 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePASTE: Physics-Aware Scattering Topology Embedding Framework for SAR Object Detection
Mar 16, 2026Current deep learning-based object detection for Synthetic Aperture Radar (SAR) imagery mainly adopts optical image methods, treating targets as texture patches while ignoring inherent electromagnetic scattering mechanisms. Though scattering points have been studied to boost detection performance, most methods still rely on amplitude-based statistical models. Some approaches introduce frequency-domain information for scattering center extraction, but they suffer from high computation cost and poor compatibility with diverse datasets. Thus, effectively embedding scattering topological information into modern detection frameworks remains challenging. To solve these problems, this paper proposes the Physics-Aware Scattering Topology Embedding Framework (PASTE), a novel closed-loop architecture for comprehensive scattering prior integration. By building the full pipeline from topology generation, injection to joint supervision, PASTE elegantly integrates scattering physics into modern SAR detectors. Specifically, it designs a scattering keypoint generation and automatic annotation scheme based on the Attributed Scattering Center (ASC) model to produce scalable and physically consistent priors. A scattering topology injection module guides multi-scale feature learning, and a scattering prior supervision strategy constrains network optimization by aligning predictions with scattering center distributions. Experiments on real datasets show that PASTE is compatible with various detectors and brings relative mAP gains of 2.9% to 11.3% over baselines with acceptable computation overhead. Visualization of scattering maps verifies that PASTE successfully embeds scattering topological priors into feature space, clearly distinguishing target and background scattering regions, thus providing strong interpretability for results.
CrossEarth-SAR: A SAR-Centric and Billion-Scale Geospatial Foundation Model for Domain Generalizable Semantic Segmentation
Mar 12, 2026Synthetic Aperture Radar (SAR) enables global, all-weather earth observation. However, owing to diverse imaging mechanisms, domain shifts across sensors and regions severely hinder its semantic generalization. To address this, we present CrossEarth-SAR, the first billion-scale SAR vision foundation model built upon a novel physics-guided sparse mixture-of-experts (MoE) architecture incorporating physical descriptors, explicitly designed for cross-domain semantic segmentation. To facilitate large-scale pre-training, we develop CrossEarth-SAR-200K, a weakly and fully supervised dataset that unifies public and private SAR imagery. We also introduce a benchmark suite comprising 22 sub-benchmarks across 8 distinct domain gaps, establishing the first unified standard for domain generalization semantic segmentation on SAR imagery. Extensive experiments demonstrate that CrossEarth-SAR achieves state-of-the-art results on 20 benchmarks, surpassing previous methods by over 10\% mIoU on some benchmarks under multi-gap transfer. All code, benchmark and datasets will be publicly available.
FUSAR-GPT : A Spatiotemporal Feature-Embedded and Two-Stage Decoupled Visual Language Model for SAR Imagery
Feb 26, 2026Research on the intelligent interpretation of all-weather, all-time Synthetic Aperture Radar (SAR) is crucial for advancing remote sensing applications. In recent years, although Visual Language Models (VLMs) have demonstrated strong open-world understanding capabilities on RGB images, their performance is severely limited when directly applied to the SAR field due to the complexity of the imaging mechanism, sensitivity to scattering features, and the scarcity of high-quality text corpora. To systematically address this issue, we constructed the inaugural SAR Image-Text-AlphaEarth feature triplet dataset and developed FUSAR-GPT, a VLM specifically for SAR. FUSAR-GPT innovatively introduces a geospatial baseline model as a 'world knowledge' prior and embeds multi-source remote-sensing temporal features into the model's visual backbone via 'spatiotemporal anchors', enabling dynamic compensation for the sparse representation of targets in SAR images. Furthermore, we designed a two-stage SFT strategy to decouple the knowledge injection and task execution of large models. The spatiotemporal feature embedding and the two-stage decoupling paradigm enable FUSAR-GPT to achieve state-of-the-art performance across several typical remote sensing visual-language benchmark tests, significantly outperforming mainstream baseline models by over 12%.
Error-Propagation-Free Learned Video Compression With Dual-Domain Progressive Temporal Alignment
Dec 11, 2025Existing frameworks for learned video compression suffer from a dilemma between inaccurate temporal alignment and error propagation for motion estimation and compensation (ME/MC). The separate-transform framework employs distinct transforms for intra-frame and inter-frame compression to yield impressive rate-distortion (R-D) performance but causes evident error propagation, while the unified-transform framework eliminates error propagation via shared transforms but is inferior in ME/MC in shared latent domains. To address this limitation, in this paper, we propose a novel unifiedtransform framework with dual-domain progressive temporal alignment and quality-conditioned mixture-of-expert (QCMoE) to enable quality-consistent and error-propagation-free streaming for learned video compression. Specifically, we propose dualdomain progressive temporal alignment for ME/MC that leverages coarse pixel-domain alignment and refined latent-domain alignment to significantly enhance temporal context modeling in a coarse-to-fine fashion. The coarse pixel-domain alignment efficiently handles simple motion patterns with optical flow estimated from a single reference frame, while the refined latent-domain alignment develops a Flow-Guided Deformable Transformer (FGDT) over latents from multiple reference frames to achieve long-term motion refinement (LTMR) for complex motion patterns. Furthermore, we design a QCMoE module for continuous bit-rate adaptation that dynamically assigns different experts to adjust quantization steps per pixel based on target quality and content rather than relies on a single quantization step. QCMoE allows continuous and consistent rate control with appealing R-D performance. Experimental results show that the proposed method achieves competitive R-D performance compared with the state-of-the-arts, while successfully eliminating error propagation.
When Segmentation Meets Hyperspectral Image: New Paradigm for Hyperspectral Image Classification
Feb 18, 2025Hyperspectral image (HSI) classification is a cornerstone of remote sensing, enabling precise material and land-cover identification through rich spectral information. While deep learning has driven significant progress in this task, small patch-based classifiers, which account for over 90% of the progress, face limitations: (1) the small patch (e.g., 7x7, 9x9)-based sampling approach considers a limited receptive field, resulting in insufficient spatial structural information critical for object-level identification and noise-like misclassifications even within uniform regions; (2) undefined optimal patch sizes lead to coarse label predictions, which degrade performance; and (3) a lack of multi-shape awareness around objects. To address these challenges, we draw inspiration from large-scale image segmentation techniques, which excel at handling object boundaries-a capability essential for semantic labeling in HSI classification. However, their application remains under-explored in this task due to (1) the prevailing notion that larger patch sizes degrade performance, (2) the extensive unlabeled regions in HSI groundtruth, and (3) the misalignment of input shapes between HSI data and segmentation models. Thus, in this study, we propose a novel paradigm and baseline, HSIseg, for HSI classification that leverages segmentation techniques combined with a novel Dynamic Shifted Regional Transformer (DSRT) to overcome these challenges. We also introduce an intuitive progressive learning framework with adaptive pseudo-labeling to iteratively incorporate unlabeled regions into the training process, thereby advancing the application of segmentation techniques. Additionally, we incorporate auxiliary data through multi-source data collaboration, promoting better feature interaction. Validated on five public HSI datasets, our proposal outperforms state-of-the-art methods.
Contrastive Representation Distillation via Multi-Scale Feature Decoupling
Feb 09, 2025



