 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedGUIDE: Benchmarking Clinical Decision-Making in Large Language Models
May 16, 2025



Clinical guidelines, typically structured as decision trees, are central to evidence-based medical practice and critical for ensuring safe and accurate diagnostic decision-making. However, it remains unclear whether Large Language Models (LLMs) can reliably follow such structured protocols. In this work, we introduce MedGUIDE, a new benchmark for evaluating LLMs on their ability to make guideline-consistent clinical decisions. MedGUIDE is constructed from 55 curated NCCN decision trees across 17 cancer types and uses clinical scenarios generated by LLMs to create a large pool of multiple-choice diagnostic questions. We apply a two-stage quality selection process, combining expert-labeled reward models and LLM-as-a-judge ensembles across ten clinical and linguistic criteria, to select 7,747 high-quality samples. We evaluate 25 LLMs spanning general-purpose, open-source, and medically specialized models, and find that even domain-specific LLMs often underperform on tasks requiring structured guideline adherence. We also test whether performance can be improved via in-context guideline inclusion or continued pretraining. Our findings underscore the importance of MedGUIDE in assessing whether LLMs can operate safely within the procedural frameworks expected in real-world clinical settings.
Disparities in LLM Reasoning Accuracy and Explanations: A Case Study on African American English
Mar 06, 2025Large Language Models (LLMs) have demonstrated remarkable capabilities in reasoning tasks, leading to their widespread deployment. However, recent studies have highlighted concerning biases in these models, particularly in their handling of dialectal variations like African American English (AAE). In this work, we systematically investigate dialectal disparities in LLM reasoning tasks. We develop an experimental framework comparing LLM performance given Standard American English (SAE) and AAE prompts, combining LLM-based dialect conversion with established linguistic analyses. We find that LLMs consistently produce less accurate responses and simpler reasoning chains and explanations for AAE inputs compared to equivalent SAE questions, with disparities most pronounced in social science and humanities domains. These findings highlight systematic differences in how LLMs process and reason about different language varieties, raising important questions about the development and deployment of these systems in our multilingual and multidialectal world. Our code repository is publicly available at https://github.com/Runtaozhou/dialect_bias_eval.
ProAI: Proactive Multi-Agent Conversational AI with Structured Knowledge Base for Psychiatric Diagnosis
Feb 28, 2025Most LLM-driven conversational AI systems operate reactively, responding to user prompts without guiding the interaction. Most LLM-driven conversational AI systems operate reactively, responding to user prompts without guiding the interaction. However, many real-world applications-such as psychiatric diagnosis, consulting, and interviews-require AI to take a proactive role, asking the right questions and steering conversations toward specific objectives. Using mental health differential diagnosis as an application context, we introduce ProAI, a goal-oriented, proactive