 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Decision-Making Under Uncertainty for Vehicle-to-Building Systems
Jan 07, 2026Vehicle-to-building (V2B) systems integrate physical infrastructures, such as smart buildings and electric vehicles (EVs) connected to chargers at the building, with digital control mechanisms to manage energy use. By utilizing EVs as flexible energy reservoirs, buildings can dynamically charge and discharge them to optimize energy use and cut costs under time-variable pricing and demand charge policies. This setup leads to the V2B optimization problem, where buildings coordinate EV charging and discharging to minimize total electricity costs while meeting users' charging requirements. However, the V2B optimization problem is challenging because of: (1) fluctuating electricity pricing, which includes both energy charges ($/kWh) and demand charges ($/kW); (2) long planning horizons (typically over 30 days); (3) heterogeneous chargers with varying charging rates, controllability, and directionality (i.e., unidirectional or bidirectional); and (4) user-specific battery levels at departure to ensure user requirements are met. In contrast to existing approaches that often model this setting as a single-shot combinatorial optimization problem, we highlight critical limitations in prior work and instead model the V2B optimization problem as a Markov decision process (MDP), i.e., a stochastic control process. Solving the resulting MDP is challenging due to the large state and action spaces. To address the challenges of the large state space, we leverage online search, and we counter the action space by using domain-specific heuristics to prune unpromising actions. We validate our approach in collaboration with Nissan Advanced Technology Center - Silicon Valley. Using data from their EV testbed, we show that the proposed framework significantly outperforms state-of-the-art methods.
* 17 pages, 2 figures, 10 tables. Published in the Proceedings of the 16th ACM/IEEE International Conference on Cyber-Physical Systems (ICCPS '25), May 06--09, 2025, Irvine, CA, USA
Observation Adaptation via Annealed Importance Resampling for Partially Observable Markov Decision Processes
Mar 25, 2025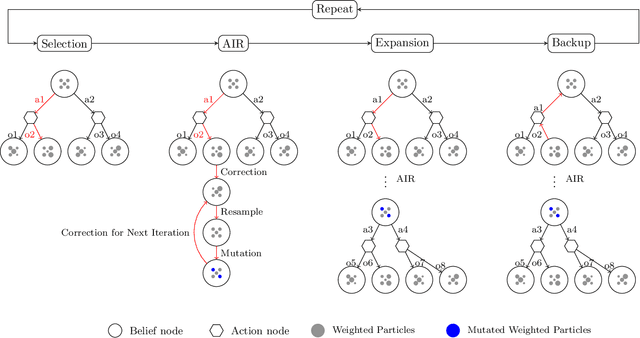
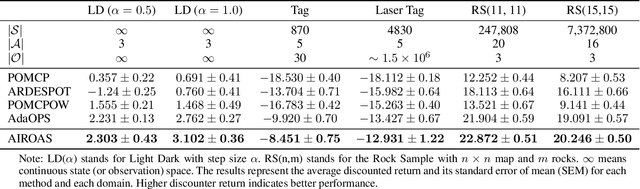
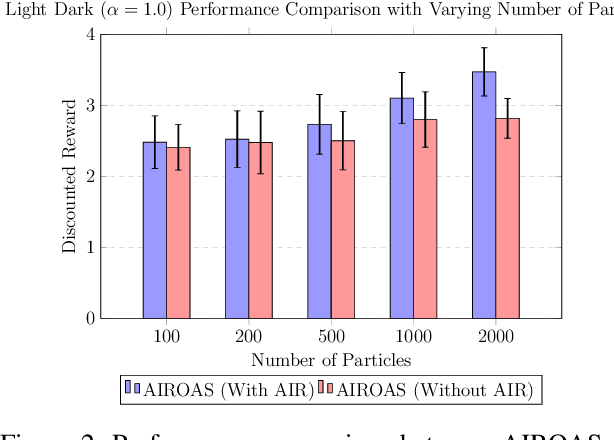
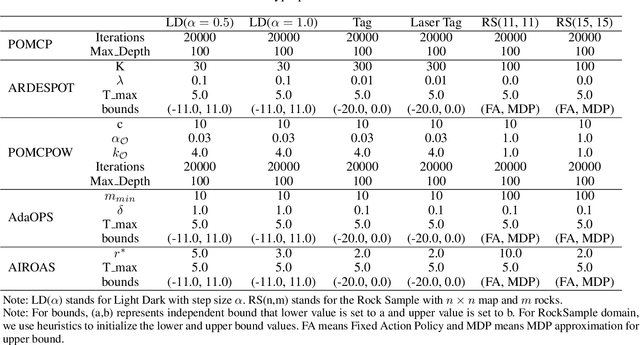
Partially observable Markov decision processes (POMDPs) are a general mathematical model for sequential decision-making in stochastic environments under state uncertainty. POMDPs are often solved \textit{online}, which enables the algorithm to adapt to new information in real time. Online solvers typically use bootstrap particle filters based on importance resampling for updating the belief distribution. Since directly sampling from the ideal state distribution given the latest observation and previous state is infeasible, particle filters approximate the posterior belief distribution by propagating states and adjusting weights through prediction and resampling steps. However, in practice, the importance resampling technique often leads to particle degeneracy and sample impoverishment when the state transition model poorly aligns with the posterior belief distribution, especially when the received observation is highly informative. We propose an approach that constructs a sequence of bridge distributions between the state-transition and optimal distributions through iterative Monte Carlo steps, better accommodating noisy observations in online POMDP solvers. Our algorithm demonstrates significantly superior performance compared to state-of-the-art methods when evaluated across multiple challenging POMDP domains.
NS-Gym: Open-Source Simulation Environments and Benchmarks for Non-Stationary Markov Decision Processes
Jan 16, 2025



