 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving TabPFN's Synthetic Data Generation by Integrating Causal Structure
Mar 10, 2026Synthetic tabular data generation addresses data scarcity and privacy constraints in a variety of domains. Tabular Prior-Data Fitted Network (TabPFN), a recent foundation model for tabular data, has been shown capable of generating high-quality synthetic tabular data. However, TabPFN is autoregressive: features are generated sequentially by conditioning on the previous ones, depending on the order in which they appear in the input data. We demonstrate that when the feature order conflicts with causal structure, the model produces spurious correlations that impair its ability to generate synthetic data and preserve causal effects. We address this limitation by integrating causal structure into TabPFN's generation process through two complementary approaches: Directed Acyclic Graph (DAG)-aware conditioning, which samples each variable given its causal parents, and a Completed Partially Directed Acyclic Graph (CPDAG)-based strategy for scenarios with partial causal knowledge. We evaluate these approaches on controlled benchmarks and six CSuite datasets, assessing structural fidelity, distributional alignment, privacy preservation, and Average Treatment Effect (ATE) preservation. Across most settings, DAG-aware conditioning improves the quality and stability of synthetic data relative to vanilla TabPFN. The CPDAG-based strategy shows moderate improvements, with effectiveness depending on the number of oriented edges. These results indicate that injecting causal structure into autoregressive generation enhances the reliability of synthetic tabular data.
Interpretable Non-linear Survival Analysis with Evolutionary Symbolic Regression
Apr 08, 2025Survival Regression (SuR) is a key technique for modeling time to event in important applications such as clinical trials and semiconductor manufacturing. Currently, SuR algorithms belong to one of three classes: non-linear black-box -- allowing adaptability to many datasets but offering limited interpretability (e.g., tree ensembles); linear glass-box -- being easier to interpret but limited to modeling only linear interactions (e.g., Cox proportional hazards); and non-linear glass-box -- allowing adaptability and interpretability, but empirically found to have several limitations (e.g., explainable boosting machines, survival trees). In this work, we investigate whether Symbolic Regression (SR), i.e., the automated search of mathematical expressions from data, can lead to non-linear glass-box survival models that are interpretable and accurate. We propose an evolutionary, multi-objective, and multi-expression implementation of SR adapted to SuR. Our empirical results on five real-world datasets show that SR consistently outperforms traditional glass-box methods for SuR in terms of accuracy per number of dimensions in the model, while exhibiting comparable accuracy with black-box methods. Furthermore, we offer qualitative examples to assess the interpretability potential of SR models for SuR. Code at: https://github.com/lurovi/SurvivalMultiTree-pyNSGP.
Deep Generative Symbolic Regression with Monte-Carlo-Tree-Search
Feb 22, 2023Symbolic regression (SR) is the problem of learning a symbolic expression from numerical data. Recently, deep neural models trained on procedurally-generated synthetic datasets showed competitive performance compared to more classical Genetic Programming (GP) algorithms. Unlike their GP counterparts, these neural approaches are trained to generate expressions from datasets given as context. This allows them to produce accurate expressions in a single forward pass at test time. However, they usually do not benefit from search abilities, which result in low performance compared to GP on out-of-distribution datasets. In this paper, we propose a novel method which provides the best of both worlds, based on a Monte-Carlo Tree Search procedure using a context-aware neural mutation model, which is initially pre-trained to learn promising mutations, and further refined from successful experiences in an online fashion. The approach demonstrates state-of-the-art performance on the well-known \texttt{SRBench} benchmark.
Symbolic Regression is NP-hard
Jul 11, 2022Symbolic regression (SR) is the task of learning a model of data in the form of a mathematical expression. By their nature, SR models have the potential to be accurate and human-interpretable at the same time. Unfortunately, finding such models, i.e., performing SR, appears to be a computationally intensive task. Historically, SR has been tackled with heuristics such as greedy or genetic algorithms and, while some works have hinted at the possible hardness of SR, no proof has yet been given that SR is, in fact, NP-hard. This begs the question: Is there an exact polynomial-time algorithm to compute SR models? We provide evidence suggesting that the answer is probably negative by showing that SR is NP-hard.
