 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProAI: Proactive Multi-Agent Conversational AI with Structured Knowledge Base for Psychiatric Diagnosis
Feb 28, 2025Most LLM-driven conversational AI systems operate reactively, responding to user prompts without guiding the interaction. Most LLM-driven conversational AI systems operate reactively, responding to user prompts without guiding the interaction. However, many real-world applications-such as psychiatric diagnosis, consulting, and interviews-require AI to take a proactive role, asking the right questions and steering conversations toward specific objectives. Using mental health differential diagnosis as an application context, we introduce ProAI, a goal-oriented, proactive conversational AI framework. ProAI integrates structured knowledge-guided memory, multi-agent proactive reasoning, and a multi-faceted evaluation strategy, enabling LLMs to engage in clinician-style diagnostic reasoning rather than simple response generation. Through simulated patient interactions, user experience assessment, and professional clinical validation, we demonstrate that ProAI achieves up to 83.3% accuracy in mental disorder differential diagnosis while maintaining professional and empathetic interaction standards. These results highlight the potential for more reliable, adaptive, and goal-driven AI diagnostic assistants, advancing LLMs beyond reactive dialogue systems.
Towards Understanding Retrieval Accuracy and Prompt Quality in RAG Systems
Nov 29, 2024Retrieval-Augmented Generation (RAG) is a pivotal technique for enhancing the capability of large language models (LLMs) and has demonstrated promising efficacy across a diverse spectrum of tasks. While LLM-driven RAG systems show superior performance, they face unique challenges in stability and reliability. Their complexity hinders developers' efforts to design, maintain, and optimize effective RAG systems. Therefore, it is crucial to understand how RAG's performance is impacted by its design. In this work, we conduct an early exploratory study toward a better understanding of the mechanism of RAG systems, covering three code datasets, three QA datasets, and two LLMs. We focus on four design factors: retrieval document type, retrieval recall, document selection, and prompt techniques. Our study uncovers how each factor impacts system correctness and confidence, providing valuable insights for developing an accurate and reliable RAG system. Based on these findings, we present nine actionable guidelines for detecting defects and optimizing the performance of RAG systems. We hope our early exploration can inspire further advancements in engineering, improving and maintaining LLM-driven intelligent software systems for greater efficiency and reliability.
Beyond Fidelity: Explaining Vulnerability Localization of Learning-based Detectors
Jan 05, 2024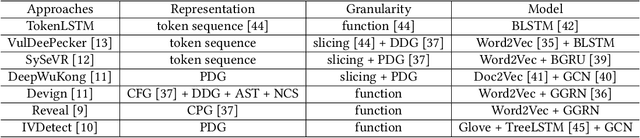
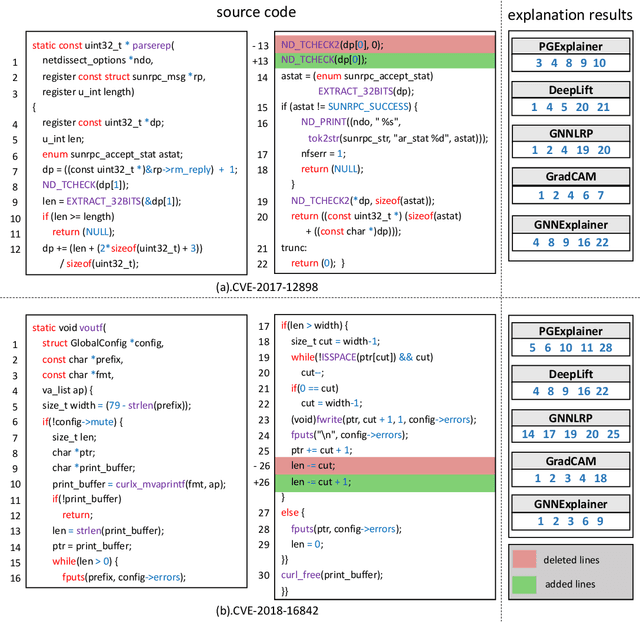
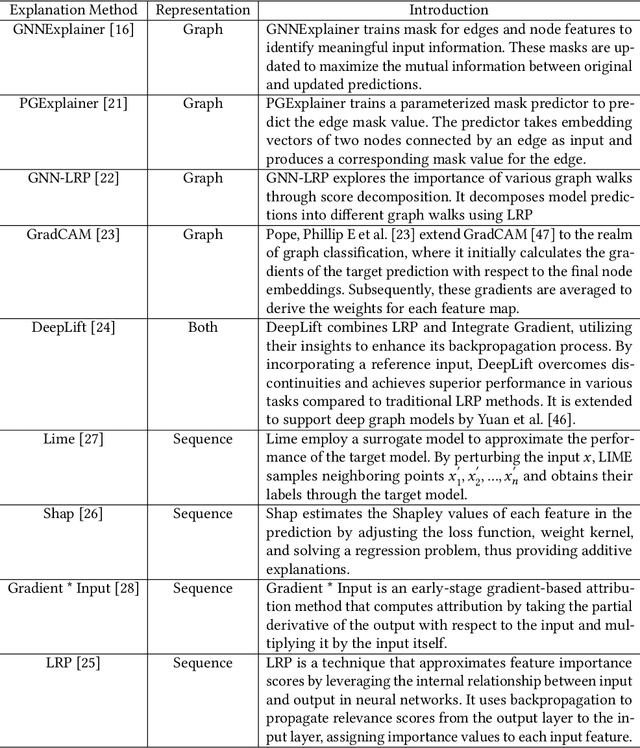
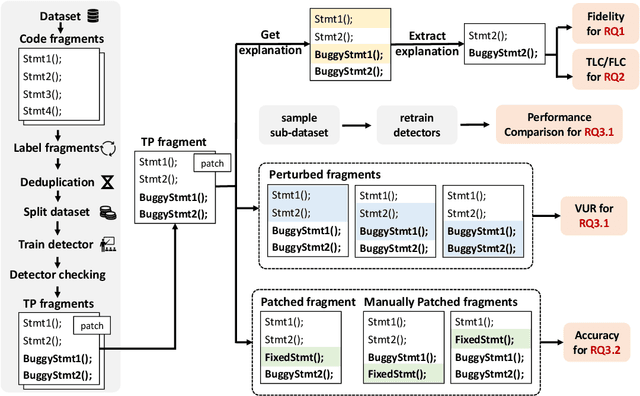
Vulnerability detectors based on deep learning (DL) models have proven their effectiveness in recent years. However, the shroud of opacity surrounding the decision-making process of these detectors makes it difficult for security analysts to comprehend. To address this, various explanation approaches have been proposed to explain the predictions by highlighting important features, which have been demonstrated effective in other domains such as computer vision and natural language processing. Unfortunately, an in-depth evaluation of vulnerability-critical features, such as fine-grained vulnerability-related code lines, learned and understood by these explanation approaches remains lacking. In this study, we first evaluate the performance of ten explanation approaches for vulnerability detectors based on graph and sequence representations, measured by two quantitative metrics including fidelity and vulnerability line coverage rate. Our results show that fidelity alone is not sufficient for evaluating these approaches, as fidelity incurs significant fluctuations across different datasets and detectors. We subsequently check the precision of the vulnerability-related code lines reported by the explanation approaches, and find poor accuracy in this task among all of them. This can be attributed to the inefficiency of explainers in selecting important features and the presence of irrelevant artifacts learned by DL-based detectors.