conversational AI framework. ProAI integrates structured knowledge-guided memory, multi-agent proactive reasoning, and a multi-faceted evaluation strategy, enabling LLMs to engage in clinician-style diagnostic reasoning rather than simple response generation. Through simulated patient interactions, user experience assessment, and professional clinical validation, we demonstrate that ProAI achieves up to 83.3% accuracy in mental disorder differential diagnosis while maintaining professional and empathetic interaction standards. These results highlight the potential for more reliable, adaptive, and goal-driven AI diagnostic assistants, advancing LLMs beyond reactive dialogue systems.
Dynamic Self-Consistency: Leveraging Reasoning Paths for Efficient LLM Sampling
Aug 30, 2024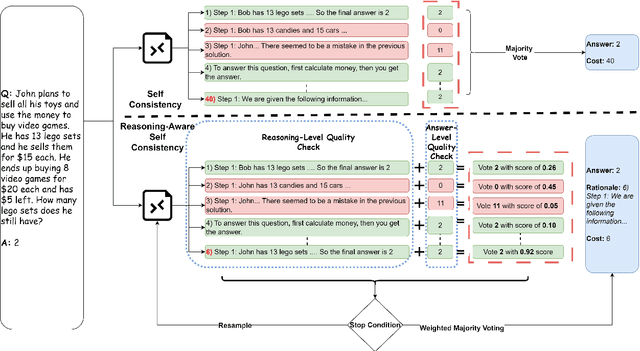
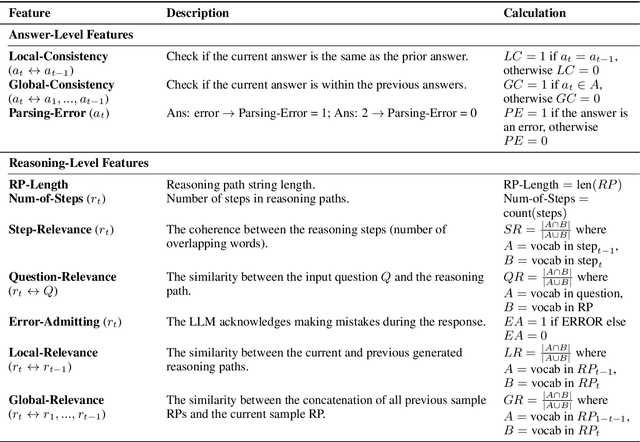
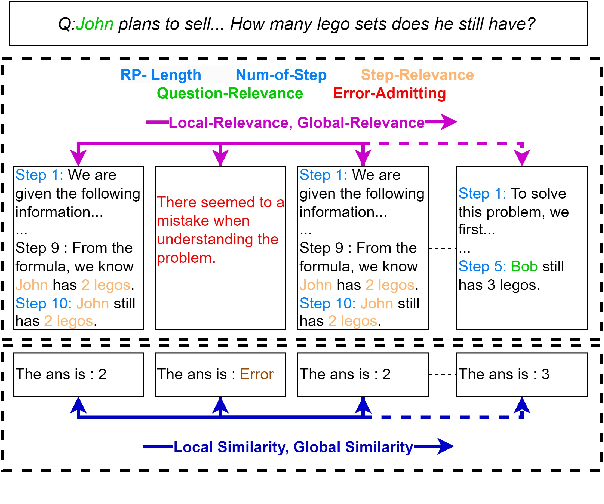
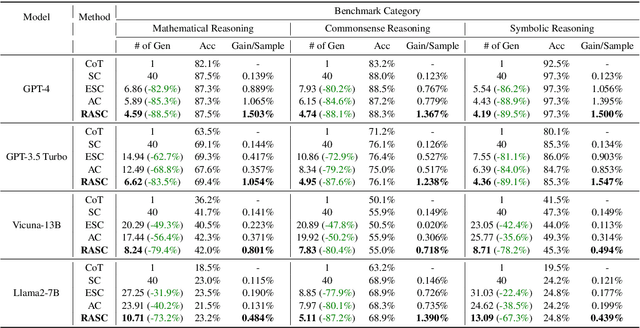
Self-Consistency (SC) is a widely used method to mitigate hallucinations in Large Language Models (LLMs) by sampling the LLM multiple times and outputting the most frequent solution. Despite its benefits, SC results in significant computational costs proportional to the number of samples generated. Previous early-stopping approaches, such as Early Stopping Self Consistency and Adaptive Consistency, have aimed to reduce these costs by considering output consistency, but they do not analyze the quality of the reasoning paths (RPs) themselves. To address this issue, we propose Reasoning-Aware Self-Consistency (RASC), an innovative early-stopping framework that dynamically adjusts the number of sample generations by considering both the output answer and the RPs from Chain of Thought (CoT) prompting. RASC assigns confidence scores sequentially to the generated samples, stops when certain criteria are met, and then employs weighted majority voting to optimize sample usage and enhance answer reliability. We comprehensively test RASC with multiple LLMs across varied QA datasets. RASC outperformed existing methods and significantly reduces sample usage by an average of 80% while maintaining or improving accuracy up to 5% compared to the original SC
CoT Rerailer: Enhancing the Reliability of Large Language Models in Complex Reasoning Tasks through Error Detection and Correction
Aug 25, 2024Chain-of-Thought (CoT) prompting enhances Large Language Models (LLMs) complex reasoning abilities by generating intermediate steps. However, these steps can introduce hallucinations and accumulate errors. We propose the CoT Rerailer to address these challenges, employing self-consistency and multi-agent debate systems to identify and rectify errors in the reasoning process. The CoT Rerailer first selects the most logically correct Reasoning Path (RP) using consistency checks and critical evaluation by automated agents. It then engages a multi-agent debate system to propose and validate corrections to ensure the generation of an error-free intermediate logical path. The corrected steps are then used to generate a revised reasoning chain to further reduce hallucinations and enhance answer quality. We demonstrate the effectiveness of our approach across diverse question-answering datasets in various knowledge domains. The CoT Rerailer enhances the reliability of LLM-generated reasoning, contributing to more trustworthy AI driven decision-making processes.
