 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Runtime Bound for the $(μ+ 1)$ EA on BinVal
Jun 11, 2026We study the $(μ+1)$ EA on the Binary Value function BinVal. We show that it needs at most $O(μ\log μ\cdot n \log n)$ function evaluations to find the optimum when $μ= o(n/\log n)$. This substantially improves upon the recent upper bound of $O(μ^5 n \log(n/μ^4))$ by Krejca, Neumann and Witt. Our results hold for several mutation operators including standard bit mutation. In particular, our bound implies that the $(μ+1)$ EA is at most a factor $O(\log μ\cdot \log n)$ slower on BinVal than on OneMax.
Runtime Analysis of the $(μ+ 1)$-ES in a Homogenous Progress Model
Jun 11, 2026We introduce a new simple model to study the fitness progress of Evolution Strategies (ES) in generic problems. In this model, we bypass the underlying fitness landscape and assume that the mutation of any individual produces an offspring whose fitness relative to the parent is given by an invariant distribution $Z$, such as a mean-shifted Gaussian. This serves as a prototypical model for the optimisation landscape when an evolution algorithm operates far from the global optimum. This simple model can be used to approximate the optimisation process for problems where it is intractable to model the exact fitness function, including tasks such as hyperparameter tuning in machine learning models. We rigorously analyse the expected growth rate $\mathcal{R}_μ$ of the continuous steady-state $(μ+1)$-ES in this model. Unlike comma-selection strategies, the steady-state $(μ+1)$-ES maintains overlapping generations, introducing complex mathematical dependencies among surviving parents that make it harder to analyse. We give a general technique to analyse the the $(μ+ 1)$-ES by constructing modified processes whose growth rates provably sandwich that of the original process. These modified processes are then easier to analyse but still close enough to the true process to give a tight bound on the expected growth rate. When $Z = \mathcal{N}(-δ, 1)$ and $μ\le e^δ$, we show that $\mathcal{R}_μ = \frac{\log^{1 + o(1)} μ}μ \mathcal{R}_1$.
The $(1 + 1)$-EA in Dynamic Environments
Jun 11, 2026We study the $(1 + 1)$-EA in dynamic linear environments, where in every generation selection is performed with respect to a freshly sampled linear function with positive weights. We consider the Dynamic Binary Value problem, where each generation uses a uniformly random permutation of $1,2,4,\dots,2^{n-1}$, and a Uniform weight variant, where the weights are drawn independently from $\mathrm{Unif}(0,1)$. Both of them have recently been integrated into the IOHprofiler platform and empirically studied. For both models we prove a sharp threshold in the mutation parameter $χ$ for mutation rate $χ/n$. Below the threshold, the expected optimisation time is $\mathcal{O}(n\log n)$, whereas above it the runtime becomes $2^{Ω(n)}$. For the Dynamic Binary Value problem in the exponential regime, we also quantify at what distance from the optimum the optimisation process stagnates. We show that there is a second threshold: a distance that is efficiently reached, but reaching any smaller distance takes exponential time. This quantifies and proves previous empirical findings.
Diversity-Preserving Exploitation of Crossover
Jul 02, 2025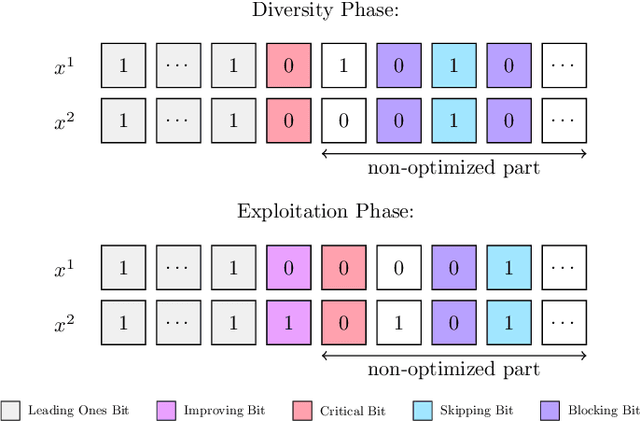


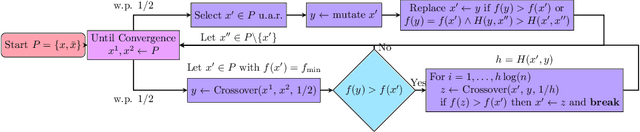
Crossover is a powerful mechanism for generating new solutions from a given population of solutions. Crossover comes with a discrepancy in itself: on the one hand, crossover usually works best if there is enough diversity in the population; on the other hand, exploiting the benefits of crossover reduces diversity. This antagonism often makes crossover reduce its own effectiveness. We introduce a new paradigm for utilizing crossover that reduces this antagonism, which we call diversity-preserving exploitation of crossover (DiPEC). The resulting Diversity Exploitation Genetic Algorithm (DEGA) is able to still exploit the benefits of crossover, but preserves a much higher diversity than conventional approaches. We demonstrate the benefits by proving that the (2+1)-DEGA finds the optimum of LeadingOnes with $O(n^{5/3}\log^{2/3} n)$ fitness evaluations. This is remarkable since standard genetic algorithms need $\Theta(n^2)$ evaluations, and among genetic algorithms only some artificial and specifically tailored algorithms were known to break this runtime barrier. We confirm the theoretical results by simulations. Finally, we show that the approach is not overfitted to Leadingones by testing it empirically on other benchmarks and showing that it is also competitive in other settings. We believe that our findings justify further systematic investigations of the DiPEC paradigm.
Humanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
Empirical Analysis of the Dynamic Binary Value Problem with IOHprofiler
Apr 24, 2024



