 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Attention Distillation for Robust Few-Shot Segmentation under Environmental Perturbations
Jan 07, 2026Few-shot segmentation (FSS) aims to rapidly learn novel class concepts from limited examples to segment specific targets in unseen images, and has been widely applied in areas such as medical diagnosis and industrial inspection. However, existing studies largely overlook the complex environmental factors encountered in real world scenarios-such as illumination, background, and camera viewpoint-which can substantially increase the difficulty of test images. As a result, models trained under laboratory conditions often fall short of practical deployment requirements. To bridge this gap, in this paper, an environment-robust FSS setting is introduced that explicitly incorporates challenging test cases arising from complex environments-such as motion blur, small objects, and camouflaged targets-to enhance model's robustness under realistic, dynamic conditions. An environment robust FSS benchmark (ER-FSS) is established, covering eight datasets across multiple real world scenarios. In addition, an Adaptive Attention Distillation (AAD) method is proposed, which repeatedly contrasts and distills key shared semantics between known (support) and unknown (query) images to derive class-specific attention for novel categories. This strengthens the model's ability to focus on the correct targets in complex environments, thereby improving environmental robustness. Comparative experiments show that AAD improves mIoU by 3.3% - 8.5% across all datasets and settings, demonstrating superior performance and strong generalization. The source code and dataset are available at: https://github.com/guoqianyu-alberta/Adaptive-Attention-Distillation-for-FSS.
Enhancing Environmental Robustness in Few-shot Learning via Conditional Representation Learning
Feb 03, 2025
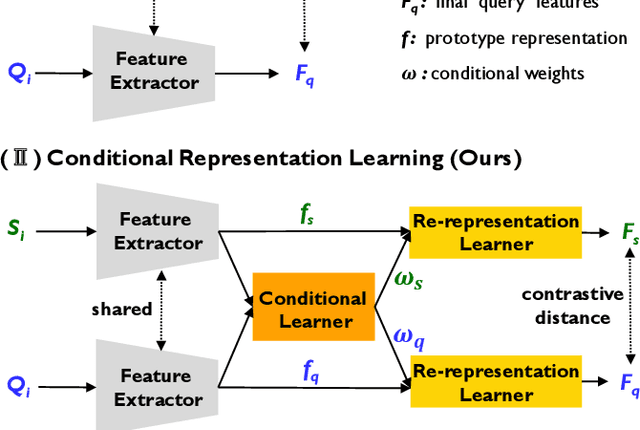

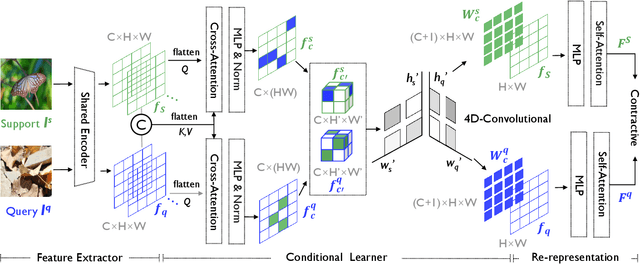
Few-shot learning (FSL) has recently been extensively utilized to overcome the scarcity of training data in domain-specific visual recognition. In real-world scenarios, environmental factors such as complex backgrounds, varying lighting conditions, long-distance shooting, and moving targets often cause test images to exhibit numerous incomplete targets or noise disruptions. However, current research on evaluation datasets and methodologies has largely ignored the concept of "environmental robustness", which refers to maintaining consistent performance in complex and diverse physical environments. This neglect has led to a notable decline in the performance of FSL models during practical testing compared to their training performance. To bridge this gap, we introduce a new real-world multi-domain few-shot learning (RD-FSL) benchmark, which includes four domains and six evaluation datasets. The test images in this benchmark feature various challenging elements, such as camouflaged objects, small targets, and blurriness. Our evaluation experiments reveal that existing methods struggle to utilize training images effectively to generate accurate feature representations for challenging test images. To address this problem, we propose a novel conditional representation learning network (CRLNet) that integrates the interactions between training and testing images as conditional information in their respective representation processes. The main goal is to reduce intra-class variance or enhance inter-class variance at the feature representation level. Finally, comparative experiments reveal that CRLNet surpasses the current state-of-the-art methods, achieving performance improvements ranging from 6.83% to 16.98% across diverse settings and backbones. The source code and dataset are available at https://github.com/guoqianyu-alberta/Conditional-Representation-Learning.
