 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Robustness of Counterfactual Explanations to Adverse Perturbations
Paper and Code
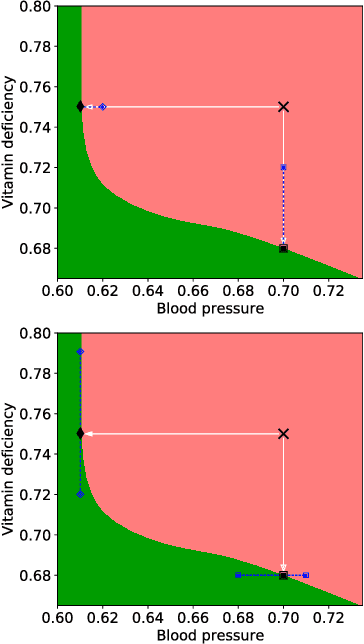



Counterfactual explanations (CEs) are a powerful means for understanding how decisions made by algorithms can be changed. Researchers have proposed a number of desiderata that CEs should meet to be practically useful, such as requiring minimal effort to enact, or complying with causal models. We consider a further aspect to improve the usability of CEs: robustness to adverse perturbations, which may naturally happen due to unfortunate circumstances. Since CEs typically prescribe a sparse form of intervention (i.e., only a subset of the features should be changed), we provide two definitions of robustness, which concern, respectively, the features to change and to keep as they are. These definitions are workable in that they can be incorporated as penalty terms in the loss functions that are used for discovering CEs. To experiment with the proposed definitions of robustness, we create and release code where five data sets (commonly used in the field of fair and explainable machine learning) have been enriched with feature-specific annotations that can be used to sample meaningful perturbations. Our experiments show that CEs are often not robust and, if adverse perturbations take place, the intervention they prescribe may require a much larger cost than anticipated, or even become impossible. However, accounting for robustness in the search process, which can be done rather easily, allows discovering robust CEs systematically. Robust CEs are resilient to adverse perturbations: additional intervention to contrast perturbations is much less costly than for non-robust CEs. Our code is available at: https://github.com/marcovirgolin/robust-counterfactuals