 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFactorEngine: A Program-level Knowledge-Infused Factor Mining Framework for Quantitative Investment
Mar 17, 2026We study alpha factor mining, the automated discovery of predictive signals from noisy, non-stationary market data-under a practical requirement that mined factors be directly executable and auditable, and that the discovery process remain computationally tractable at scale. Existing symbolic approaches are limited by bounded expressiveness, while neural forecasters often trade interpretability for performance and remain vulnerable to regime shifts and overfitting. We introduce FactorEngine (FE), a program-level factor discovery framework that casts factors as Turing-complete code and improves both effectiveness and efficiency via three separations: (i) logic revision vs. parameter optimization, (ii) LLM-guided directional search vs. Bayesian hyperparameter search, and (iii) LLM usage vs. local computation. FE further incorporates a knowledge-infused bootstrapping module that transforms unstructured financial reports into executable factor programs through a closed-loop multi-agent extraction-verification-code-generation pipeline, and an experience knowledge base that supports trajectory-aware refinement (including learning from failures). Across extensive backtests on real-world OHLCV data, FE produces factors with substantially stronger predictive stability and portfolio impact-for example, higher IC/ICIR (and Rank IC/ICIR) and improved AR/Sharpe, than baseline methods, achieving state-of-the-art predictive and portfolio performance.
Agent Skills in the Wild: An Empirical Study of Security Vulnerabilities at Scale
Jan 15, 2026The rise of AI agent frameworks has introduced agent skills, modular packages containing instructions and executable code that dynamically extend agent capabilities. While this architecture enables powerful customization, skills execute with implicit trust and minimal vetting, creating a significant yet uncharacterized attack surface. We conduct the first large-scale empirical security analysis of this emerging ecosystem, collecting 42,447 skills from two major marketplaces