 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn autonomous living database for perovskite photovoltaics
Jan 25, 2026Scientific discovery is severely bottlenecked by the inability of manual curation to keep pace with exponential publication rates. This creates a widening knowledge gap. This is especially stark in photovoltaics, where the leading database for perovskite solar cells has been stagnant since 2021 despite massive ongoing research output. Here, we resolve this challenge by establishing an autonomous, self-updating living database (PERLA). Our pipeline integrates large language models with physics-aware validation to extract complex device data from the continuous literature stream, achieving human-level precision (>90%) and eliminating annotator variance. By employing this system on the previously inaccessible post-2021 literature, we uncover critical evolutionary trends hidden by data lag: the field has decisively shifted toward inverted architectures employing self-assembled monolayers and formamidinium-rich compositions, driving a clear trajectory of sustained voltage loss reduction. PERLA transforms static publications into dynamic knowledge resources that enable data-driven discovery to operate at the speed of publication.
From GPT-4 to Gemini and Beyond: Assessing the Landscape of MLLMs on Generalizability, Trustworthiness and Causality through Four Modalities
Jan 29, 2024



Multi-modal Large Language Models (MLLMs) have shown impressive abilities in generating reasonable responses with respect to multi-modal contents. However, there is still a wide gap between the performance of recent MLLM-based applications and the expectation of the broad public, even though the most powerful OpenAI's GPT-4 and Google's Gemini have been deployed. This paper strives to enhance understanding of the gap through the lens of a qualitative study on the generalizability, trustworthiness, and causal reasoning capabilities of recent proprietary and open-source MLLMs across four modalities: ie, text, code, image, and video, ultimately aiming to improve the transparency of MLLMs. We believe these properties are several representative factors that define the reliability of MLLMs, in supporting various downstream applications. To be specific, we evaluate the closed-source GPT-4 and Gemini and 6 open-source LLMs and MLLMs. Overall we evaluate 230 manually designed cases, where the qualitative results are then summarized into 12 scores (ie, 4 modalities times 3 properties). In total, we uncover 14 empirical findings that are useful to understand the capabilities and limitations of both proprietary and open-source MLLMs, towards more reliable downstream multi-modal applications.
Flames: Benchmarking Value Alignment of Chinese Large Language Models
Nov 12, 2023



The widespread adoption of large language models (LLMs) across various regions underscores the urgent need to evaluate their alignment with human values. Current benchmarks, however, fall short of effectively uncovering safety vulnerabilities in LLMs. Despite numerous models achieving high scores and 'topping the chart' in these evaluations, there is still a significant gap in LLMs' deeper alignment with human values and achieving genuine harmlessness. To this end, this paper proposes the first highly adversarial benchmark named Flames, consisting of 2,251 manually crafted prompts, ~18.7K model responses with fine-grained annotations, and a specified scorer. Our framework encompasses both common harmlessness principles, such as fairness, safety, legality, and data protection, and a unique morality dimension that integrates specific Chinese values such as harmony. Based on the framework, we carefully design adversarial prompts that incorporate complex scenarios and jailbreaking methods, mostly with implicit malice. By prompting mainstream LLMs with such adversarially constructed prompts, we obtain model responses, which are then rigorously annotated for evaluation. Our findings indicate that all the evaluated LLMs demonstrate relatively poor performance on Flames, particularly in the safety and fairness dimensions. Claude emerges as the best-performing model overall, but with its harmless rate being only 63.08% while GPT-4 only scores 39.04%. The complexity of Flames has far exceeded existing benchmarks, setting a new challenge for contemporary LLMs and highlighting the need for further alignment of LLMs. To efficiently evaluate new models on the benchmark, we develop a specified scorer capable of scoring LLMs across multiple dimensions, achieving an accuracy of 77.4%. The Flames Benchmark is publicly available on https://github.com/AIFlames/Flames.
Active Object Reconstruction Using a Guided View Planner
May 08, 2018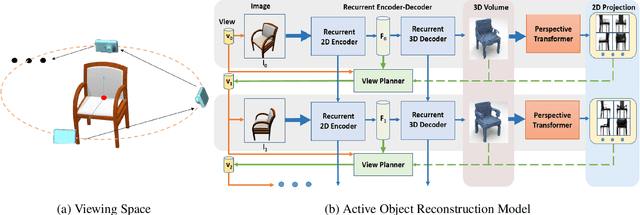
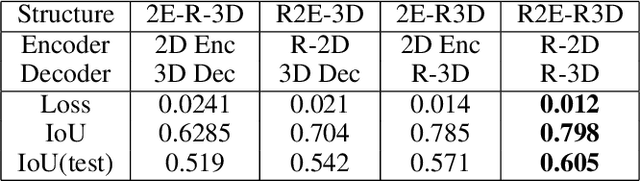
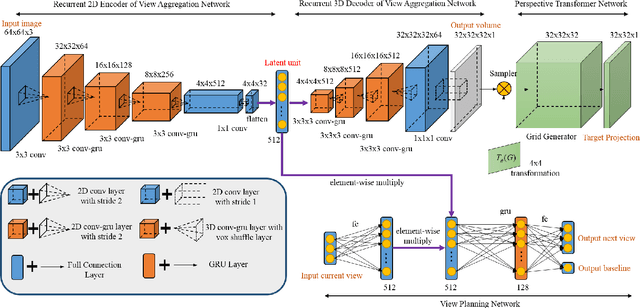
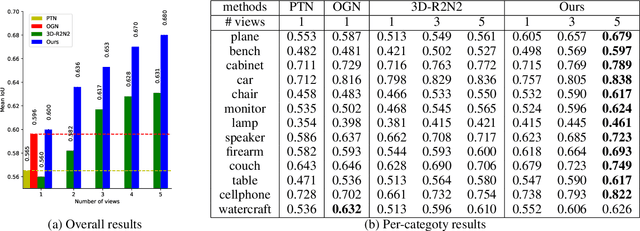
Inspired by the recent advance of image-based object reconstruction using deep learning, we present an active reconstruction model using a guided view planner. We aim to reconstruct a 3D model using images observed from a planned sequence of informative and discriminative views. But where are such informative and discriminative views around an object? To address this we propose a unified model for view planning and object reconstruction, which is utilized to learn a guided information acquisition model and to aggregate information from a sequence of images for reconstruction. Experiments show that our model (1) increases our reconstruction accuracy with an increasing number of views (2) and generally predicts a more informative sequence of views for object reconstruction compared to other alternative methods.