Coefficient Mutation in the Gene-pool Optimal Mixing Evolutionary Algorithm for Symbolic Regression
Apr 26, 2022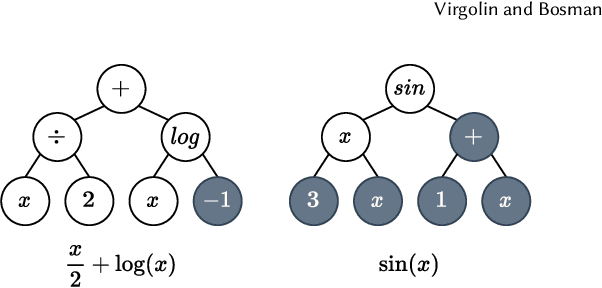
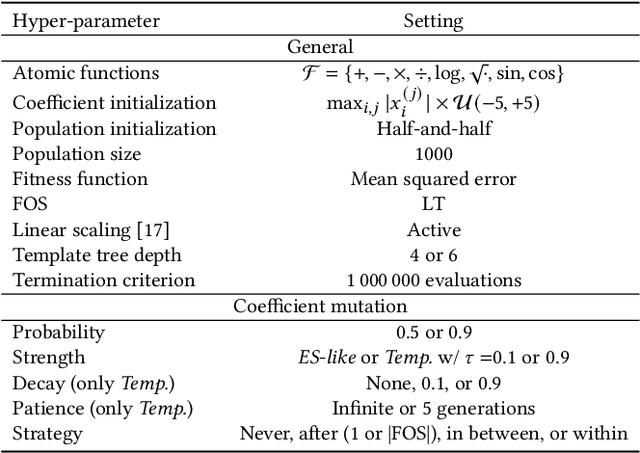
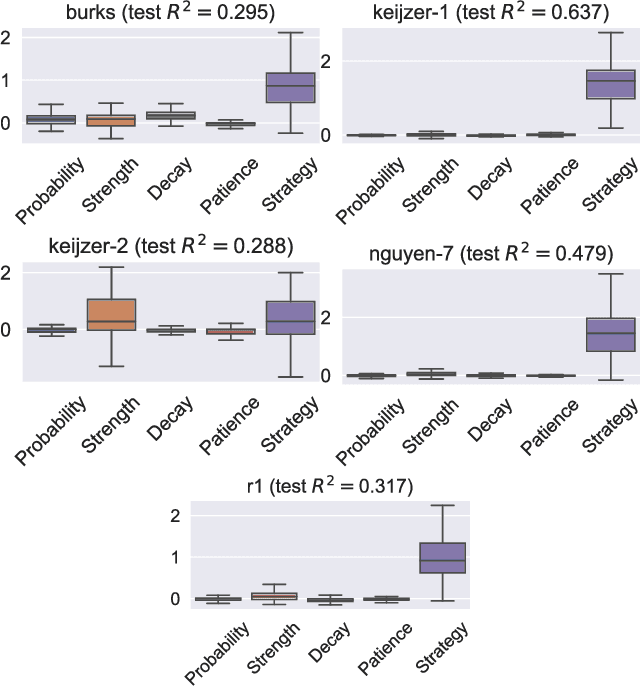
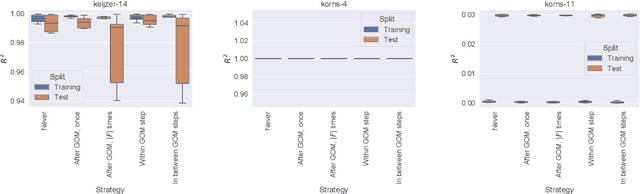
Currently, the genetic programming version of the gene-pool optimal mixing evolutionary algorithm (GP-GOMEA) is among the top-performing algorithms for symbolic regression (SR). A key strength of GP-GOMEA is its way of performing variation, which dynamically adapts to the emergence of patterns in the population. However, GP-GOMEA lacks a mechanism to optimize coefficients. In this paper, we study how fairly simple approaches for optimizing coefficients can be integrated into GP-GOMEA. In particular, we considered two variants of Gaussian coefficient mutation. We performed experiments using different settings on 23 benchmark problems, and used machine learning to estimate what aspects of coefficient mutation matter most. We find that the most important aspect is that the number of coefficient mutation attempts needs to be commensurate with the number of mixing operations that GP-GOMEA performs. We applied GP-GOMEA with the best-performing coefficient mutation approach to the data sets of SRBench, a large SR benchmark, for which a ground-truth underlying equation is known. We find that coefficient mutation can help re-discovering the underlying equation by a substantial amount, but only when no noise is added to the target variable. In the presence of noise, GP-GOMEA with coefficient mutation discovers alternative but similarly-accurate equations.