and systematically analyzing 31,132 using SkillScan, a multi-stage detection framework integrating static analysis with LLM-based semantic classification. Our findings reveal pervasive security risks: 26.1% of skills contain at least one vulnerability, spanning 14 distinct patterns across four categories: prompt injection, data exfiltration, privilege escalation, and supply chain risks. Data exfiltration (13.3%) and privilege escalation (11.8%) are most prevalent, while 5.2% of skills exhibit high-severity patterns strongly suggesting malicious intent. We find that skills bundling executable scripts are 2.12x more likely to contain vulnerabilities than instruction-only skills (OR=2.12, p<0.001). Our contributions include: (1) a grounded vulnerability taxonomy derived from 8,126 vulnerable skills, (2) a validated detection methodology achieving 86.7% precision and 82.5% recall, and (3) an open dataset and detection toolkit to support future research. These results demonstrate an urgent need for capability-based permission systems and mandatory security vetting before this attack vector is further exploited.
ART: The Alternating Reading Task Corpus for Speech Entrainment and Imitation
Apr 03, 2024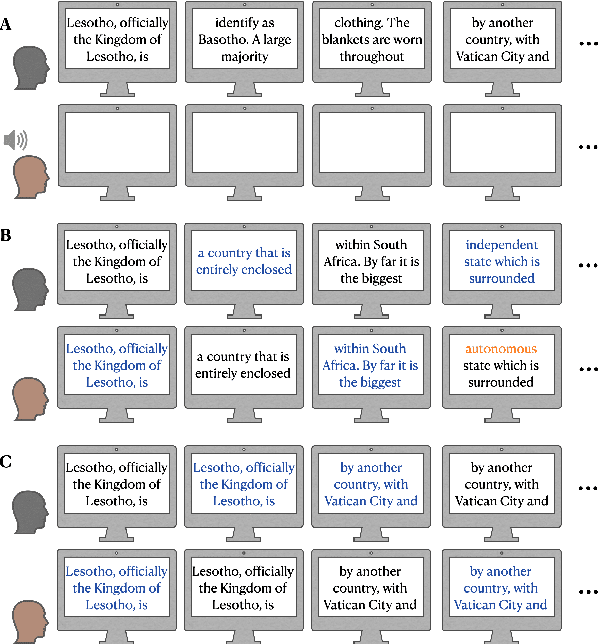
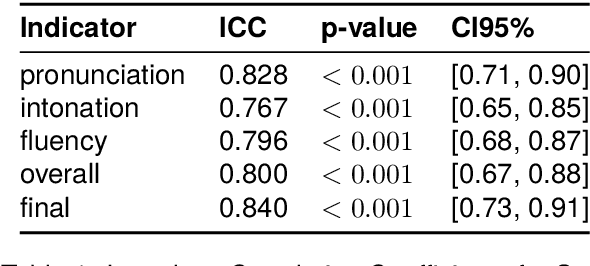
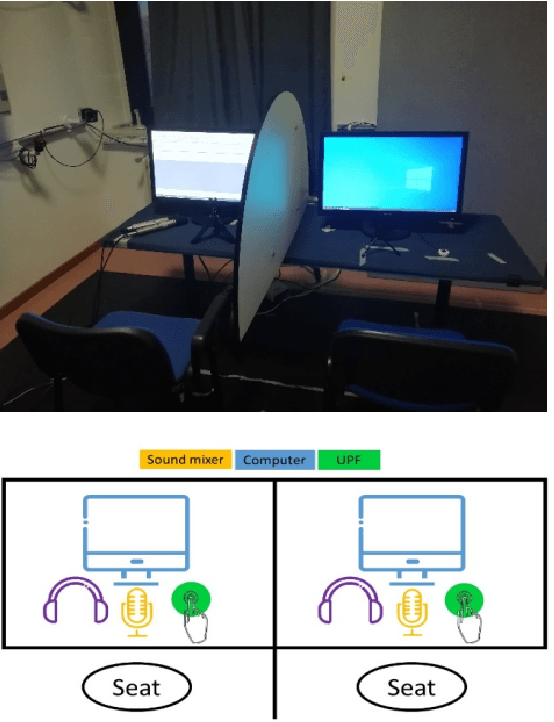
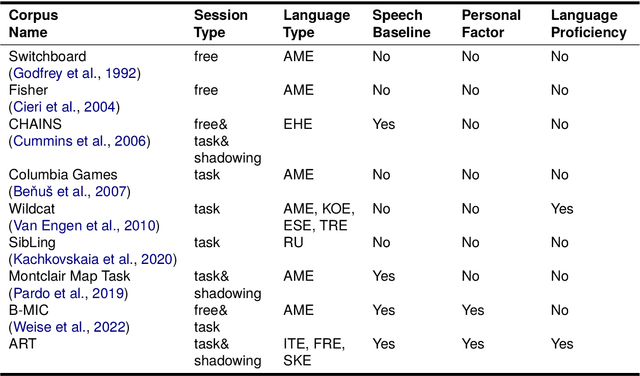
We introduce the Alternating Reading Task (ART) Corpus, a collection of dyadic sentence reading for studying the entrainment and imitation behaviour in speech communication. The ART corpus features three experimental conditions - solo reading, alternating reading, and deliberate imitation - as well as three sub-corpora encompassing French-, Italian-, and Slovak-accented English. This design allows systematic investigation of speech entrainment in a controlled and less-spontaneous setting. Alongside detailed transcriptions, it includes English proficiency scores, demographics, and in-experiment questionnaires for probing linguistic, personal and interpersonal influences on entrainment. Our presentation covers its design, collection, annotation processes, initial analysis, and future research prospects.
