 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlign2Ground: Weakly Supervised Phrase Grounding Guided by Image-Caption Alignment
Mar 27, 2019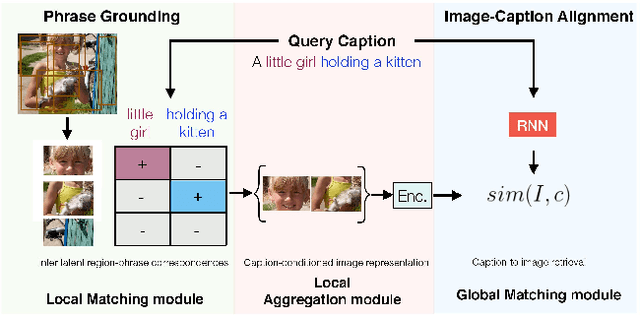
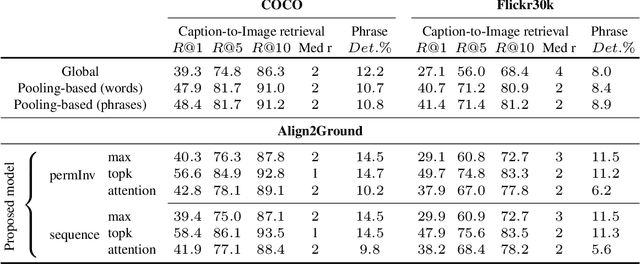


We address the problem of grounding free-form textual phrases by using weak supervision from image-caption pairs. We propose a novel end-to-end model that uses caption-to-image retrieval as a `downstream' task to guide the process of phrase localization. Our method, as a first step, infers the latent correspondences between regions-of-interest (RoIs) and phrases in the caption and creates a discriminative image representation using these matched RoIs. In a subsequent step, this (learned) representation is aligned with the caption. Our key contribution lies in building this `caption-conditioned' image encoding which tightly couples both the tasks and allows the weak supervision to effectively guide visual grounding. We provide an extensive empirical and qualitative analysis to investigate the different components of our proposed model and compare it with competitive baselines. For phrase localization, we report an improvement of 4.9% (absolute) over the prior state-of-the-art on the VisualGenome dataset. We also report results that are at par with the state-of-the-art on the downstream caption-to-image retrieval task on COCO and Flickr30k datasets.
Understanding Visual Ads by Aligning Symbols and Objects using Co-Attention
Jul 04, 2018
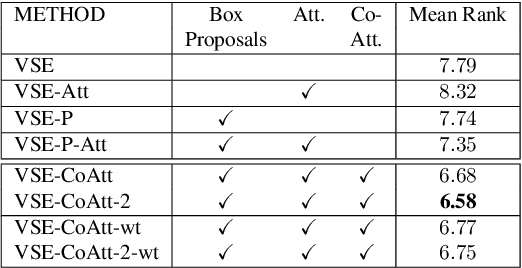
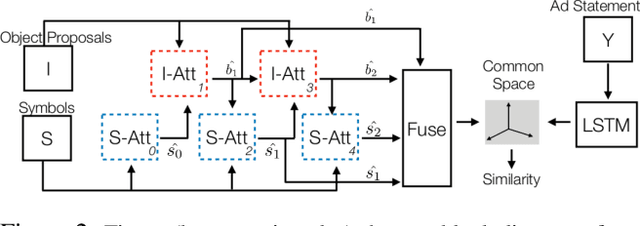

We tackle the problem of understanding visual ads where given an ad image, our goal is to rank appropriate human generated statements describing the purpose of the ad. This problem is generally addressed by jointly embedding images and candidate statements to establish correspondence. Decoding a visual ad requires inference of both semantic and symbolic nuances referenced in an image and prior methods may fail to capture such associations especially with weakly annotated symbols. In order to create better embeddings, we leverage an attention mechanism to associate image proposals with symbols and thus effectively aggregate information from aligned multimodal representations. We propose a multihop co-attention mechanism that iteratively refines the attention map to ensure accurate attention estimation. Our attention based embedding model is learned end-to-end guided by a max-margin loss function. We show that our model outperforms other baselines on the benchmark Ad dataset and also show qualitative results to highlight the advantages of using multihop co-attention.
Investigating the Parameter Space of Evolutionary Algorithms
Oct 10, 2017
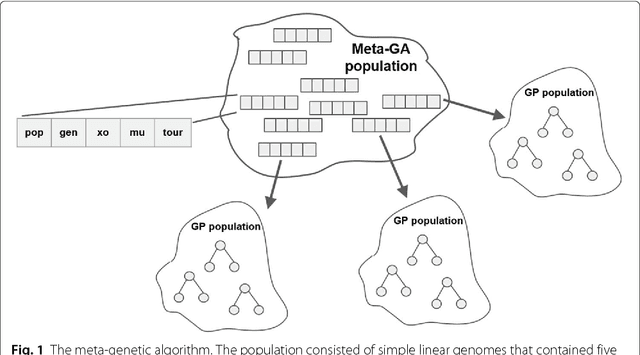
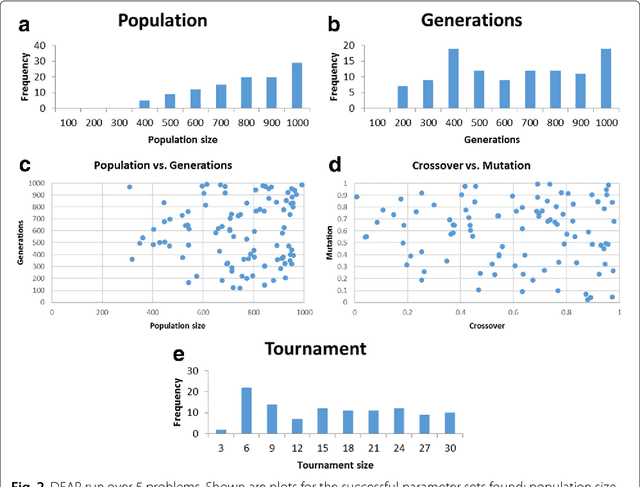
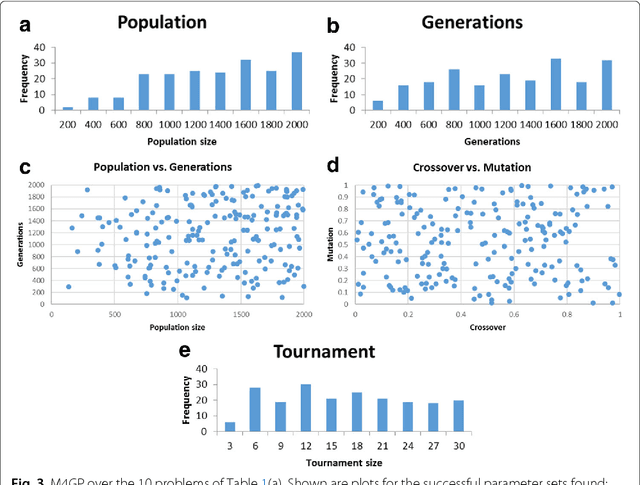
The practice of evolutionary algorithms involves the tuning of many parameters. How big should the population be? How many generations should the algorithm run? What is the (tournament selection) tournament size? What probabilities should one assign to crossover and mutation? Through an extensive series of experiments over multiple evolutionary algorithm implementations and problems we show that parameter space tends to be rife with viable parameters, at least for 25 the problems studied herein. We discuss the implications of this finding in practice.