Less is More: A Call to Focus on Simpler Models in Genetic Programming for Interpretable Machine Learning
Apr 05, 2022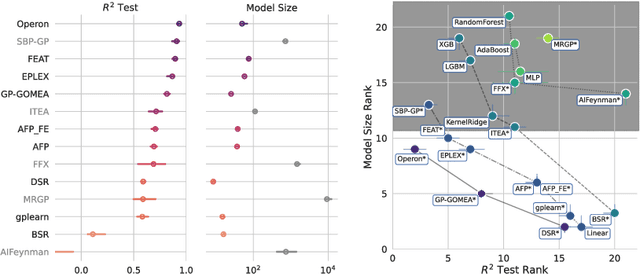
Interpretability can be critical for the safe and responsible use of machine learning models in high-stakes applications. So far, evolutionary computation (EC), in particular in the form of genetic programming (GP), represents a key enabler for the discovery of interpretable machine learning (IML) models. In this short paper, we argue that research in GP for IML needs to focus on searching in the space of low-complexity models, by investigating new kinds of search strategies and recombination methods. Moreover, based on our experience of bringing research into clinical practice, we believe that research should strive to design better ways of modeling and pursuing interpretability, for the obtained solutions to ultimately be most useful.
On genetic programming representations and fitness functions for interpretable dimensionality reduction
Mar 14, 2022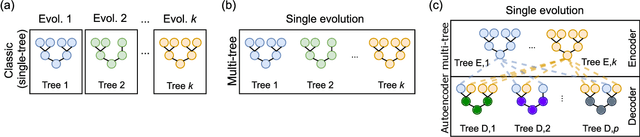
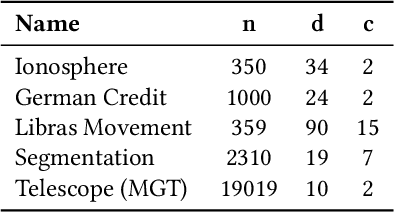

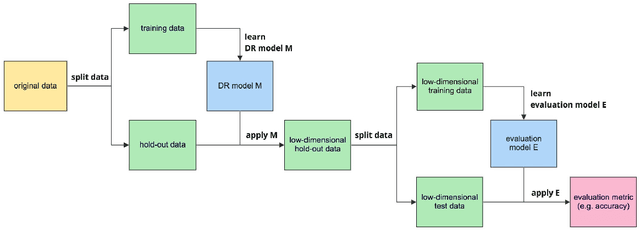
Dimensionality reduction (DR) is an important technique for data exploration and knowledge discovery. However, most of the main DR methods are either linear (e.g., PCA), do not provide an explicit mapping between the original data and its lower-dimensional representation (e.g., MDS, t-SNE, isomap), or produce mappings that cannot be easily interpreted (e.g., kernel PCA, neural-based autoencoder). Recently, genetic programming (GP) has been used to evolve interpretable DR mappings in the form of symbolic expressions. There exists a number of ways in which GP can be used to this end and no study exists that performs a comparison. In this paper, we fill this gap by comparing existing GP methods as well as devising new ones. We evaluate our methods on several benchmark datasets based on predictive accuracy and on how well the original features can be reconstructed using the lower-dimensional representation only. Finally, we qualitatively assess the resulting expressions and their complexity. We find that various GP methods can be competitive with state-of-the-art DR algorithms and that they have the potential to produce interpretable DR mappings.
