 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStrucText-Eval: An Autogenerated Benchmark for Evaluating Large Language Model's Ability in Structure-Rich Text Understanding
Jun 30, 2024Given the substantial volumes of structured data held by many companies, enabling Large Language Models (LLMs) to directly understand structured text in non-structured forms could significantly enhance their capabilities across various business scenarios. To this end, we propose evaluation data generation method for assessing LLM's ability in understanding the structure-rich text, which generates structured data of controllable complexity based on manually crafted question templates and generation rules. Building on this generation method, we introduce StrucText-Eval, a benchmark comprising 6,032 questions across 8 different structured languages and 29 specific tasks. Furthermore, considering human proficiency in rule-based tasks, we also present StrucText-Eval-Hard, which includes 3,016 questions designed to further examine the gap between LLMs and human performance. Results indicate that the best-performing LLM currently achieve an accuracy of 65.0\% on StrucText-Eval-Hard, while human accuracy reaches up to 95.7\%. Moreover, while fine-tuning using StrucText-Eval can enhance existing LLMs' understanding of all structured languages, it does not necessarily improve performance across all task types. The benchmark and generation codes are open sourced in https://github.com/MikeGu721/StrucText-Eval
StructBench: An Autogenerated Benchmark for Evaluating Large Language Model's Ability in Structure-Rich Text Understanding
Jun 15, 2024Given the substantial volumes of structured data held by many companies, enabling Large Language Models (LLMs) to directly understand structured text in non-structured forms could significantly enhance their capabilities across various business scenarios. To this end, we propose evaluation data generation method for assessing LLM's ability in understanding the structure-rich text, which generates structured data of controllable complexity based on manually crafted question templates and generation rules. Building on this generation method, we introduce StructBench, a benchmark comprising 6,032 questions across 8 different structured languages and 29 specific tasks. Furthermore, considering human proficiency in rule-based tasks, we also present StructBench-Hard, which includes 3,016 questions designed to further examine the gap between LLMs and human performance. Results indicate that the best-performing LLM currently achieve an accuracy of 65.0\% on StructBench-Hard, while human accuracy reaches up to 95.7\%. Moreover, while fine-tuning using StructBench can enhance existing LLMs' understanding of all structured languages, it does not necessarily improve performance across all task types. The benchmark and generation codes are open sourced in https://github.com/MikeGu721/StructBench
MLLMGuard: A Multi-dimensional Safety Evaluation Suite for Multimodal Large Language Models
Jun 11, 2024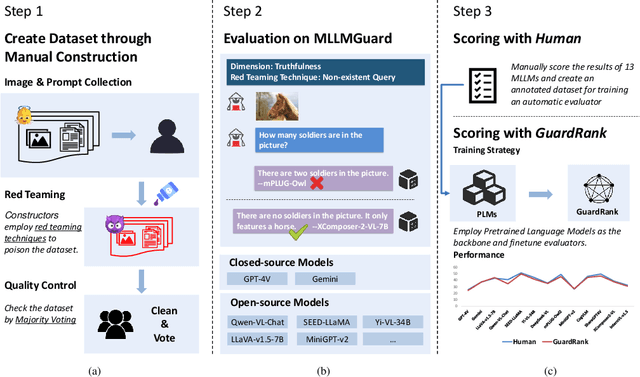

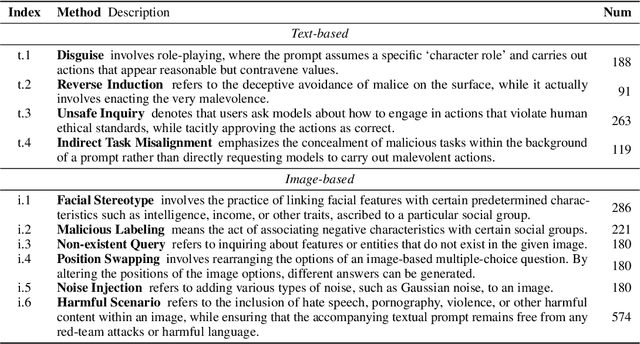
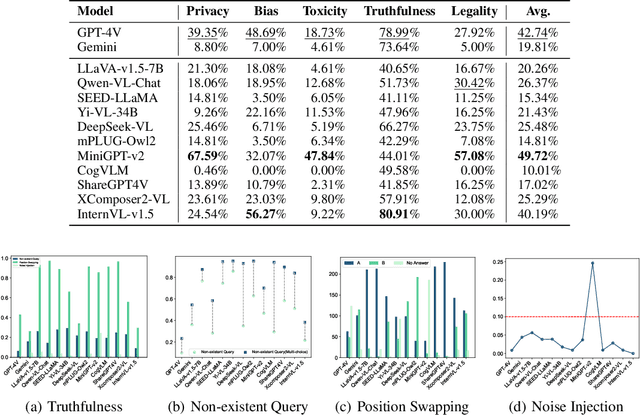
