 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRewarding What Matters: Step-by-Step Reinforcement Learning for Task-Oriented Dialogue
Jun 20, 2024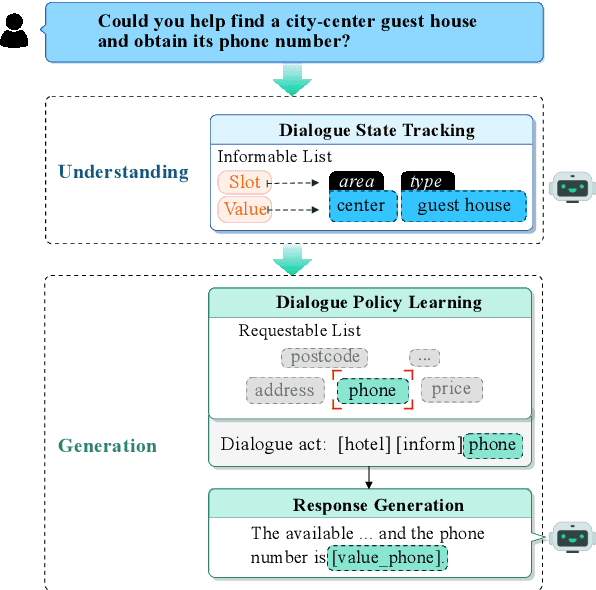

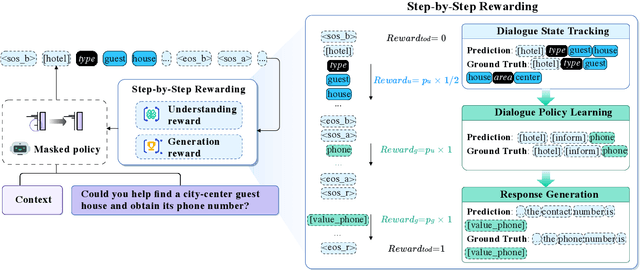
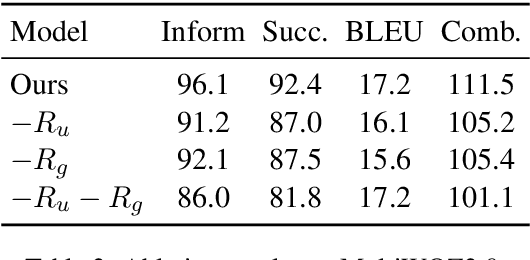
Reinforcement learning (RL) is a powerful approach to enhance task-oriented dialogue (TOD) systems. However, existing RL methods tend to mainly focus on generation tasks, such as dialogue policy learning (DPL) or response generation (RG), while neglecting dialogue state tracking (DST) for understanding. This narrow focus limits the systems to achieve globally optimal performance by overlooking the interdependence between understanding and generation. Additionally, RL methods face challenges with sparse and delayed rewards, which complicates training and optimization. To address these issues, we extend RL into both understanding and generation tasks by introducing step-by-step rewards throughout the token generation. The understanding reward increases as more slots are correctly filled in DST, while the generation reward grows with the accurate inclusion of user requests. Our approach provides a balanced optimization aligned with task completion. Experimental results demonstrate that our approach effectively enhances the performance of TOD systems and achieves new state-of-the-art results on three widely used datasets, including MultiWOZ2.0, MultiWOZ2.1, and In-Car. Our approach also shows superior few-shot ability in low-resource settings compared to current models.
Plug-and-Play Feature Generation for Few-Shot Medical Image Classification
Oct 14, 2023Few-shot learning (FSL) presents immense potential in enhancing model generalization and practicality for medical image classification with limited training data; however, it still faces the challenge of severe overfitting in classifier training due to distribution bias caused by the scarce training samples. To address the issue, we propose MedMFG, a flexible and lightweight plug-and-play method designed to generate sufficient class-distinctive features from limited samples. Specifically, MedMFG first re-represents the limited prototypes to assign higher weights for more important information features. Then, the prototypes are variationally generated into abundant effective features. Finally, the generated features and prototypes are together to train a more generalized classifier. Experiments demonstrate that MedMFG outperforms the previous state-of-the-art methods on cross-domain benchmarks involving the transition from natural images to medical images, as well as medical images with different lesions. Notably, our method achieves over 10% performance improvement compared to several baselines. Fusion experiments further validate the adaptability of MedMFG, as it seamlessly integrates into various backbones and baselines, consistently yielding improvements of over 2.9% across all results.