 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStrucText-Eval: An Autogenerated Benchmark for Evaluating Large Language Model's Ability in Structure-Rich Text Understanding
Jun 30, 2024Given the substantial volumes of structured data held by many companies, enabling Large Language Models (LLMs) to directly understand structured text in non-structured forms could significantly enhance their capabilities across various business scenarios. To this end, we propose evaluation data generation method for assessing LLM's ability in understanding the structure-rich text, which generates structured data of controllable complexity based on manually crafted question templates and generation rules. Building on this generation method, we introduce StrucText-Eval, a benchmark comprising 6,032 questions across 8 different structured languages and 29 specific tasks. Furthermore, considering human proficiency in rule-based tasks, we also present StrucText-Eval-Hard, which includes 3,016 questions designed to further examine the gap between LLMs and human performance. Results indicate that the best-performing LLM currently achieve an accuracy of 65.0\% on StrucText-Eval-Hard, while human accuracy reaches up to 95.7\%. Moreover, while fine-tuning using StrucText-Eval can enhance existing LLMs' understanding of all structured languages, it does not necessarily improve performance across all task types. The benchmark and generation codes are open sourced in https://github.com/MikeGu721/StrucText-Eval
StructBench: An Autogenerated Benchmark for Evaluating Large Language Model's Ability in Structure-Rich Text Understanding
Jun 15, 2024Given the substantial volumes of structured data held by many companies, enabling Large Language Models (LLMs) to directly understand structured text in non-structured forms could significantly enhance their capabilities across various business scenarios. To this end, we propose evaluation data generation method for assessing LLM's ability in understanding the structure-rich text, which generates structured data of controllable complexity based on manually crafted question templates and generation rules. Building on this generation method, we introduce StructBench, a benchmark comprising 6,032 questions across 8 different structured languages and 29 specific tasks. Furthermore, considering human proficiency in rule-based tasks, we also present StructBench-Hard, which includes 3,016 questions designed to further examine the gap between LLMs and human performance. Results indicate that the best-performing LLM currently achieve an accuracy of 65.0\% on StructBench-Hard, while human accuracy reaches up to 95.7\%. Moreover, while fine-tuning using StructBench can enhance existing LLMs' understanding of all structured languages, it does not necessarily improve performance across all task types. The benchmark and generation codes are open sourced in https://github.com/MikeGu721/StructBench
Can Large Language Models Understand Real-World Complex Instructions?
Sep 17, 2023


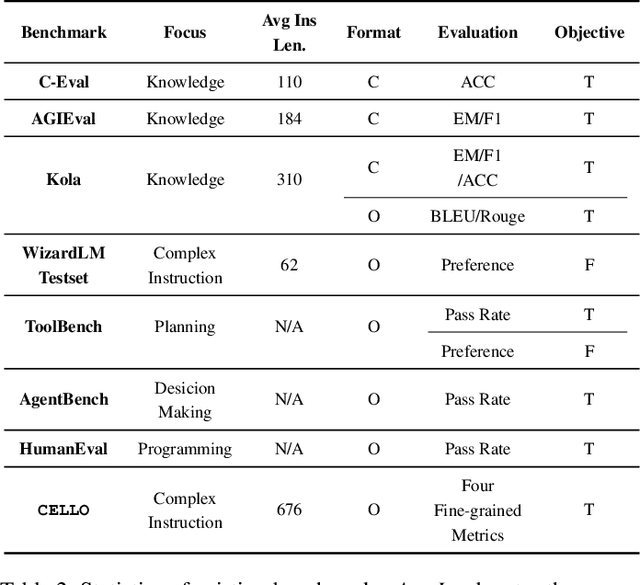
Large language models (LLMs) can understand human instructions, showing their potential for pragmatic applications beyond traditional NLP tasks. However, they still struggle with complex instructions, which can be either complex task descriptions that require multiple tasks and constraints, or complex input that contains long context, noise, heterogeneous information and multi-turn format. Due to these features, LLMs often ignore semantic constraints from task descriptions, generate incorrect formats, violate length or sample count constraints, and be unfaithful to the input text. Existing benchmarks are insufficient to assess LLMs' ability to understand complex instructions, as they are close-ended and simple. To bridge this gap, we propose CELLO, a benchmark for evaluating LLMs' ability to follow complex instructions systematically. We design eight features for complex instructions and construct a comprehensive evaluation dataset from real-world scenarios. We also establish four criteria and develop corresponding metrics, as current ones are inadequate, biased or too strict and coarse-grained. We compare the performance of representative Chinese-oriented and English-oriented models in following complex instructions through extensive experiments. Resources of CELLO are publicly available at https://github.com/Abbey4799/CELLO.
Beyond the Obvious: Evaluating the Reasoning Ability In Real-life Scenarios of Language Models on Life Scapes Reasoning Benchmark~(LSR-Benchmark)
Jul 11, 2023



This paper introduces the Life Scapes Reasoning Benchmark (LSR-Benchmark), a novel dataset targeting real-life scenario reasoning, aiming to close the gap in artificial neural networks' ability to reason in everyday contexts. In contrast to domain knowledge reasoning datasets, LSR-Benchmark comprises free-text formatted questions with rich information on real-life scenarios, human behaviors, and character roles. The dataset consists of 2,162 questions collected from open-source online sources and is manually annotated to improve its quality. Experiments are conducted using state-of-the-art language models, such as gpt3.5-turbo and instruction fine-tuned llama models, to test the performance in LSR-Benchmark. The results reveal that humans outperform these models significantly, indicating a persisting challenge for machine learning models in comprehending daily human life.
Xiezhi: An Ever-Updating Benchmark for Holistic Domain Knowledge Evaluation
Jun 15, 2023



New Natural Langauge Process~(NLP) benchmarks are urgently needed to align with the rapid development of large language models (LLMs). We present Xiezhi, the most comprehensive evaluation suite designed to assess holistic domain knowledge. Xiezhi comprises multiple-choice questions across 516 diverse disciplines ranging from 13 different subjects with 249,587 questions and accompanied by Xiezhi-Specialty and Xiezhi-Interdiscipline, both with 15k questions. We conduct evaluation of the 47 cutting-edge LLMs on Xiezhi. Results indicate that LLMs exceed average performance of humans in science, engineering, agronomy, medicine, and art, but fall short in economics, jurisprudence, pedagogy, literature, history, and management. We anticipate Xiezhi will help analyze important strengths and shortcomings of LLMs, and the benchmark is released in~\url{https://github.com/MikeGu721/XiezhiBenchmark}.
Domain Mastery Benchmark: An Ever-Updating Benchmark for Evaluating Holistic Domain Knowledge of Large Language Model--A Preliminary Release
Apr 23, 2023
Domain knowledge refers to the in-depth understanding, expertise, and familiarity with a specific subject, industry, field, or area of special interest. The existing benchmarks are all lack of an overall design for domain knowledge evaluation. Holding the belief that the real ability of domain language understanding can only be fairly evaluated by an comprehensive and in-depth benchmark, we introduces the Domma, a Domain Mastery Benchmark. DomMa targets at testing Large Language Models (LLMs) on their domain knowledge understanding, it features extensive domain coverage, large data volume, and a continually updated data set based on Chinese 112 first-level subject classifications. DomMa consist of 100,000 questions in both Chinese and English sourced from graduate entrance examinations and undergraduate exams in Chinese college. We have also propose designs to make benchmark and evaluation process more suitable to LLMs.