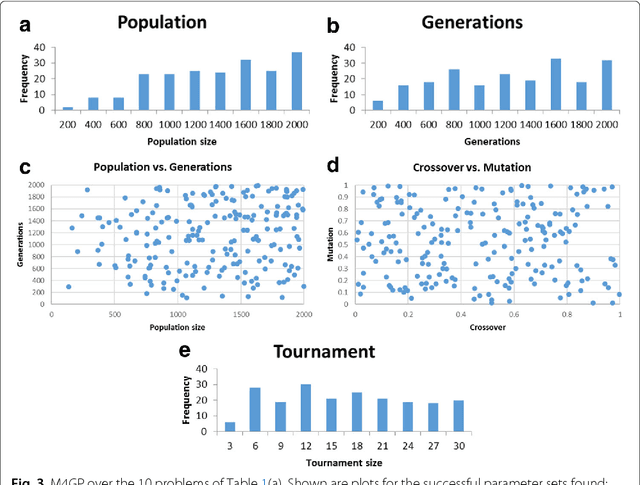
The practice of evolutionary algorithms involves the tuning of many parameters. How big should the population be? How many generations should the algorithm run? What is the (tournament selection) tournament size? What probabilities should one assign to crossover and mutation? Through an extensive series of experiments over multiple evolutionary algorithm implementations and problems we show that parameter space tends to be rife with viable parameters, at least for 25 the problems studied herein. We discuss the implications of this finding in practice.
A System for Accessible Artificial Intelligence
Aug 10, 2017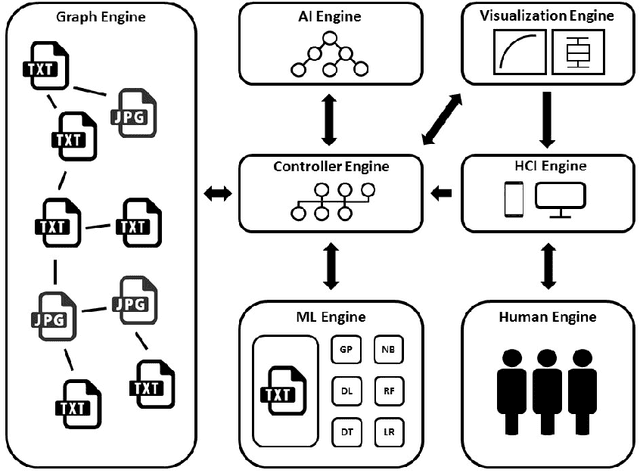


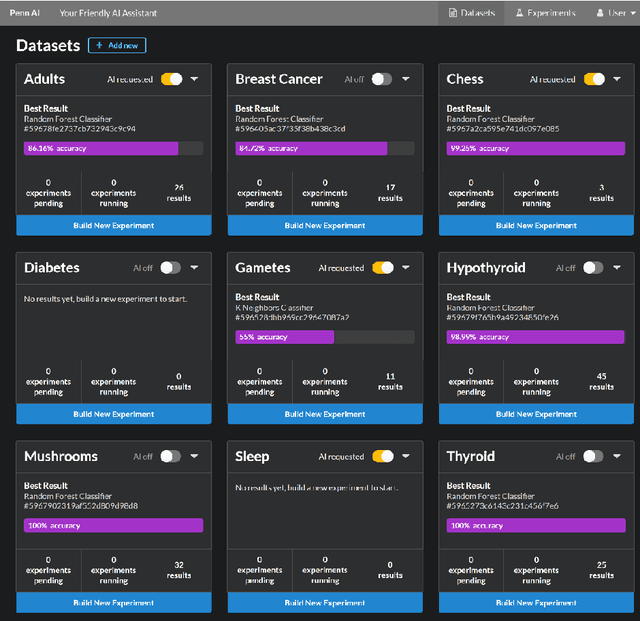
While artificial intelligence (AI) has become widespread, many commercial AI systems are not yet accessible to individual researchers nor the general public due to the deep knowledge of the systems required to use them. We believe that AI has matured to the point where it should be an accessible technology for everyone. We present an ongoing project whose ultimate goal is to deliver an open source, user-friendly AI system that is specialized for machine learning analysis of complex data in the biomedical and health care domains. We discuss how genetic programming can aid in this endeavor, and highlight specific examples where genetic programming has automated machine learning analyses in previous projects.