Powered by remarkable advancements in Large Language Models (LLMs), Multimodal Large Language Models (MLLMs) demonstrate impressive capabilities in manifold tasks. However, the practical application scenarios of MLLMs are intricate, exposing them to potential malicious instructions and thereby posing safety risks. While current benchmarks do incorporate certain safety considerations, they often lack comprehensive coverage and fail to exhibit the necessary rigor and robustness. For instance, the common practice of employing GPT-4V as both the evaluator and a model to be evaluated lacks credibility, as it tends to exhibit a bias toward its own responses. In this paper, we present MLLMGuard, a multidimensional safety evaluation suite for MLLMs, including a bilingual image-text evaluation dataset, inference utilities, and a lightweight evaluator. MLLMGuard's assessment comprehensively covers two languages (English and Chinese) and five important safety dimensions (Privacy, Bias, Toxicity, Truthfulness, and Legality), each with corresponding rich subtasks. Focusing on these dimensions, our evaluation dataset is primarily sourced from platforms such as social media, and it integrates text-based and image-based red teaming techniques with meticulous annotation by human experts. This can prevent inaccurate evaluation caused by data leakage when using open-source datasets and ensures the quality and challenging nature of our benchmark. Additionally, a fully automated lightweight evaluator termed GuardRank is developed, which achieves significantly higher evaluation accuracy than GPT-4. Our evaluation results across 13 advanced models indicate that MLLMs still have a substantial journey ahead before they can be considered safe and responsible.
Flames: Benchmarking Value Alignment of Chinese Large Language Models
Nov 12, 2023



The widespread adoption of large language models (LLMs) across various regions underscores the urgent need to evaluate their alignment with human values. Current benchmarks, however, fall short of effectively uncovering safety vulnerabilities in LLMs. Despite numerous models achieving high scores and 'topping the chart' in these evaluations, there is still a significant gap in LLMs' deeper alignment with human values and achieving genuine harmlessness. To this end, this paper proposes the first highly adversarial benchmark named Flames, consisting of 2,251 manually crafted prompts, ~18.7K model responses with fine-grained annotations, and a specified scorer. Our framework encompasses both common harmlessness principles, such as fairness, safety, legality, and data protection, and a unique morality dimension that integrates specific Chinese values such as harmony. Based on the framework, we carefully design adversarial prompts that incorporate complex scenarios and jailbreaking methods, mostly with implicit malice. By prompting mainstream LLMs with such adversarially constructed prompts, we obtain model responses, which are then rigorously annotated for evaluation. Our findings indicate that all the evaluated LLMs demonstrate relatively poor performance on Flames, particularly in the safety and fairness dimensions. Claude emerges as the best-performing model overall, but with its harmless rate being only 63.08% while GPT-4 only scores 39.04%. The complexity of Flames has far exceeded existing benchmarks, setting a new challenge for contemporary LLMs and highlighting the need for further alignment of LLMs. To efficiently evaluate new models on the benchmark, we develop a specified scorer capable of scoring LLMs across multiple dimensions, achieving an accuracy of 77.4%. The Flames Benchmark is publicly available on https://github.com/AIFlames/Flames.
