 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Harmony Composition-Inspired Tensor Modalization Method for Near-Field IRS Channel Estimation
Mar 11, 2026Intelligent reflecting surfaces (IRSs) are poised to revolutionize next-generation wireless communication systems by enhancing channel quality and spectrum efficiency through advanced wave manipulation. However, extremely large-scale IRS {(XL-IRS)} deployments face significant challenges in channel estimation due to multiplicative path loss and near-field (NF) effects, where spherical wavefronts couple distance and angle parameters. Existing polar-domain codebook-based compressive sensing methods for NF channel estimation suffer from low accuracy and high complexity, caused by the need for high-resolution grids of both distance and angle parameters. To address this, we propose a harmonic processing-inspired channel estimation framework for NF {XL-IRS} systems by leveraging tensor modalization to decouple channel parameters. Drawing an analogy to musical harmonic analysis, our approach decomposes the high-dimensional NF channel tensor into independent factor matrices, modeled as ``chords," representing distance and angle parameters. Through harmonic analysis-inspired distance parameter decoupling, we design a compact, distance-dependent codebook that enables high-resolution NF channel parameter estimation. This approach significantly reduces the codebook size compared to polar-domain methods. {Then, we} derive the Cramér-Rao lower bound (CRLB) to evaluate the estimators. Finally, simulation results show an 8.5 dB improvement in normalized mean square error (NMSE) compared to conventional methods, underscoring its low complexity and high accuracy.
ARIS-RSMA Enhanced ISAC System: Joint Rate Splitting and Beamforming Design
Feb 06, 2026This letter proposes an active reconfigurable intelligent surface (ARIS) assisted rate-splitting multiple access (RSMA) integrated sensing and communication (ISAC) system to overcome the fairness bottleneck in multi-target sensing under obstructed line-of-sight environments. Beamforming at the transceiver and ARIS, along with rate splitting, are optimized to maximize the minimum multi-target echo signal-to-interference-plus-noise ratio under multi-user rate and power constraints. The intricate non-convex problem is decoupled into three subproblems and solved iteratively by majorization-minimization (MM) and sequential rank-one constraint relaxation (SROCR) algorithms. Simulations show our scheme outperforms nonorthogonal multiple access, space-division multiple access, and passive RIS baselines, approaching sensing-only upper bounds.
LSRIF: Logic-Structured Reinforcement Learning for Instruction Following
Jan 10, 2026Instruction-following is critical for large language models, but real-world instructions often contain logical structures such as sequential dependencies and conditional branching. Existing methods typically construct datasets with parallel constraints and optimize average rewards, ignoring logical dependencies and yielding noisy signals. We propose a logic-structured training framework LSRIF that explicitly models instruction logic. We first construct a dataset LSRInstruct with constraint structures such as parallel, sequential, and conditional types, and then design structure-aware rewarding method LSRIF including average aggregation for parallel structures, failure-penalty propagation for sequential structures, and selective rewards for conditional branches. Experiments show LSRIF brings significant improvements in instruction-following (in-domain and out-of-domain) and general reasoning. Analysis reveals that learning with explicit logic structures brings parameter updates in attention layers and sharpens token-level attention to constraints and logical operators.
