 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Correctness: Confidence-Aware Reward Modeling for Enhancing Large Language Model Reasoning
Nov 09, 2025Recent advancements in large language models (LLMs) have shifted the post-training paradigm from traditional instruction tuning and human preference alignment toward reinforcement learning (RL) focused on reasoning capabilities. However, numerous technical reports indicate that purely rule-based reward RL frequently results in poor-quality reasoning chains or inconsistencies between reasoning processes and final answers, particularly when the base model is of smaller scale. During the RL exploration process, models might employ low-quality reasoning chains due to the lack of knowledge, occasionally producing correct answers randomly and receiving rewards based on established rule-based judges. This constrains the potential for resource-limited organizations to conduct direct reinforcement learning training on smaller-scale models. We propose a novel confidence-based reward model tailored for enhancing STEM reasoning capabilities. Unlike conventional approaches, our model penalizes not only incorrect answers but also low-confidence correct responses, thereby promoting more robust and logically consistent reasoning. We validate the effectiveness of our approach through static evaluations, Best-of-N inference tests, and PPO-based RL training. Our method outperforms several state-of-the-art open-source reward models across diverse STEM benchmarks. We release our codes and model in https://github.com/qianxiHe147/C2RM.
SafeWork-R1: Coevolving Safety and Intelligence under the AI-45$^{\circ}$ Law
Jul 24, 2025



We introduce SafeWork-R1, a cutting-edge multimodal reasoning model that demonstrates the coevolution of capabilities and safety. It is developed by our proposed SafeLadder framework, which incorporates large-scale, progressive, safety-oriented reinforcement learning post-training, supported by a suite of multi-principled verifiers. Unlike previous alignment methods such as RLHF that simply learn human preferences, SafeLadder enables SafeWork-R1 to develop intrinsic safety reasoning and self-reflection abilities, giving rise to safety `aha' moments. Notably, SafeWork-R1 achieves an average improvement of $46.54\%$ over its base model Qwen2.5-VL-72B on safety-related benchmarks without compromising general capabilities, and delivers state-of-the-art safety performance compared to leading proprietary models such as GPT-4.1 and Claude Opus 4. To further bolster its reliability, we implement two distinct inference-time intervention methods and a deliberative search mechanism, enforcing step-level verification. Finally, we further develop SafeWork-R1-InternVL3-78B, SafeWork-R1-DeepSeek-70B, and SafeWork-R1-Qwen2.5VL-7B. All resulting models demonstrate that safety and capability can co-evolve synergistically, highlighting the generalizability of our framework in building robust, reliable, and trustworthy general-purpose AI.
Order Doesn't Matter, But Reasoning Does: Training LLMs with Order-Centric Augmentation
Feb 27, 2025



Logical reasoning is essential for large language models (LLMs) to ensure accurate and coherent inference. However, LLMs struggle with reasoning order variations and fail to generalize across logically equivalent transformations. LLMs often rely on fixed sequential patterns rather than true logical understanding. To address this issue, we introduce an order-centric data augmentation framework based on commutativity in logical reasoning. We first randomly shuffle independent premises to introduce condition order augmentation. For reasoning steps, we construct a directed acyclic graph (DAG) to model dependencies between steps, which allows us to identify valid reorderings of steps while preserving logical correctness. By leveraging order-centric augmentations, models can develop a more flexible and generalized reasoning process. Finally, we conduct extensive experiments across multiple logical reasoning benchmarks, demonstrating that our method significantly enhances LLMs' reasoning performance and adaptability to diverse logical structures. We release our codes and augmented data in https://anonymous.4open.science/r/Order-Centric-Data-Augmentation-822C/.
From Complex to Simple: Enhancing Multi-Constraint Complex Instruction Following Ability of Large Language Models
Apr 24, 2024It is imperative for Large language models (LLMs) to follow instructions with elaborate requirements (i.e. Complex Instructions Following). Yet, it remains under-explored how to enhance the ability of LLMs to follow complex instructions with multiple constraints. To bridge the gap, we initially study what training data is effective in enhancing complex constraints following abilities. We found that training LLMs with instructions containing multiple constraints enhances their understanding of complex instructions, especially those with lower complexity levels. The improvement can even generalize to compositions of out-of-domain constraints. Additionally, we further propose methods addressing how to obtain and utilize the effective training data. Finally, we conduct extensive experiments to prove the effectiveness of our methods in terms of overall performance, training efficiency, and generalization abilities under four settings.
Can Large Language Models Understand Real-World Complex Instructions?
Sep 17, 2023


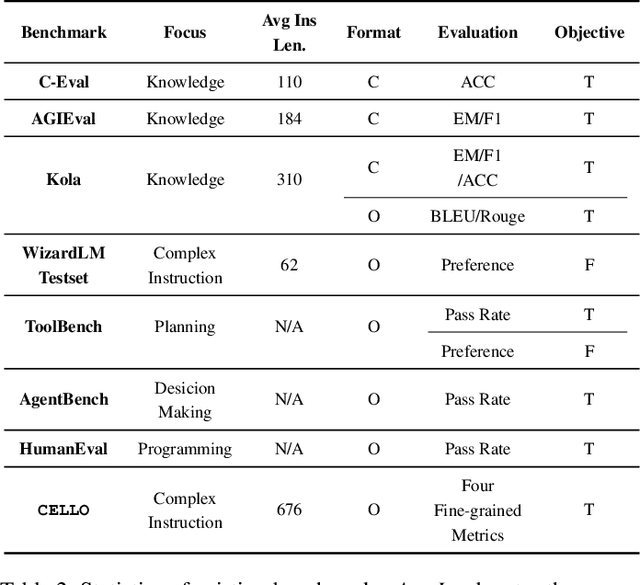
Large language models (LLMs) can understand human instructions, showing their potential for pragmatic applications beyond traditional NLP tasks. However, they still struggle with complex instructions, which can be either complex task descriptions that require multiple tasks and constraints, or complex input that contains long context, noise, heterogeneous information and multi-turn format. Due to these features, LLMs often ignore semantic constraints from task descriptions, generate incorrect formats, violate length or sample count constraints, and be unfaithful to the input text. Existing benchmarks are insufficient to assess LLMs' ability to understand complex instructions, as they are close-ended and simple. To bridge this gap, we propose CELLO, a benchmark for evaluating LLMs' ability to follow complex instructions systematically. We design eight features for complex instructions and construct a comprehensive evaluation dataset from real-world scenarios. We also establish four criteria and develop corresponding metrics, as current ones are inadequate, biased or too strict and coarse-grained. We compare the performance of representative Chinese-oriented and English-oriented models in following complex instructions through extensive experiments. Resources of CELLO are publicly available at https://github.com/Abbey4799/CELLO.