Evolvability Degeneration in Multi-Objective Genetic Programming for Symbolic Regression
Feb 16, 2022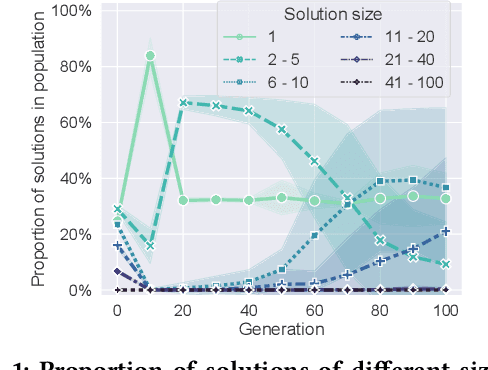

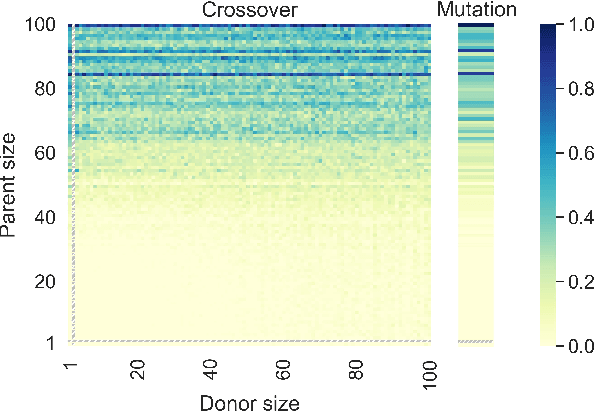
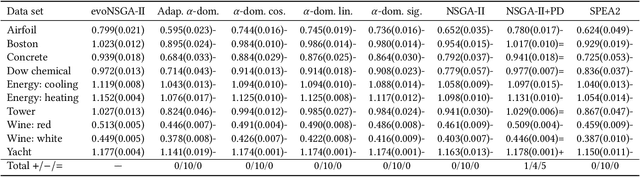
Genetic programming (GP) is one of the best approaches today to discover symbolic regression models. To find models that trade off accuracy and complexity, the non-dominated sorting genetic algorithm II (NSGA-II) is widely used. Unfortunately, it has been shown that NSGA-II can be inefficient: in early generations, low-complexity models over-replicate and take over most of the population. Consequently, studies have proposed different approaches to promote diversity. Here, we study the root of this problem, in order to design a superior approach. We find that the over-replication of low complexity-models is due to a lack of evolvability, i.e., the inability to produce offspring with improved accuracy. We therefore extend NSGA-II to track, over time, the evolvability of models of different levels of complexity. With this information, we limit how many models of each complexity level are allowed to survive the generation. We compare this new version of NSGA-II, evoNSGA-II, with the use of seven existing multi-objective GP approaches on ten widely-used data sets, and find that evoNSGA-II is equal or superior to using these approaches in almost all comparisons. Furthermore, our results confirm that evoNSGA-II behaves as intended: models that are more evolvable form the majority of the population.
Adults as Augmentations for Children in Facial Emotion Recognition with Contrastive Learning
Feb 10, 2022



Emotion recognition in children can help the early identification of, and intervention on, psychological complications that arise in stressful situations such as cancer treatment. Though deep learning models are increasingly being adopted, data scarcity is often an issue in pediatric medicine, including for facial emotion recognition in children. In this paper, we study the application of data augmentation-based contrastive learning to overcome data scarcity in facial emotion recognition for children. We explore the idea of ignoring generational gaps, by adding abundantly available adult data to pediatric data, to learn better representations. We investigate different ways by which adult facial expression images can be used alongside those of children. In particular, we propose to explicitly incorporate within each mini-batch adult images as augmentations for children's. Out of $84$ combinations of learning approaches and training set sizes, we find that supervised contrastive learning with the proposed training scheme performs best, reaching a test accuracy that typically surpasses the one of the second-best approach by 2% to 3%. Our results indicate that adult data can be considered to be a meaningful augmentation of pediatric data for the recognition of emotional facial expression in children, and open up the possibility for other applications of contrastive learning to improve pediatric care by complementing data of children with that of adults.
Conversational Agents: Theory and Applications
Feb 07, 2022

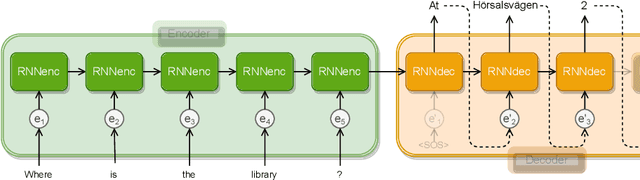
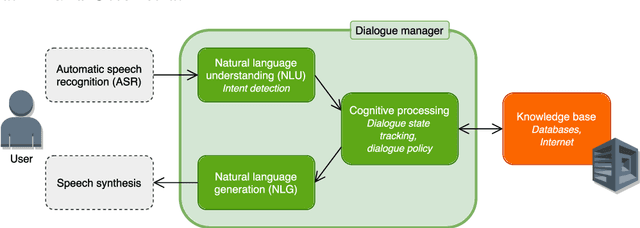
In this chapter, we provide a review of conversational agents (CAs), discussing chatbots, intended for casual conversation with a user, as well as task-oriented agents that generally engage in discussions intended to reach one or several specific goals, often (but not always) within a specific domain. We also consider the concept of embodied conversational agents, briefly reviewing aspects such as character animation and speech processing. The many different approaches for representing dialogue in CAs are discussed in some detail, along with methods for evaluating such agents, emphasizing the important topics of accountability and interpretability. A brief historical overview is given, followed by an extensive overview of various applications, especially in the fields of health and education. We end the chapter by discussing benefits and potential risks regarding the societal impact of current and future CA technology.