Force-EvT: A Closer Look at Robotic Gripper Force Measurement with Event-based Vision Transformer
Apr 01, 2024
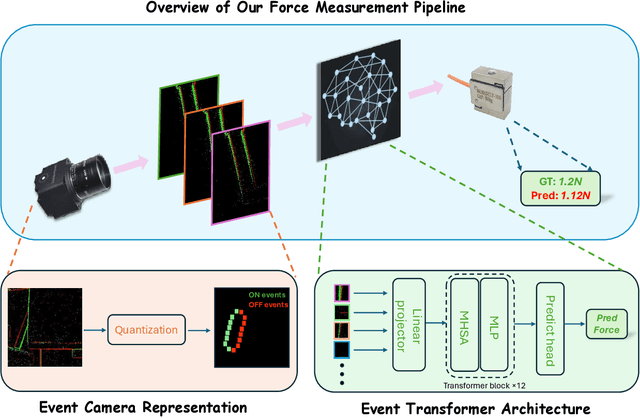
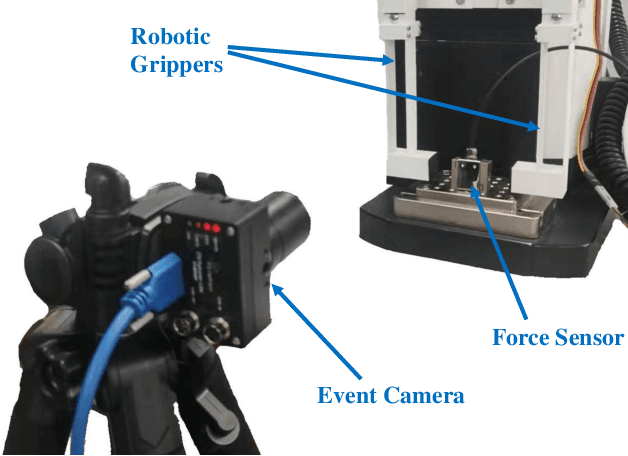

Robotic grippers are receiving increasing attention in various industries as essential components of robots for interacting and manipulating objects. While significant progress has been made in the past, conventional rigid grippers still have limitations in handling irregular objects and can damage fragile objects. We have shown that soft grippers offer deformability to adapt to a variety of object shapes and maximize object protection. At the same time, dynamic vision sensors (e.g., event-based cameras) are capable of capturing small changes in brightness and streaming them asynchronously as events, unlike RGB cameras, which do not perform well in low-light and fast-moving environments. In this paper, a dynamic-vision-based algorithm is proposed to measure the force applied to the gripper. In particular, we first set up a DVXplorer Lite series event camera to capture twenty-five sets of event data. Second, motivated by the impressive performance of the Vision Transformer (ViT) algorithm in dense image prediction tasks, we propose a new approach that demonstrates the potential for real-time force estimation and meets the requirements of real-world scenarios. We extensively evaluate the proposed algorithm on a wide range of scenarios and settings, and show that it consistently outperforms recent approaches.