Bridging Causal Discovery and Large Language Models: A Comprehensive Survey of Integrative Approaches and Future Directions
Feb 16, 2024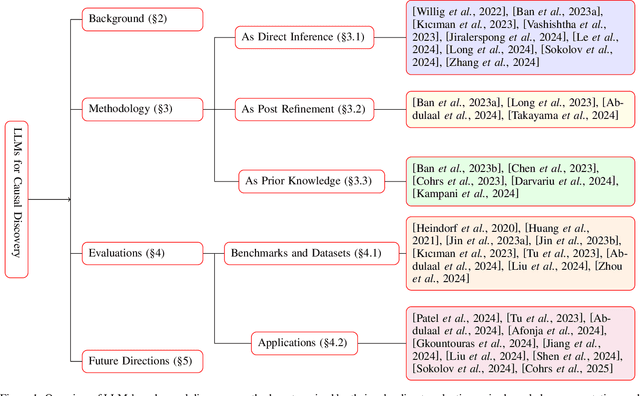

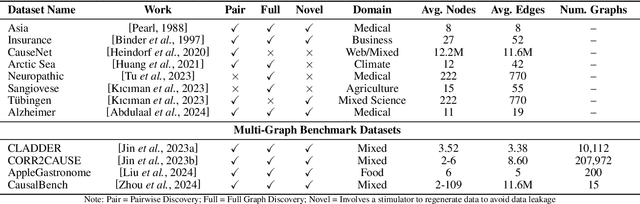
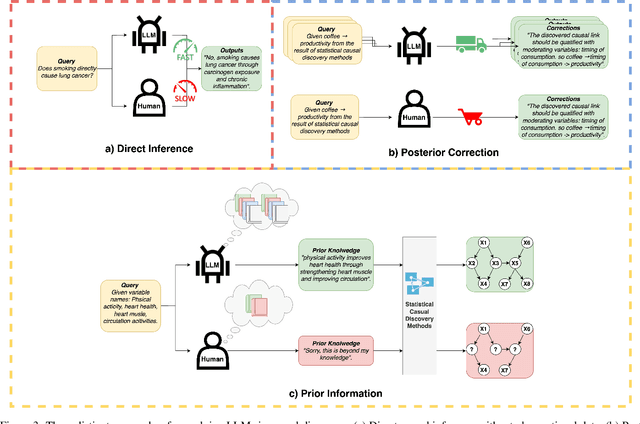
Causal discovery (CD) and Large Language Models (LLMs) represent two emerging fields of study with significant implications for artificial intelligence. Despite their distinct origins, CD focuses on uncovering cause-effect relationships from data, and LLMs on processing and generating humanlike text, the convergence of these domains offers novel insights and methodologies for understanding complex systems. This paper presents a comprehensive survey of the integration of LLMs, such as GPT4, into CD tasks. We systematically review and compare existing approaches that leverage LLMs for various CD tasks and highlight their innovative use of metadata and natural language to infer causal structures. Our analysis reveals the strengths and potential of LLMs in both enhancing traditional CD methods and as an imperfect expert, alongside the challenges and limitations inherent in current practices. Furthermore, we identify gaps in the literature and propose future research directions aimed at harnessing the full potential of LLMs in causality research. To our knowledge, this is the first survey to offer a unified and detailed examination of the synergy between LLMs and CD, setting the stage for future advancements in the field.
Proportional Multicalibration
Sep 29, 2022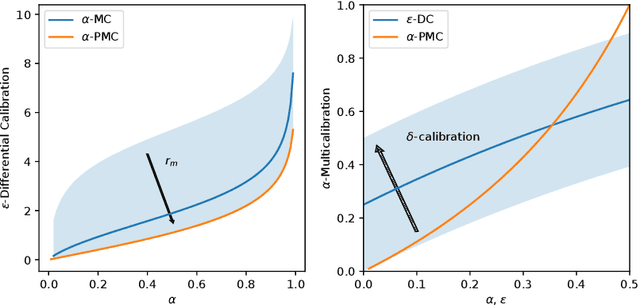

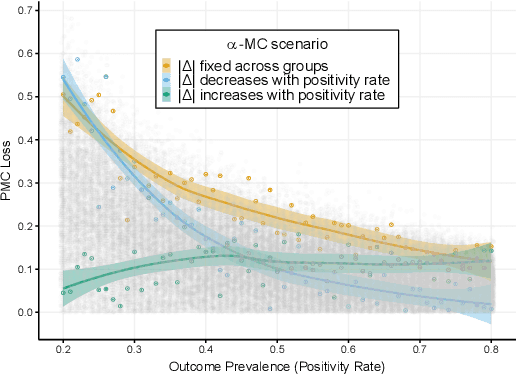
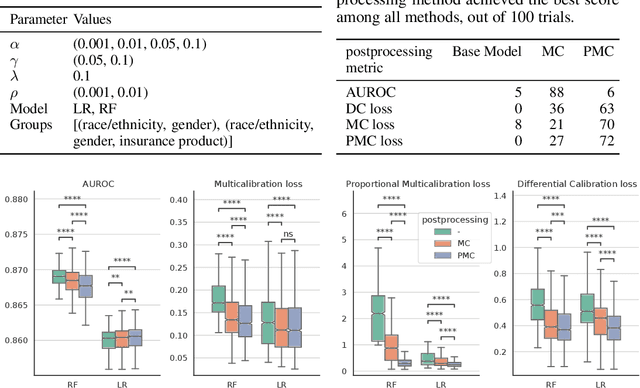
Multicalibration is a desirable fairness criteria that constrains calibration error among flexibly-defined groups in the data while maintaining overall calibration. However, when outcome probabilities are correlated with group membership, multicalibrated models can exhibit a higher percent calibration error among groups with lower base rates than groups with higher base rates. As a result, it remains possible for a decision-maker to learn to trust or distrust model predictions for specific groups. To alleviate this, we propose proportional multicalibration, a criteria that constrains the percent calibration error among groups and within prediction bins. We prove that satisfying proportional multicalibration bounds a model's multicalibration as well its differential calibration, a stronger fairness criteria inspired by the fairness notion of sufficiency. We provide an efficient algorithm for post-processing risk prediction models for proportional multicalibration and evaluate it empirically. We conduct simulation studies and investigate a real-world application of PMC-postprocessing to prediction of emergency department patient admissions. We observe that proportional multicalibration is a promising criteria for controlling simultenous measures of calibration fairness of a model over intersectional groups with virtually no cost in terms of classification performance.