Instructions are all you need: Self-supervised Reinforcement Learning for Instruction Following
Oct 16, 2025Language models often struggle to follow multi-constraint instructions that are crucial for real-world applications. Existing reinforcement learning (RL) approaches suffer from dependency on external supervision and sparse reward signals from multi-constraint tasks. We propose a label-free self-supervised RL framework that eliminates dependency on external supervision by deriving reward signals directly from instructions and generating pseudo-labels for reward model training. Our approach introduces constraint decomposition strategies and efficient constraint-wise binary classification to address sparse reward challenges while maintaining computational efficiency. Experiments show that our approach generalizes well, achieving strong improvements across 3 in-domain and 5 out-of-domain datasets, including challenging agentic and multi-turn instruction following. The data and code are publicly available at https://github.com/Rainier-rq/verl-if
HS-SLAM: A Fast and Hybrid Strategy-Based SLAM Approach for Low-Speed Autonomous Driving
May 27, 2025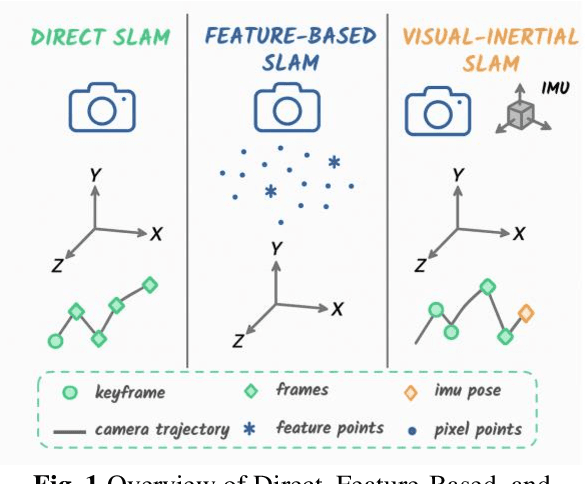


Visual-inertial simultaneous localization and mapping (SLAM) is a key module of robotics and low-speed autonomous vehicles, which is usually limited by the high computation burden for practical applications. To this end, an innovative strategy-based hybrid framework HS-SLAM is proposed to integrate the advantages of direct and feature-based methods for fast computation without decreasing the performance. It first estimates the relative positions of consecutive frames using IMU pose estimation within the tracking thread. Then, it refines these estimates through a multi-layer direct method, which progressively corrects the relative pose from coarse to fine, ultimately achieving accurate corner-based feature matching. This approach serves as an alternative to the conventional constant-velocity tracking model. By selectively bypassing descriptor extraction for non-critical frames, HS-SLAM significantly improves the tracking speed. Experimental evaluations on the EuRoC MAV dataset demonstrate that HS-SLAM achieves higher localization accuracies than ORB-SLAM3 while improving the average tracking efficiency by 15%.
Large-Scale AI in Telecom: Charting the Roadmap for Innovation, Scalability, and Enhanced Digital Experiences
Mar 06, 2025



This white paper discusses the role of large-scale AI in the telecommunications industry, with a specific focus on the potential of generative AI to revolutionize network functions and user experiences, especially in the context of 6G systems. It highlights the development and deployment of Large Telecom Models (LTMs), which are tailored AI models designed to address the complex challenges faced by modern telecom networks. The paper covers a wide range of topics, from the architecture and deployment strategies of LTMs to their applications in network management, resource allocation, and optimization. It also explores the regulatory, ethical, and standardization considerations for LTMs, offering insights into their future integration into telecom infrastructure. The goal is to provide a comprehensive roadmap for the adoption of LTMs to enhance scalability, performance, and user-centric innovation in telecom networks.
Order Matters: Investigate the Position Bias in Multi-constraint Instruction Following
Feb 24, 2025



Real-world instructions with multiple constraints pose a significant challenge to existing large language models (LLMs). An observation is that the LLMs exhibit dramatic performance fluctuation when disturbing the order of the incorporated constraints. Yet, none of the existing works has systematically investigated this position bias problem in the field of multi-constraint instruction following. To bridge this gap, we design a probing task where we quantitatively measure the difficulty distribution of the constraints by a novel Difficulty Distribution Index (CDDI). Through the experimental results, we find that LLMs are more performant when presented with the constraints in a ``hard-to-easy'' order. This preference can be generalized to LLMs with different architecture or different sizes of parameters. Additionally, we conduct an explanation study, providing an intuitive insight into the correlation between the LLM's attention and constraint orders. Our code and dataset are publicly available at https://github.com/meowpass/PBIF.
Step-by-Step Mastery: Enhancing Soft Constraint Following Ability of Large Language Models
Jan 09, 2025It is crucial for large language models (LLMs) to follow instructions that involve multiple constraints. However, soft constraints are semantically related and difficult to verify through automated methods. These constraints remain a significant challenge for LLMs. To enhance the ability of LLMs to follow soft constraints, we initially design a pipeline to obtain high-quality outputs automatically. Additionally, to fully utilize the acquired data, we introduce a training paradigm based on curriculum learning. We experimentally evaluate the effectiveness of our methods in improving LLMs' soft constraint following ability and analyze the factors driving the improvements. The datasets and code are publicly available at https://github.com/Rainier-rq/FollowSoftConstraints.
