 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretation of machine learning predictions for patient outcomes in electronic health records
Mar 14, 2019
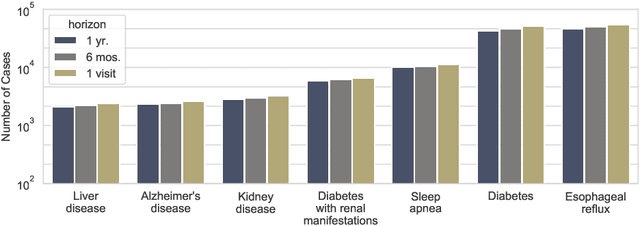
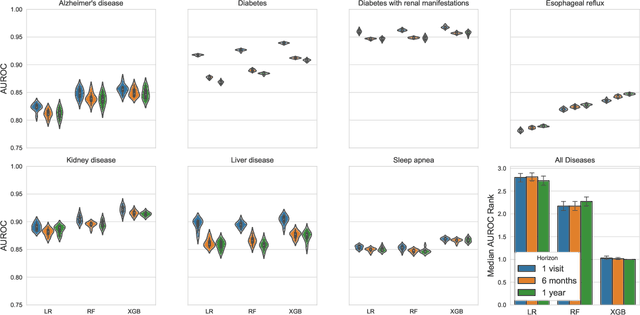
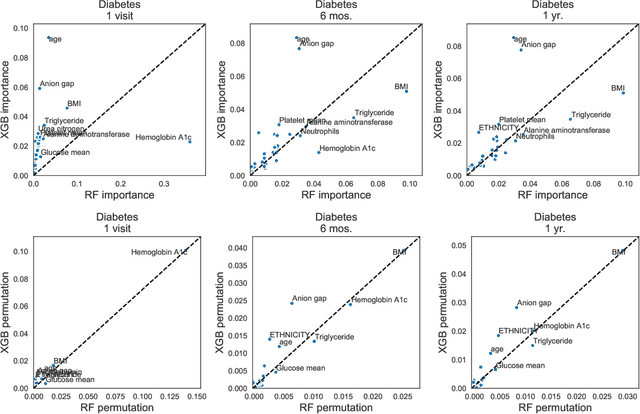
Electronic health records are an increasingly important resource for understanding the interactions between patient health, environment, and clinical decisions. In this paper we report an empirical study of predictive modeling of several patient outcomes using three state-of-the-art machine learning methods. Our primary goal is to validate the models by interpreting the importance of predictors in the final models. Central to interpretation is the use of feature importance scores, which vary depending on the underlying methodology. In order to assess feature importance, we compared univariate statistical tests, information-theoretic measures, permutation testing, and normalized coefficients from multivariate logistic regression models. In general we found poor correlation between methods in their assessment of feature importance, even when their performance is comparable and relatively good. However, permutation tests applied to random forest and gradient boosting models showed the most agreement, and the importance scores matched the clinical interpretation most frequently.