 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking Bad: Interpretability-Based Safety Audits of State-of-the-Art LLMs
Apr 22, 2026Effective safety auditing of large language models (LLMs) demands tools that go beyond black-box probing and systematically uncover vulnerabilities rooted in model internals. We present a comprehensive, interpretability-driven jailbreaking audit of eight SOTA open-source LLMs: Llama-3.1-8B, Llama-3.3-70B-4bt, GPT-oss- 20B, GPT-oss-120B, Qwen3-0.6B, Qwen3-32B, Phi4-3.8B, and Phi4-14B. Leveraging interpretability-based approaches -- Universal Steering (US) and Representation Engineering (RepE) -- we introduce an adaptive two-stage grid search algorithm to identify optimal activation-steering coefficients for unsafe behavioral concepts. Our evaluation, conducted on a curated set of harmful queries and a standardized LLM-based judging protocol, reveals stark contrasts in model robustness. The Llama-3 models are highly vulnerable, with up to 91\% (US) and 83\% (RepE) jailbroken responses on Llama-3.3-70B-4bt, while GPT-oss-120B remains robust to attacks via both interpretability approaches. Qwen and Phi models show mixed results, with the smaller Qwen3-0.6B and Phi4-3.8B mostly exhibiting lower jailbreaking rates, while their larger counterparts are more susceptible. Our results establish interpretability-based steering as a powerful tool for systematic safety audits, but also highlight its dual-use risks and the need for better internal defenses in LLM deployment.
Polysemantic Dropout: Conformal OOD Detection for Specialized LLMs
Sep 04, 2025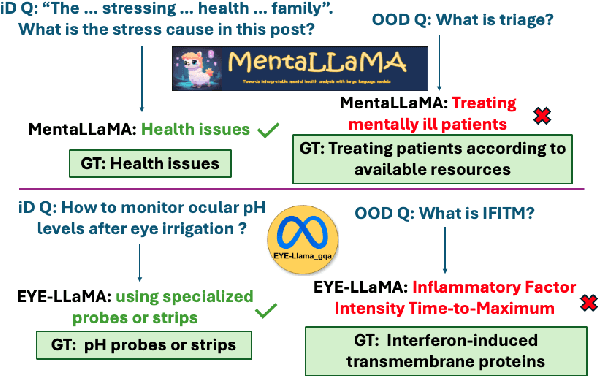

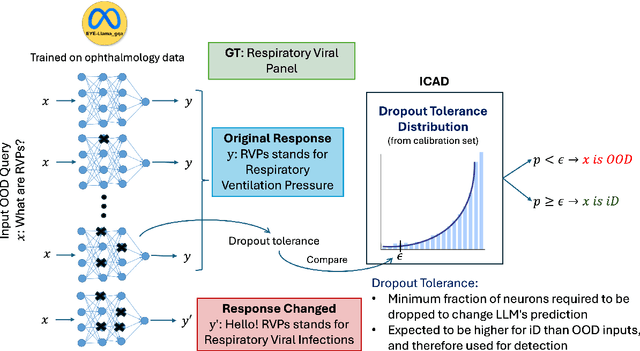

We propose a novel inference-time out-of-domain (OOD) detection algorithm for specialized large language models (LLMs). Despite achieving state-of-the-art performance on in-domain tasks through fine-tuning, specialized LLMs remain vulnerable to incorrect or unreliable outputs when presented with OOD inputs, posing risks in critical applications. Our method leverages the Inductive Conformal Anomaly Detection (ICAD) framework, using a new non-conformity measure based on the model's dropout tolerance. Motivated by recent findings on polysemanticity and redundancy in LLMs, we hypothesize that in-domain inputs exhibit higher dropout tolerance than OOD inputs. We aggregate dropout tolerance across multiple layers via a valid ensemble approach, improving detection while maintaining theoretical false alarm bounds from ICAD. Experiments with medical-specialized LLMs show that our approach detects OOD inputs better than baseline methods, with AUROC improvements of $2\%$ to $37\%$ when treating OOD datapoints as positives and in-domain test datapoints as negatives.