Beyond Fidelity: Explaining Vulnerability Localization of Learning-based Detectors
Jan 05, 2024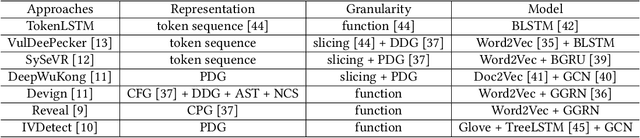
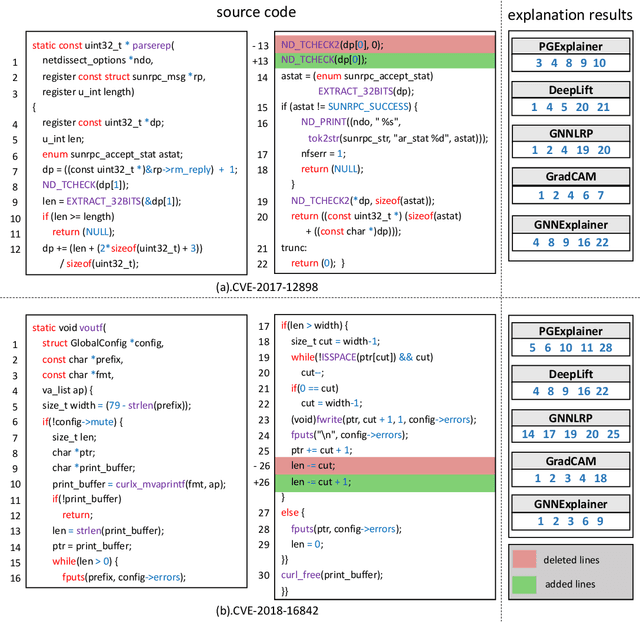
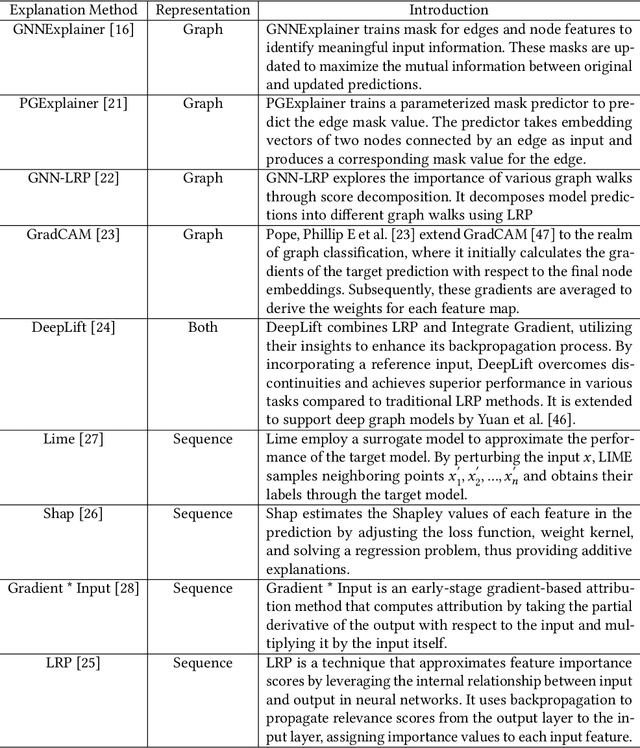
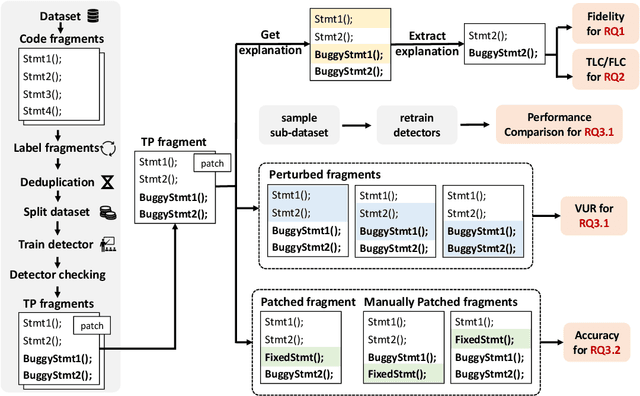
Vulnerability detectors based on deep learning (DL) models have proven their effectiveness in recent years. However, the shroud of opacity surrounding the decision-making process of these detectors makes it difficult for security analysts to comprehend. To address this, various explanation approaches have been proposed to explain the predictions by highlighting important features, which have been demonstrated effective in other domains such as computer vision and natural language processing. Unfortunately, an in-depth evaluation of vulnerability-critical features, such as fine-grained vulnerability-related code lines, learned and understood by these explanation approaches remains lacking. In this study, we first evaluate the performance of ten explanation approaches for vulnerability detectors based on graph and sequence representations, measured by two quantitative metrics including fidelity and vulnerability line coverage rate. Our results show that fidelity alone is not sufficient for evaluating these approaches, as fidelity incurs significant fluctuations across different datasets and detectors. We subsequently check the precision of the vulnerability-related code lines reported by the explanation approaches, and find poor accuracy in this task among all of them. This can be attributed to the inefficiency of explainers in selecting important features and the presence of irrelevant artifacts learned by DL-based detectors.
