 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-linear PCA via Evolution Strategies: a Novel Objective Function
Feb 03, 2026Principal Component Analysis (PCA) is a powerful and popular dimensionality reduction technique. However, due to its linear nature, it often fails to capture the complex underlying structure of real-world data. While Kernel PCA (kPCA) addresses non-linearity, it sacrifices interpretability and struggles with hyperparameter selection. In this paper, we propose a robust non-linear PCA framework that unifies the interpretability of PCA with the flexibility of neural networks. Our method parametrizes variable transformations via neural networks, optimized using Evolution Strategies (ES) to handle the non-differentiability of eigendecomposition. We introduce a novel, granular objective function that maximizes the individual variance contribution of each variable providing a stronger learning signal than global variance maximization. This approach natively handles categorical and ordinal variables without the dimensional explosion associated with one-hot encoding. We demonstrate that our method significantly outperforms both linear PCA and kPCA in explained variance across synthetic and real-world datasets. At the same time, it preserves PCA's interpretability, enabling visualization and analysis of feature contributions using standard tools such as biplots. The code can be found on GitHub.
On Debiasing Text Embeddings Through Context Injection
Oct 14, 2024Current advances in NLP has made it increasingly feasible to build applications leveraging textual data. Generally, the core of these applications rely on having a good semantic representation of text into vectors, via specialized embedding models. However, it has been shown that these embeddings capture and perpetuate biases already present in text. While a few techniques have been proposed to debias embeddings, they do not take advantage of the recent advances in context understanding of the modern embedding models. In this paper, we fill this gap by conducting a review of 19 embedding models by quantifying their biases and how well they respond to context injection as a mean of debiasing. We show that higher performing embedding models are more prone to capturing common biases, but are also better able to incorporate context. Surprisingly, we find that while models can easily embed affirmative context, they fail at embedding neutral semantics. Finally, in a retrieval task, we show that biases in embeddings can lead to non-desirable outcomes. We use our new-found insights to design a simple algorithm for top $k$ retrieval where $k$ is dynamically selected.
On genetic programming representations and fitness functions for interpretable dimensionality reduction
Mar 14, 2022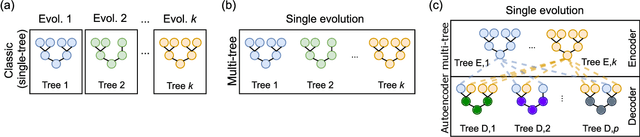
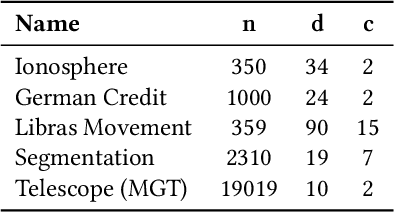

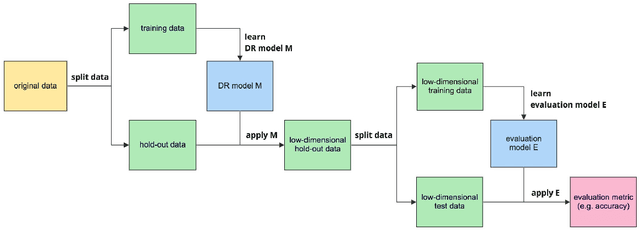
Dimensionality reduction (DR) is an important technique for data exploration and knowledge discovery. However, most of the main DR methods are either linear (e.g., PCA), do not provide an explicit mapping between the original data and its lower-dimensional representation (e.g., MDS, t-SNE, isomap), or produce mappings that cannot be easily interpreted (e.g., kernel PCA, neural-based autoencoder). Recently, genetic programming (GP) has been used to evolve interpretable DR mappings in the form of symbolic expressions. There exists a number of ways in which GP can be used to this end and no study exists that performs a comparison. In this paper, we fill this gap by comparing existing GP methods as well as devising new ones. We evaluate our methods on several benchmark datasets based on predictive accuracy and on how well the original features can be reconstructed using the lower-dimensional representation only. Finally, we qualitatively assess the resulting expressions and their complexity. We find that various GP methods can be competitive with state-of-the-art DR algorithms and that they have the potential to produce interpretable DR mappings.