In many real-world applications, agents must make sequential decisions in environments where conditions are subject to change due to various exogenous factors. These non-stationary environments pose significant challenges to traditional decision-making models, which typically assume stationary dynamics. Non-stationary Markov decision processes (NS-MDPs) offer a framework to model and solve decision problems under such changing conditions. However, the lack of standardized benchmarks and simulation tools has hindered systematic evaluation and advance in this field. We present NS-Gym, the first simulation toolkit designed explicitly for NS-MDPs, integrated within the popular Gymnasium framework. In NS-Gym, we segregate the evolution of the environmental parameters that characterize non-stationarity from the agent's decision-making module, allowing for modular and flexible adaptations to dynamic environments. We review prior work in this domain and present a toolkit encapsulating key problem characteristics and types in NS-MDPs. This toolkit is the first effort to develop a set of standardized interfaces and benchmark problems to enable consistent and reproducible evaluation of algorithms under non-stationary conditions. We also benchmark six algorithmic approaches from prior work on NS-MDPs using NS-Gym. Our vision is that NS-Gym will enable researchers to assess the adaptability and robustness of their decision-making algorithms to non-stationary conditions.
Shrinking POMCP: A Framework for Real-Time UAV Search and Rescue
Nov 20, 2024



Efficient path optimization for drones in search and rescue operations faces challenges, including limited visibility, time constraints, and complex information gathering in urban environments. We present a comprehensive approach to optimize UAV-based search and rescue operations in neighborhood areas, utilizing both a 3D AirSim-ROS2 simulator and a 2D simulator. The path planning problem is formulated as a partially observable Markov decision process (POMDP), and we propose a novel ``Shrinking POMCP'' approach to address time constraints. In the AirSim environment, we integrate our approach with a probabilistic world model for belief maintenance and a neurosymbolic navigator for obstacle avoidance. The 2D simulator employs surrogate ROS2 nodes with equivalent functionality. We compare trajectories generated by different approaches in the 2D simulator and evaluate performance across various belief types in the 3D AirSim-ROS simulator. Experimental results from both simulators demonstrate that our proposed shrinking POMCP solution achieves significant improvements in search times compared to alternative methods, showcasing its potential for enhancing the efficiency of UAV-assisted search and rescue operations.
Act as You Learn: Adaptive Decision-Making in Non-Stationary Markov Decision Processes
Jan 15, 2024



A fundamental (and largely open) challenge in sequential decision-making is dealing with non-stationary environments, where exogenous environmental conditions change over time. Such problems are traditionally modeled as non-stationary Markov decision processes (NSMDP). However, existing approaches for decision-making in NSMDPs have two major shortcomings: first, they assume that the updated environmental dynamics at the current time are known (although future dynamics can change); and second, planning is largely pessimistic, i.e., the agent acts ``safely'' to account for the non-stationary evolution of the environment. We argue that both these assumptions are invalid in practice -- updated environmental conditions are rarely known, and as the agent interacts with the environment, it can learn about the updated dynamics and avoid being pessimistic, at least in states whose dynamics it is confident about. We present a heuristic search algorithm called \textit{Adaptive Monte Carlo Tree Search (ADA-MCTS)} that addresses these challenges. We show that the agent can learn the updated dynamics of the environment over time and then act as it learns, i.e., if the agent is in a region of the state space about which it has updated knowledge, it can avoid being pessimistic. To quantify ``updated knowledge,'' we disintegrate the aleatoric and epistemic uncertainty in the agent's updated belief and show how the agent can use these estimates for decision-making. We compare the proposed approach with the multiple state-of-the-art approaches in decision-making across multiple well-established open-source problems and empirically show that our approach is faster and highly adaptive without sacrificing safety.
Decision Making in Non-Stationary Environments with Policy-Augmented Search
Jan 06, 2024



Sequential decision-making under uncertainty is present in many important problems. Two popular approaches for tackling such problems are reinforcement learning and online search (e.g., Monte Carlo tree search). While the former learns a policy by interacting with the environment (typically done before execution), the latter uses a generative model of the environment to sample promising action trajectories at decision time. Decision-making is particularly challenging in non-stationary environments, where the environment in which an agent operates can change over time. Both approaches have shortcomings in such settings -- on the one hand, policies learned before execution become stale when the environment changes and relearning takes both time and computational effort. Online search, on the other hand, can return sub-optimal actions when there are limitations on allowed runtime. In this paper, we introduce \textit{Policy-Augmented Monte Carlo tree search} (PA-MCTS), which combines action-value estimates from an out-of-date policy with an online search using an up-to-date model of the environment. We prove theoretical results showing conditions under which PA-MCTS selects the one-step optimal action and also bound the error accrued while following PA-MCTS as a policy. We compare and contrast our approach with AlphaZero, another hybrid planning approach, and Deep Q Learning on several OpenAI Gym environments. Through extensive experiments, we show that under non-stationary settings with limited time constraints, PA-MCTS outperforms these baselines.