Optimization problems in dynamic environments have recently been the source of several theoretical studies. One of these problems is the monotonic Dynamic Binary Value problem, which theoretically has high discriminatory power between different Genetic Algorithms. Given this theoretical foundation, we integrate several versions of this problem into the IOHprofiler benchmarking framework. Using this integration, we perform several large-scale benchmarking experiments to both recreate theoretical results on moderate dimensional problems and investigate aspects of GA's performance which have not yet been studied theoretically. Our results highlight some of the many synergies between theory and benchmarking and offer a platform through which further research into dynamic optimization problems can be performed.
Self-Adjusting Evolutionary Algorithms Are Slow on Multimodal Landscapes
Apr 18, 2024The one-fifth rule and its generalizations are a classical parameter control mechanism in discrete domains. They have also been transferred to control the offspring population size of the $(1, \lambda)$-EA. This has been shown to work very well for hill-climbing, and combined with a restart mechanism it was recently shown by Hevia Fajardo and Sudholt to improve performance on the multi-modal problem Cliff drastically. In this work we show that the positive results do not extend to other types of local optima. On the distorted OneMax benchmark, the self-adjusting $(1, \lambda)$-EA is slowed down just as elitist algorithms because self-adaptation prevents the algorithm from escaping from local optima. This makes the self-adaptive algorithm considerably worse than good static parameter choices, which do allow to escape from local optima efficiently. We show this theoretically and complement the result with empirical runtime results.
Faster Optimization Through Genetic Drift
Apr 18, 2024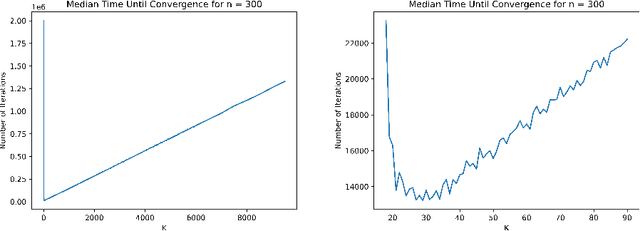
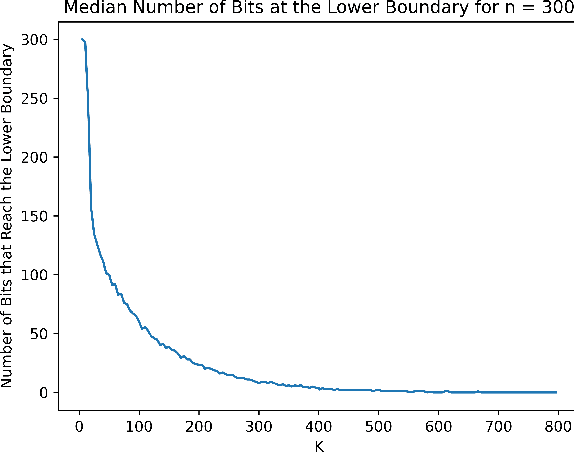
The compact Genetic Algorithm (cGA), parameterized by its hypothetical population size $K$, offers a low-memory alternative to evolving a large offspring population of solutions. It evolves a probability distribution, biasing it towards promising samples. For the classical benchmark OneMax, the cGA has to two different modes of operation: a conservative one with small step sizes $\Theta(1/(\sqrt{n}\log n))$, which is slow but prevents genetic drift, and an aggressive one with large step sizes $\Theta(1/\log n)$, in which genetic drift leads to wrong decisions, but those are corrected efficiently. On OneMax, an easy hill-climbing problem, both modes lead to optimization times of $\Theta(n\log n)$ and are thus equally efficient. In this paper we study how both regimes change when we replace OneMax by the harder hill-climbing problem DynamicBinVal. It turns out that the aggressive mode is not affected and still yields quasi-linear runtime $O(n\cdot polylog (n))$. However, the conservative mode becomes substantially slower, yielding a runtime of $\Omega(n^2)$, since genetic drift can only be avoided with smaller step sizes of $O(1/n)$. We complement our theoretical results with simulations.
How Population Diversity Influences the Efficiency of Crossover
Apr 18, 2024Our theoretical understanding of crossover is limited by our ability to analyze how population diversity evolves. In this study, we provide one of the first rigorous analyses of population diversity and optimization time in a setting where large diversity and large population sizes are required to speed up progress. We give a formal and general criterion which amount of diversity is necessary and sufficient to speed up the $(\mu+1)$ Genetic Algorithm on LeadingOnes. We show that the naturally evolving diversity falls short of giving a substantial speed-up for any $\mu=O(\sqrt{n}/\log^2 n)$. On the other hand, we show that even for $\mu=2$, if we simply break ties in favor of diversity then this increases diversity so much that optimization is accelerated by a constant factor.
Plus Strategies are Exponentially Slower for Planted Optima of Random Height
Apr 15, 2024



We compare the $(1,\lambda)$-EA and the $(1 + \lambda)$-EA on the recently introduced benchmark DisOM, which is the OneMax function with randomly planted local optima. Previous work showed that if all local optima have the same relative height, then the plus strategy never loses more than a factor $O(n\log n)$ compared to the comma strategy. Here we show that even small random fluctuations in the heights of the local optima have a devastating effect for the plus strategy and lead to super-polynomial runtimes. On the other hand, due to their ability to escape local optima, comma strategies are unaffected by the height of the local optima and remain efficient. Our results hold for a broad class of possible distortions and show that the plus strategy, but not the comma strategy, is generally deceived by sparse unstructured fluctuations of a smooth landscape.