Spacecraft Collision Avoidance Challenge: design and results of a machine learning competition
Aug 07, 2020
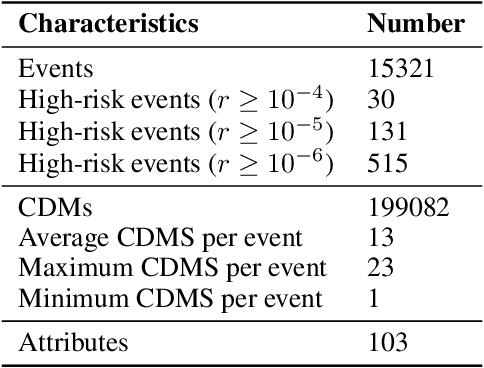
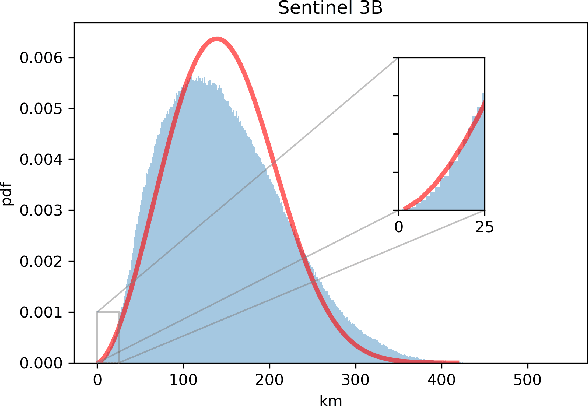

Spacecraft collision avoidance procedures have become an essential part of satellite operations. Complex and constantly updated estimates of the collision risk between orbiting objects inform the various operators who can then plan risk mitigation measures. Such measures could be aided by the development of suitable machine learning models predicting, for example, the evolution of the collision risk in time. In an attempt to study this opportunity, the European Space Agency released, in October 2019, a large curated dataset containing information about close approach events, in the form of Conjunction Data Messages (CDMs), collected from 2015 to 2019. This dataset was used in the Spacecraft Collision Avoidance Challenge, a machine learning competition where participants had to build models to predict the final collision risk between orbiting objects. This paper describes the design and results of the competition and discusses the challenges and lessons learned when applying machine learning methods to this problem domain.
Safe Crossover of Neural Networks Through Neuron Alignment
Mar 24, 2020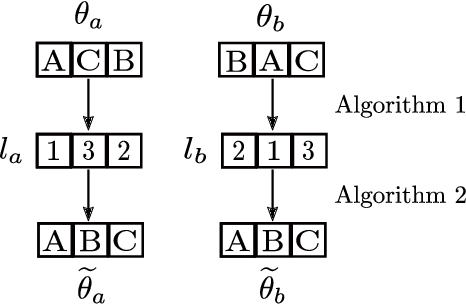
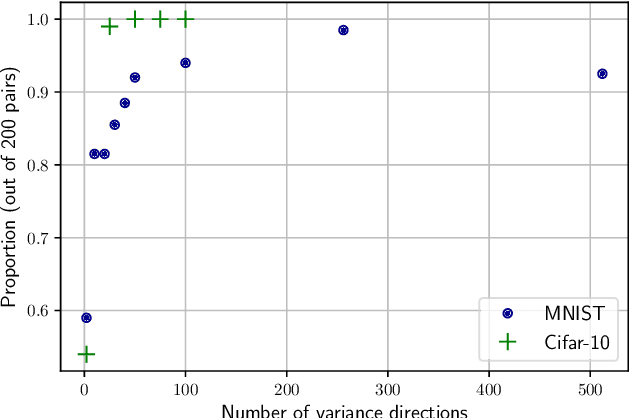
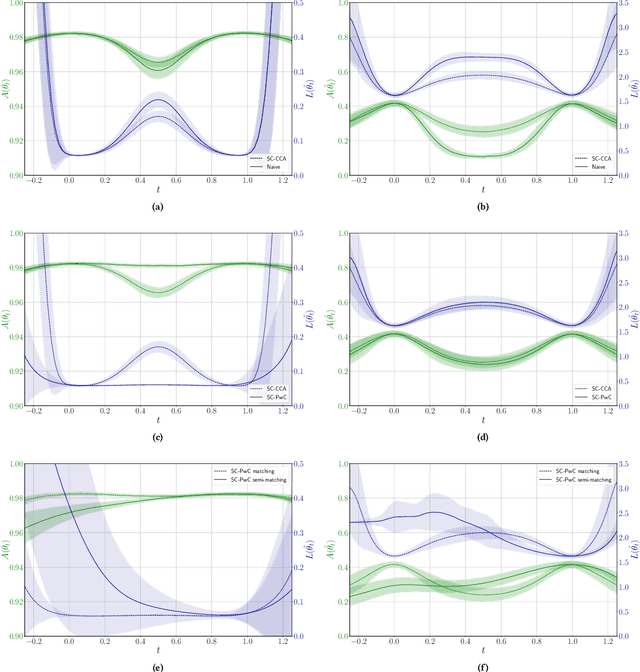

One of the main and largely unexplored challenges in evolving the weights of neural networks using genetic algorithms is to find a sensible crossover operation between parent networks. Indeed, naive crossover leads to functionally damaged offspring that do not retain information from the parents. This is because neural networks are invariant to permutations of neurons, giving rise to multiple ways of representing the same solution. This is often referred to as the competing conventions problem. In this paper, we propose a two-step safe crossover(SC) operator. First, the neurons of the parents are functionally aligned by computing how well they correlate, and only then are the parents recombined. We compare two ways of measuring relationships between neurons: Pairwise Correlation (PwC) and Canonical Correlation Analysis (CCA). We test our safe crossover operators (SC-PwC and SC-CCA) on MNIST and CIFAR-10 by performing arithmetic crossover on the weights of feed-forward neural network pairs. We show that it effectively transmits information from parents to offspring and significantly improves upon naive crossover. Our method is computationally fast,can serve as a way to explore the fitness landscape more efficiently and makes safe crossover a potentially promising operator in future neuroevolution research and applications.