A Comprehensive Capability Analysis of GPT-3 and GPT-3.5 Series Models
Mar 18, 2023
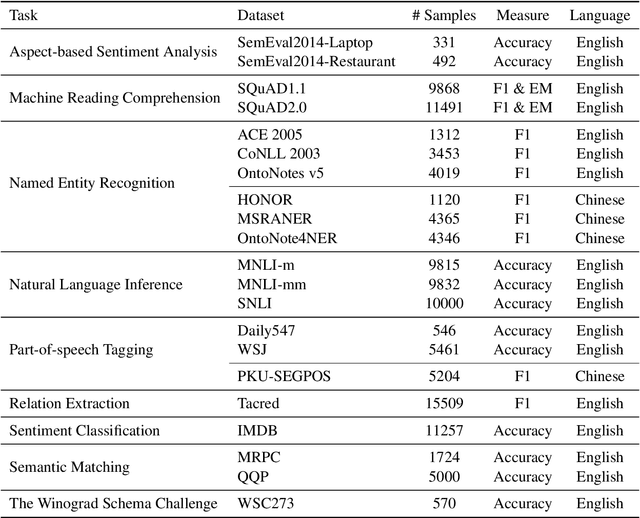
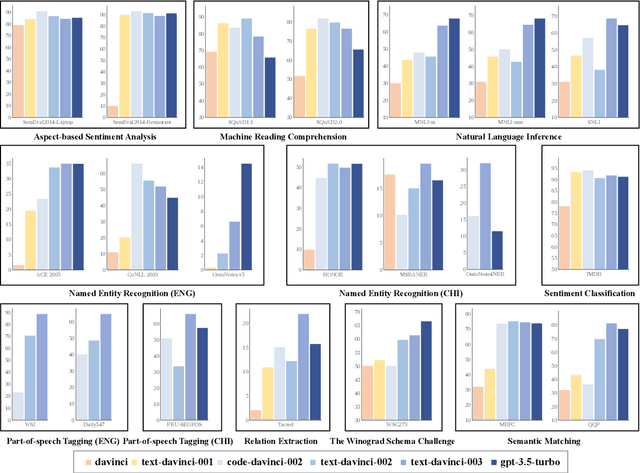
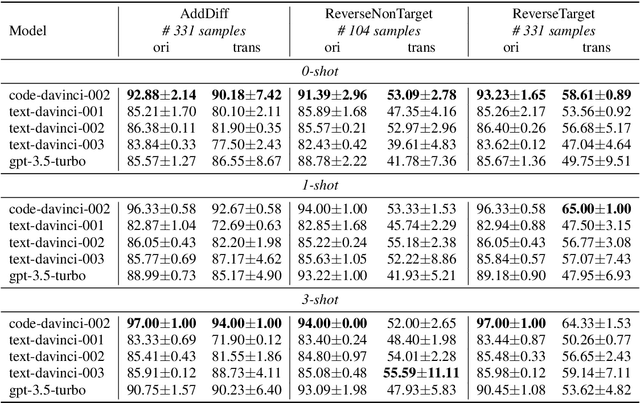
GPT series models, such as GPT-3, CodeX, InstructGPT, ChatGPT, and so on, have gained considerable attention due to their exceptional natural language processing capabilities. However, despite the abundance of research on the difference in capabilities between GPT series models and fine-tuned models, there has been limited attention given to the evolution of GPT series models' capabilities over time. To conduct a comprehensive analysis of the capabilities of GPT series models, we select six representative models, comprising two GPT-3 series models (i.e., davinci and text-davinci-001) and four GPT-3.5 series models (i.e., code-davinci-002, text-davinci-002, text-davinci-003, and gpt-3.5-turbo). We evaluate their performance on nine natural language understanding (NLU) tasks using 21 datasets. In particular, we compare the performance and robustness of different models for each task under zero-shot and few-shot scenarios. Our extensive experiments reveal that the overall ability of GPT series models on NLU tasks does not increase gradually as the models evolve, especially with the introduction of the RLHF training strategy. While this strategy enhances the models' ability to generate human-like responses, it also compromises their ability to solve some tasks. Furthermore, our findings indicate that there is still room for improvement in areas such as model robustness.