TOGA: Temporally Grounded Open-Ended Video QA with Weak Supervision
Jun 11, 2025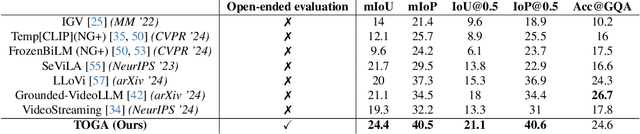

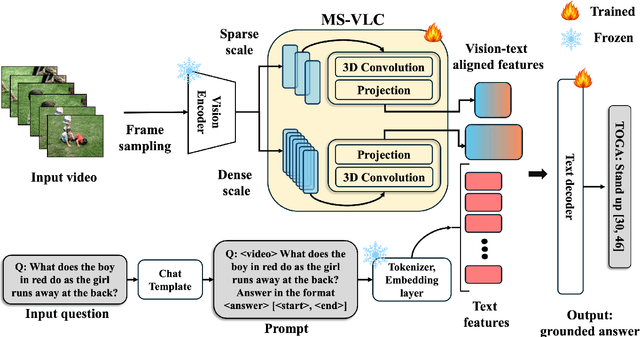
We address the problem of video question answering (video QA) with temporal grounding in a weakly supervised setup, without any temporal annotations. Given a video and a question, we generate an open-ended answer grounded with the start and end time. For this task, we propose TOGA: a vision-language model for Temporally Grounded Open-Ended Video QA with Weak Supervision. We instruct-tune TOGA to jointly generate the answer and the temporal grounding. We operate in a weakly supervised setup where the temporal grounding annotations are not available. We generate pseudo labels for temporal grounding and ensure the validity of these labels by imposing a consistency constraint between the question of a grounding response and the response generated by a question referring to the same temporal segment. We notice that jointly generating the answers with the grounding improves performance on question answering as well as grounding. We evaluate TOGA on grounded QA and open-ended QA tasks. For grounded QA, we consider the NExT-GQA benchmark which is designed to evaluate weakly supervised grounded question answering. For open-ended QA, we consider the MSVD-QA and ActivityNet-QA benchmarks. We achieve state-of-the-art performance for both tasks on these benchmarks.
Calibrating Uncertainty Quantification of Multi-Modal LLMs using Grounding
Apr 30, 2025We introduce a novel approach for calibrating uncertainty quantification (UQ) tailored for multi-modal large language models (LLMs). Existing state-of-the-art UQ methods rely on consistency among multiple responses generated by the LLM on an input query under diverse settings. However, these approaches often report higher confidence in scenarios where the LLM is consistently incorrect. This leads to a poorly calibrated confidence with respect to accuracy. To address this, we leverage cross-modal consistency in addition to self-consistency to improve the calibration of the multi-modal models. Specifically, we ground the textual responses to the visual inputs. The confidence from the grounding model is used to calibrate the overall confidence. Given that using a grounding model adds its own uncertainty in the pipeline, we apply temperature scaling - a widely accepted parametric calibration technique - to calibrate the grounding model's confidence in the accuracy of generated responses. We evaluate the proposed approach across multiple multi-modal tasks, such as medical question answering (Slake) and visual question answering (VQAv2), considering multi-modal models such as LLaVA-Med and LLaVA. The experiments demonstrate that the proposed framework achieves significantly improved calibration on both tasks.
Safety Monitoring for Learning-Enabled Cyber-Physical Systems in Out-of-Distribution Scenarios
Apr 18, 2025The safety of learning-enabled cyber-physical systems is compromised by the well-known vulnerabilities of deep neural networks to out-of-distribution (OOD) inputs. Existing literature has sought to monitor the safety of such systems by detecting OOD data. However, such approaches have limited utility, as the presence of an OOD input does not necessarily imply the violation of a desired safety property. We instead propose to directly monitor safety in a manner that is itself robust to OOD data. To this end, we predict violations of signal temporal logic safety specifications based on predicted future trajectories. Our safety monitor additionally uses a novel combination of adaptive conformal prediction and incremental learning. The former obtains probabilistic prediction guarantees even on OOD data, and the latter prevents overly conservative predictions. We evaluate the efficacy of the proposed approach in two case studies on safety monitoring: 1) predicting collisions of an F1Tenth car with static obstacles, and 2) predicting collisions of a race car with multiple dynamic obstacles. We find that adaptive conformal prediction obtains theoretical guarantees where other uncertainty quantification methods fail to do so. Additionally, combining adaptive conformal prediction and incremental learning for safety monitoring achieves high recall and timeliness while reducing loss in precision. We achieve these results even in OOD settings and outperform alternative methods.
