 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePMLB v1.0: an open source dataset collection for benchmarking machine learning methods
Nov 30, 2020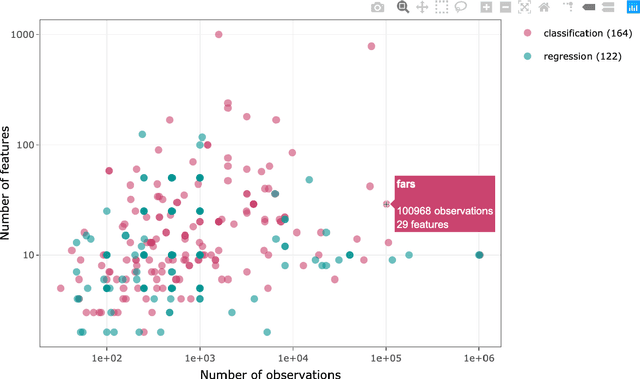

PMLB (Penn Machine Learning Benchmark) is an open-source data repository containing a curated collection of datasets for evaluating and comparing machine learning (ML) algorithms. Compiled from a broad range of existing ML benchmark collections, PMLB synthesizes and standardizes hundreds of publicly available datasets from diverse sources such as the UCI ML repository and OpenML, enabling systematic assessment of different ML methods. These datasets cover a range of applications, from binary/multi-class classification to regression problems with combinations of categorical and continuous features. PMLB has both a Python interface (pmlb) and an R interface (pmlbr), both with detailed documentation that allows the user to access cleaned and formatted datasets using a single function call. PMLB also provides a comprehensive description of each dataset and advanced functions to explore the dataset space, allowing for smoother user experience and handling of data. The resource is designed to facilitate open-source contributions in the form of datasets as well as improvements to curation.