Kernel Mean Embedding of Instance-wise Predictions in Multiple Instance Regression
Apr 24, 2019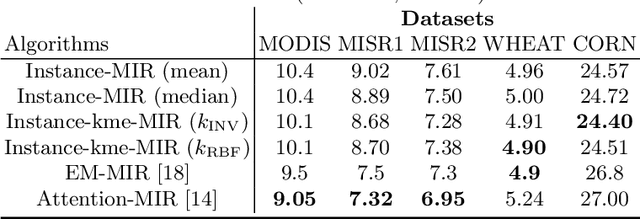
In this paper, we propose an extension to an existing algorithm (instance-MIR) which tackles the multiple instance regression (MIR) problem, also known as distribution regression. The MIR setting arises when the data is a collection of bags, where each bag consists of several instances which correspond to the same and unique real-valued label. The goal of a MIR algorithm is to find a mapping from the instances of an unseen bag to its target value. The instance-MIR algorithm treats all the instances separately and maps each instance to a label. The final bag label is then taken as the mean or the median of the predictions for that given bag. While it is conceptually simple, taking a single statistic to summarize the distribution of the labels in each bag is a limitation. In spite of this performance bottleneck, the instance-MIR algorithm has been shown to be competitive when compared to the current state-of-the-art methods. We address the aforementioned issue by computing the kernel mean embeddings of the distributions of the predicted labels, for each bag, and learn a regressor from these embeddings to the bag label. We test our algorithm (instance-kme-MIR) on five real world datasets and obtain better results than the baseline instance-MIR across all the datasets, while achieving state-of-the-art results on two of the datasets.
Learning with Sets in Multiple Instance Regression Applied to Remote Sensing
Mar 18, 2019
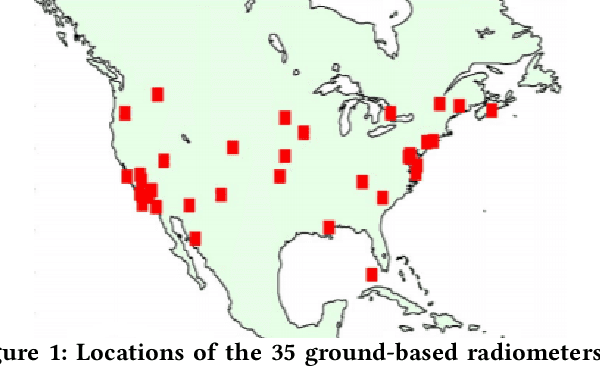
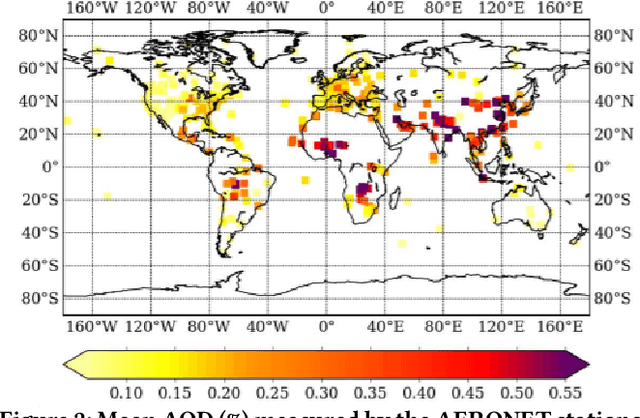
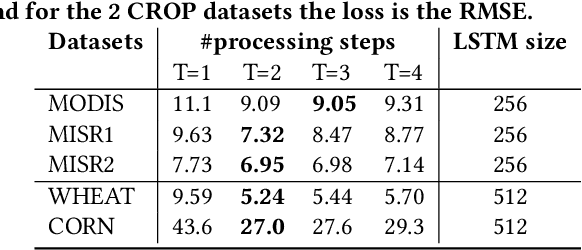
In this paper, we propose a novel approach to tackle the multiple instance regression (MIR) problem. This problem arises when the data is a collection of bags, where each bag is made of multiple instances corresponding to the same unique real-valued label. Our goal is to train a regression model which maps the instances of an unseen bag to its unique label. This MIR setting is common to remote sensing applications where there is high variability in the measurements and low geographical variability in the quantity being estimated. Our approach, in contrast to most competing methods, does not make the assumption that there exists a prime instance responsible for the label in each bag. Instead, we treat each bag as a set (i.e, an unordered sequence) of instances and learn to map each bag to its unique label by using all the instances in each bag. This is done by implementing an order-invariant operation characterized by a particular type of attention mechanism. This method is very flexible as it does not require domain knowledge nor does it make any assumptions about the distribution of the instances within each bag. We test our algorithm on five real world datasets and outperform previous state-of-the-art on three of the datasets. In addition, we augment our feature space by adding the moments of each feature for each bag, as extra features, and show that while the first moments lead to higher accuracy, there is a diminishing return.