TeleLoRA: Teleporting Model-Specific Alignment Across LLMs
Mar 26, 2025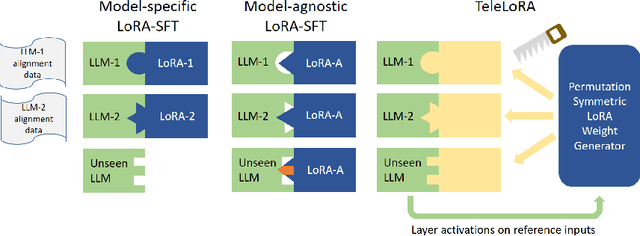

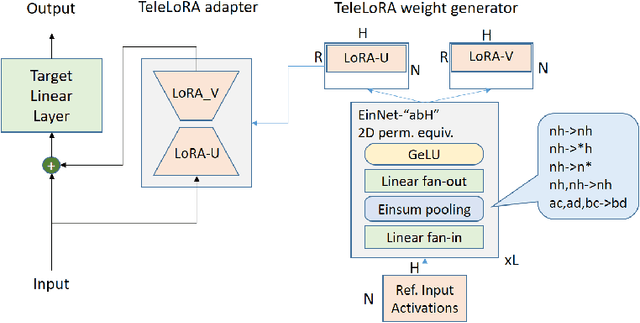

Mitigating Trojans in Large Language Models (LLMs) is one of many tasks where alignment data is LLM specific, as different LLMs have different Trojan triggers and trigger behaviors to be removed. In this paper, we introduce TeleLoRA (Teleporting Low-Rank Adaptation), a novel framework that synergizes model-specific alignment data across multiple LLMs to enable zero-shot Trojan mitigation on unseen LLMs without alignment data. TeleLoRA learns a unified generator of LoRA adapter weights by leveraging local activation information across multiple LLMs. This generator is designed to be permutation symmetric to generalize across models with different architectures and sizes. We optimize the model design for memory efficiency, making it feasible to learn with large-scale LLMs with minimal computational resources. Experiments on LLM Trojan mitigation benchmarks demonstrate that TeleLoRA effectively reduces attack success rates while preserving the benign performance of the models.
Shrinking POMCP: A Framework for Real-Time UAV Search and Rescue
Nov 20, 2024



Efficient path optimization for drones in search and rescue operations faces challenges, including limited visibility, time constraints, and complex information gathering in urban environments. We present a comprehensive approach to optimize UAV-based search and rescue operations in neighborhood areas, utilizing both a 3D AirSim-ROS2 simulator and a 2D simulator. The path planning problem is formulated as a partially observable Markov decision process (POMDP), and we propose a novel ``Shrinking POMCP'' approach to address time constraints. In the AirSim environment, we integrate our approach with a probabilistic world model for belief maintenance and a neurosymbolic navigator for obstacle avoidance. The 2D simulator employs surrogate ROS2 nodes with equivalent functionality. We compare trajectories generated by different approaches in the 2D simulator and evaluate performance across various belief types in the 3D AirSim-ROS simulator. Experimental results from both simulators demonstrate that our proposed shrinking POMCP solution achieves significant improvements in search times compared to alternative methods, showcasing its potential for enhancing the efficiency of UAV-assisted search and rescue operations.
Addressing Uncertainty in LLMs to Enhance Reliability in Generative AI
Nov 04, 2024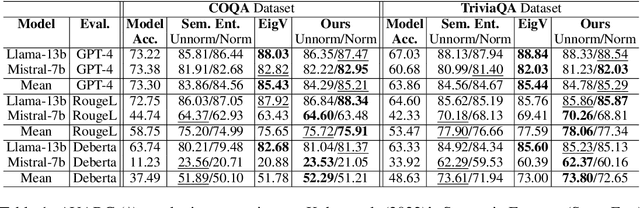
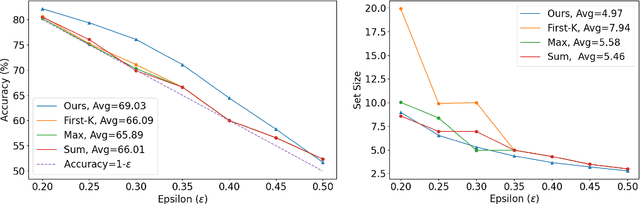
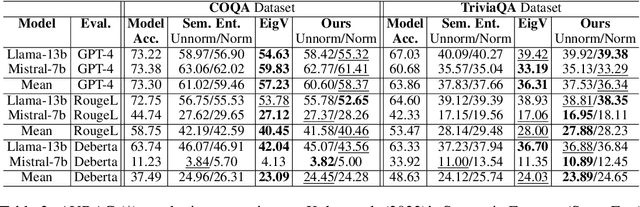
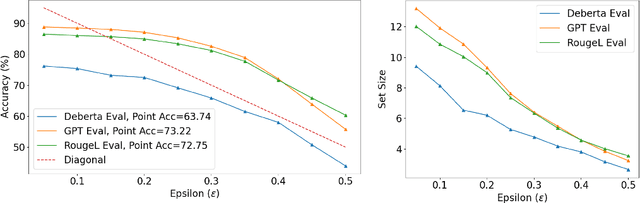
In this paper, we present a dynamic semantic clustering approach inspired by the Chinese Restaurant Process, aimed at addressing uncertainty in the inference of Large Language Models (LLMs). We quantify uncertainty of an LLM on a given query by calculating entropy of the generated semantic clusters. Further, we propose leveraging the (negative) likelihood of these clusters as the (non)conformity score within Conformal Prediction framework, allowing the model to predict a set of responses instead of a single output, thereby accounting for uncertainty in its predictions. We demonstrate the effectiveness of our uncertainty quantification (UQ) technique on two well known question answering benchmarks, COQA and TriviaQA, utilizing two LLMs, Llama2 and Mistral. Our approach achieves SOTA performance in UQ, as assessed by metrics such as AUROC, AUARC, and AURAC. The proposed conformal predictor is also shown to produce smaller prediction sets while maintaining the same probabilistic guarantee of including the correct response, in comparison to existing SOTA conformal prediction baseline.