Self-Training with Pseudo-Label Scorer for Aspect Sentiment Quad Prediction
Jun 26, 2024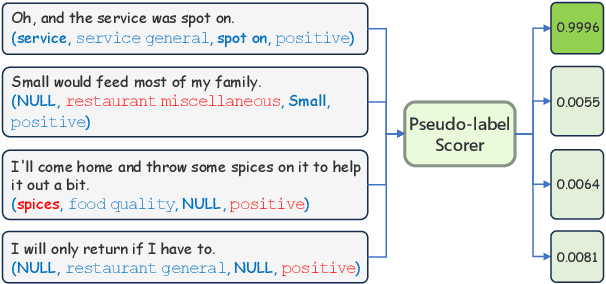
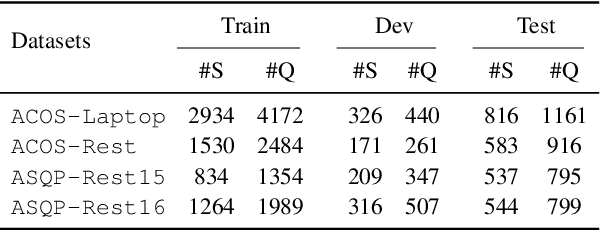
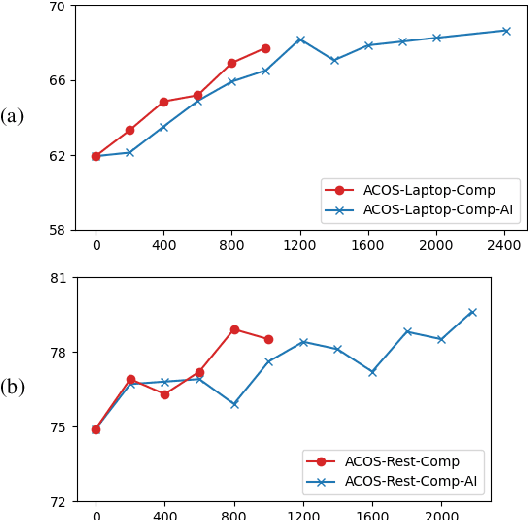
Aspect Sentiment Quad Prediction (ASQP) aims to predict all quads (aspect term, aspect category, opinion term, sentiment polarity) for a given review, which is the most representative and challenging task in aspect-based sentiment analysis. A key challenge in the ASQP task is the scarcity of labeled data, which limits the performance of existing methods. To tackle this issue, we propose a self-training framework with a pseudo-label scorer, wherein a scorer assesses the match between reviews and their pseudo-labels, aiming to filter out mismatches and thereby enhance the effectiveness of self-training. We highlight two critical aspects to ensure the scorer's effectiveness and reliability: the quality of the training dataset and its model architecture. To this end, we create a human-annotated comparison dataset and train a generative model on it using ranking-based objectives. Extensive experiments on public ASQP datasets reveal that using our scorer can greatly and consistently improve the effectiveness of self-training. Moreover, we explore the possibility of replacing humans with large language models for comparison dataset annotation, and experiments demonstrate its feasibility. We release our code and data at https://github.com/HITSZ-HLT/ST-w-Scorer-ABSA .
From Complex to Simple: Enhancing Multi-Constraint Complex Instruction Following Ability of Large Language Models
Apr 24, 2024It is imperative for Large language models (LLMs) to follow instructions with elaborate requirements (i.e. Complex Instructions Following). Yet, it remains under-explored how to enhance the ability of LLMs to follow complex instructions with multiple constraints. To bridge the gap, we initially study what training data is effective in enhancing complex constraints following abilities. We found that training LLMs with instructions containing multiple constraints enhances their understanding of complex instructions, especially those with lower complexity levels. The improvement can even generalize to compositions of out-of-domain constraints. Additionally, we further propose methods addressing how to obtain and utilize the effective training data. Finally, we conduct extensive experiments to prove the effectiveness of our methods in terms of overall performance, training efficiency, and generalization abilities under four settings.