Diffusion Attack: Leveraging Stable Diffusion for Naturalistic Image Attacking
Mar 21, 2024In Virtual Reality (VR), adversarial attack remains a significant security threat. Most deep learning-based methods for physical and digital adversarial attacks focus on enhancing attack performance by crafting adversarial examples that contain large printable distortions that are easy for human observers to identify. However, attackers rarely impose limitations on the naturalness and comfort of the appearance of the generated attack image, resulting in a noticeable and unnatural attack. To address this challenge, we propose a framework to incorporate style transfer to craft adversarial inputs of natural styles that exhibit minimal detectability and maximum natural appearance, while maintaining superior attack capabilities.
A User-Friendly Framework for Generating Model-Preferred Prompts in Text-to-Image Synthesis
Feb 20, 2024Well-designed prompts have demonstrated the potential to guide text-to-image models in generating amazing images. Although existing prompt engineering methods can provide high-level guidance, it is challenging for novice users to achieve the desired results by manually entering prompts due to a discrepancy between novice-user-input prompts and the model-preferred prompts. To bridge the distribution gap between user input behavior and model training datasets, we first construct a novel Coarse-Fine Granularity Prompts dataset (CFP) and propose a novel User-Friendly Fine-Grained Text Generation framework (UF-FGTG) for automated prompt optimization. For CFP, we construct a novel dataset for text-to-image tasks that combines coarse and fine-grained prompts to facilitate the development of automated prompt generation methods. For UF-FGTG, we propose a novel framework that automatically translates user-input prompts into model-preferred prompts. Specifically, we propose a prompt refiner that continually rewrites prompts to empower users to select results that align with their unique needs. Meanwhile, we integrate image-related loss functions from the text-to-image model into the training process of text generation to generate model-preferred prompts. Additionally, we propose an adaptive feature extraction module to ensure diversity in the generated results. Experiments demonstrate that our approach is capable of generating more visually appealing and diverse images than previous state-of-the-art methods, achieving an average improvement of 5% across six quality and aesthetic metrics.
LiDAR-Forest Dataset: LiDAR Point Cloud Simulation Dataset for Forestry Application
Feb 15, 2024


The popularity of LiDAR devices and sensor technology has gradually empowered users from autonomous driving to forest monitoring, and research on 3D LiDAR has made remarkable progress over the years. Unlike 2D images, whose focused area is visible and rich in texture information, understanding the point distribution can help companies and researchers find better ways to develop point-based 3D applications. In this work, we contribute an unreal-based LiDAR simulation tool and a 3D simulation dataset named LiDAR-Forest, which can be used by various studies to evaluate forest reconstruction, tree DBH estimation, and point cloud compression for easy visualization. The simulation is customizable in tree species, LiDAR types and scene generation, with low cost and high efficiency.
Retrieval-Augmented Generation for Large Language Models: A Survey
Jan 03, 2024



Large Language Models (LLMs) demonstrate significant capabilities but face challenges such as hallucination, outdated knowledge, and non-transparent, untraceable reasoning processes. Retrieval-Augmented Generation (RAG) has emerged as a promising solution by incorporating knowledge from external databases. This enhances the accuracy and credibility of the models, particularly for knowledge-intensive tasks, and allows for continuous knowledge updates and integration of domain-specific information. RAG synergistically merges LLMs' intrinsic knowledge with the vast, dynamic repositories of external databases. This comprehensive review paper offers a detailed examination of the progression of RAG paradigms, encompassing the Naive RAG, the Advanced RAG, and the Modular RAG. It meticulously scrutinizes the tripartite foundation of RAG frameworks, which includes the retrieval , the generation and the augmentation techniques. The paper highlights the state-of-the-art technologies embedded in each of these critical components, providing a profound understanding of the advancements in RAG systems. Furthermore, this paper introduces the metrics and benchmarks for assessing RAG models, along with the most up-to-date evaluation framework. In conclusion, the paper delineates prospective avenues for research, including the identification of challenges, the expansion of multi-modalities, and the progression of the RAG infrastructure and its ecosystem.