Concept-based Analysis of Neural Networks via Vision-Language Models
Apr 10, 2024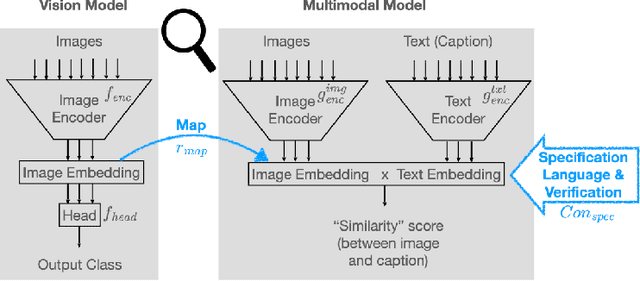
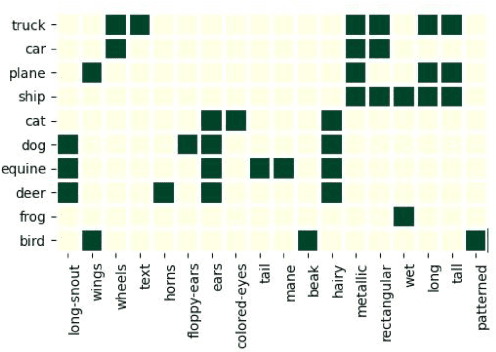
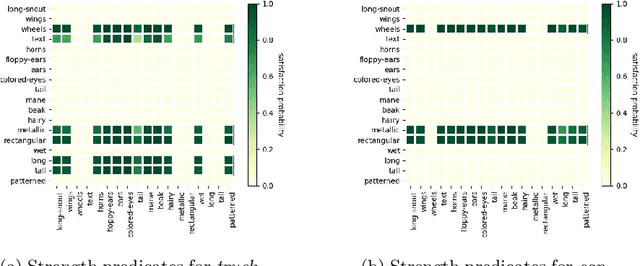
The analysis of vision-based deep neural networks (DNNs) is highly desirable but it is very challenging due to the difficulty of expressing formal specifications for vision tasks and the lack of efficient verification procedures. In this paper, we propose to leverage emerging multimodal, vision-language, foundation models (VLMs) as a lens through which we can reason about vision models. VLMs have been trained on a large body of images accompanied by their textual description, and are thus implicitly aware of high-level, human-understandable concepts describing the images. We describe a logical specification language $\texttt{Con}_{\texttt{spec}}$ designed to facilitate writing specifications in terms of these concepts. To define and formally check $\texttt{Con}_{\texttt{spec}}$ specifications, we build a map between the internal representations of a given vision model and a VLM, leading to an efficient verification procedure of natural-language properties for vision models. We demonstrate our techniques on a ResNet-based classifier trained on the RIVAL-10 dataset using CLIP as the multimodal model.
BRI3L: A Brightness Illusion Image Dataset for Identification and Localization of Regions of Illusory Perception
Feb 07, 2024Visual illusions play a significant role in understanding visual perception. Current methods in understanding and evaluating visual illusions are mostly deterministic filtering based approach and they evaluate on a handful of visual illusions, and the conclusions therefore, are not generic. To this end, we generate a large-scale dataset of 22,366 images (BRI3L: BRightness Illusion Image dataset for Identification and Localization of illusory perception) of the five types of brightness illusions and benchmark the dataset using data-driven neural network based approaches. The dataset contains label information - (1) whether a particular image is illusory/nonillusory, (2) the segmentation mask of the illusory region of the image. Hence, both the classification and segmentation task can be evaluated using this dataset. We follow the standard psychophysical experiments involving human subjects to validate the dataset. To the best of our knowledge, this is the first attempt to develop a dataset of visual illusions and benchmark using data-driven approach for illusion classification and localization. We consider five well-studied types of brightness illusions: 1) Hermann grid, 2) Simultaneous Brightness Contrast, 3) White illusion, 4) Grid illusion, and 5) Induced Grating illusion. Benchmarking on the dataset achieves 99.56% accuracy in illusion identification and 84.37% pixel accuracy in illusion localization. The application of deep learning model, it is shown, also generalizes over unseen brightness illusions like brightness assimilation to contrast transitions. We also test the ability of state-of-theart diffusion models to generate brightness illusions. We have provided all the code, dataset, instructions etc in the github repo: https://github.com/aniket004/BRI3L