An Orchestrated Empirical Study on Deep Learning Frameworks and Platforms
Nov 13, 2018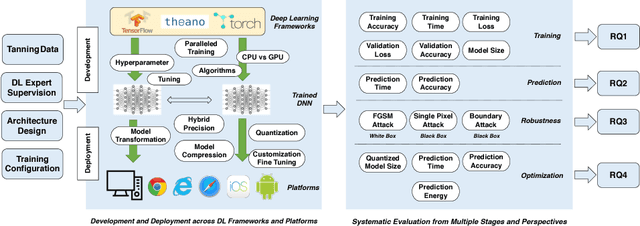
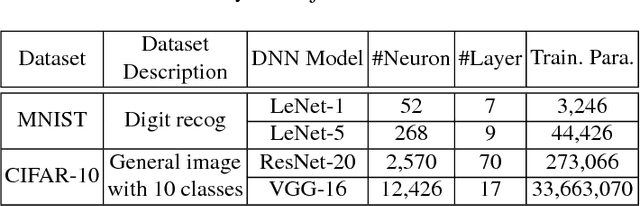
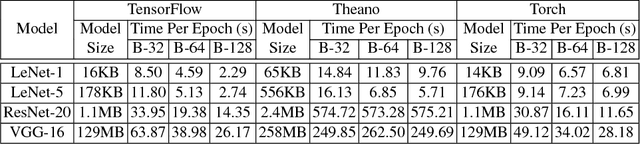
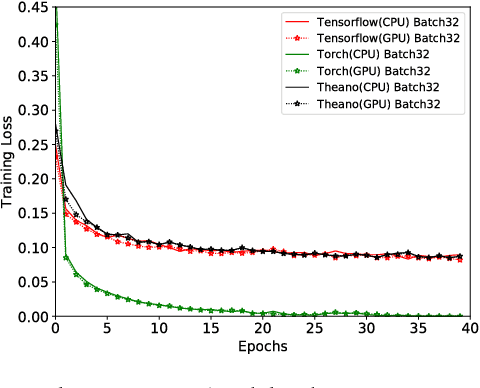
Deep learning (DL) has recently achieved tremendous success in a variety of cutting-edge applications, e.g., image recognition, speech and natural language processing, and autonomous driving. Besides the available big data and hardware evolution, DL frameworks and platforms play a key role to catalyze the research, development, and deployment of DL intelligent solutions. However, the difference in computation paradigm, architecture design and implementation of existing DL frameworks and platforms brings challenges for DL software development, deployment, maintenance, and migration. Up to the present, it still lacks a comprehensive study on how current diverse DL frameworks and platforms influence the DL software development process. In this paper, we initiate the first step towards the investigation on how existing state-of-the-art DL frameworks (i.e., TensorFlow, Theano, and Torch) and platforms (i.e., server/desktop, web, and mobile) support the DL software development activities. We perform an in-depth and comparative evaluation on metrics such as learning accuracy, DL model size, robustness, and performance, on state-of-the-art DL frameworks across platforms using two popular datasets MNIST and CIFAR-10. Our study reveals that existing DL frameworks still suffer from compatibility issues, which becomes even more severe when it comes to different platforms. We pinpoint the current challenges and opportunities towards developing high quality and compatible DL systems. To ignite further investigation along this direction to address urgent industrial demands of intelligent solutions, we make all of our assembled feasible toolchain and dataset publicly available.