DL3DV-10K: A Large-Scale Scene Dataset for Deep Learning-based 3D Vision
Dec 29, 2023



We have witnessed significant progress in deep learning-based 3D vision, ranging from neural radiance field (NeRF) based 3D representation learning to applications in novel view synthesis (NVS). However, existing scene-level datasets for deep learning-based 3D vision, limited to either synthetic environments or a narrow selection of real-world scenes, are quite insufficient. This insufficiency not only hinders a comprehensive benchmark of existing methods but also caps what could be explored in deep learning-based 3D analysis. To address this critical gap, we present DL3DV-10K, a large-scale scene dataset, featuring 51.2 million frames from 10,510 videos captured from 65 types of point-of-interest (POI) locations, covering both bounded and unbounded scenes, with different levels of reflection, transparency, and lighting. We conducted a comprehensive benchmark of recent NVS methods on DL3DV-10K, which revealed valuable insights for future research in NVS. In addition, we have obtained encouraging results in a pilot study to learn generalizable NeRF from DL3DV-10K, which manifests the necessity of a large-scale scene-level dataset to forge a path toward a foundation model for learning 3D representation. Our DL3DV-10K dataset, benchmark results, and models will be publicly accessible at https://dl3dv-10k.github.io/DL3DV-10K/.
Flames: Benchmarking Value Alignment of Chinese Large Language Models
Nov 12, 2023



The widespread adoption of large language models (LLMs) across various regions underscores the urgent need to evaluate their alignment with human values. Current benchmarks, however, fall short of effectively uncovering safety vulnerabilities in LLMs. Despite numerous models achieving high scores and 'topping the chart' in these evaluations, there is still a significant gap in LLMs' deeper alignment with human values and achieving genuine harmlessness. To this end, this paper proposes the first highly adversarial benchmark named Flames, consisting of 2,251 manually crafted prompts, ~18.7K model responses with fine-grained annotations, and a specified scorer. Our framework encompasses both common harmlessness principles, such as fairness, safety, legality, and data protection, and a unique morality dimension that integrates specific Chinese values such as harmony. Based on the framework, we carefully design adversarial prompts that incorporate complex scenarios and jailbreaking methods, mostly with implicit malice. By prompting mainstream LLMs with such adversarially constructed prompts, we obtain model responses, which are then rigorously annotated for evaluation. Our findings indicate that all the evaluated LLMs demonstrate relatively poor performance on Flames, particularly in the safety and fairness dimensions. Claude emerges as the best-performing model overall, but with its harmless rate being only 63.08% while GPT-4 only scores 39.04%. The complexity of Flames has far exceeded existing benchmarks, setting a new challenge for contemporary LLMs and highlighting the need for further alignment of LLMs. To efficiently evaluate new models on the benchmark, we develop a specified scorer capable of scoring LLMs across multiple dimensions, achieving an accuracy of 77.4%. The Flames Benchmark is publicly available on https://github.com/AIFlames/Flames.
Plug-and-Play Feature Generation for Few-Shot Medical Image Classification
Oct 14, 2023Few-shot learning (FSL) presents immense potential in enhancing model generalization and practicality for medical image classification with limited training data; however, it still faces the challenge of severe overfitting in classifier training due to distribution bias caused by the scarce training samples. To address the issue, we propose MedMFG, a flexible and lightweight plug-and-play method designed to generate sufficient class-distinctive features from limited samples. Specifically, MedMFG first re-represents the limited prototypes to assign higher weights for more important information features. Then, the prototypes are variationally generated into abundant effective features. Finally, the generated features and prototypes are together to train a more generalized classifier. Experiments demonstrate that MedMFG outperforms the previous state-of-the-art methods on cross-domain benchmarks involving the transition from natural images to medical images, as well as medical images with different lesions. Notably, our method achieves over 10% performance improvement compared to several baselines. Fusion experiments further validate the adaptability of MedMFG, as it seamlessly integrates into various backbones and baselines, consistently yielding improvements of over 2.9% across all results.