Knowledge distillation is a technique aimed at enhancing the performance of a smaller student network without increasing its parameter size by transferring knowledge from a larger, pre-trained teacher network. Previous approaches have predominantly focused on distilling global feature information while overlooking the importance of disentangling the diverse types of information embedded within different regions of the feature. In this work, we introduce multi-scale decoupling in the feature transfer process for the first time, where the decoupled local features are individually processed and integrated with contrastive learning. Moreover, compared to previous contrastive learning-based distillation methods, our approach not only reduces computational costs but also enhances efficiency, enabling performance improvements for the student network using only single-batch samples. Extensive evaluations on CIFAR-100 and ImageNet demonstrate our method's superiority, with some student networks distilled using our method even surpassing the performance of their pre-trained teacher networks. These results underscore the effectiveness of our approach in enabling student networks to thoroughly absorb knowledge from teacher networks.
Reciprocal Point Learning Network with Large Electromagnetic Kernel for SAR Open-Set Recognition
Nov 07, 2024



The limitations of existing Synthetic Aperture Radar (SAR) Automatic Target Recognition (ATR) methods lie in their confinement by the closed-environment assumption, hindering their effective and robust handling of unknown target categories in open environments. Open Set Recognition (OSR), a pivotal facet for algorithmic practicality, intends to categorize known classes while denoting unknown ones as "unknown." The chief challenge in OSR involves concurrently mitigating risks associated with generalizing features from a restricted set of known classes to numerous unknown samples and the open space exposure to potential unknown data. To enhance open-set SAR classification, a method called scattering kernel with reciprocal learning network is proposed. Initially, a feature learning framework is constructed based on reciprocal point learning (RPL), establishing a bounded space for potential unknown classes. This approach indirectly introduces unknown information into a learner confined to known classes, thereby acquiring more concise and discriminative representations. Subsequently, considering the variability in the imaging of targets at different angles and the discreteness of components in SAR images, a proposal is made to design convolutional kernels based on large-sized attribute scattering center models. This enhances the ability to extract intrinsic non-linear features and specific scattering characteristics in SAR images, thereby improving the discriminative features of the model and mitigating the impact of imaging variations on classification performance. Experiments on the MSTAR datasets substantiate the superior performance of the proposed approach called ASC-RPL over mainstream methods.
OSAD: Open-Set Aircraft Detection in SAR Images
Nov 03, 2024



Current mainstream SAR image object detection methods still lack robustness when dealing with unknown objects in open environments. Open-set detection aims to enable detectors trained on a closed set to detect all known objects and identify unknown objects in open-set environments. The key challenges are how to improve the generalization to potential unknown objects and reduce the empirical classification risk of known categories under strong supervision. To address these challenges, a novel open-set aircraft detector for SAR images is proposed, named Open-Set Aircraft Detection (OSAD), which is equipped with three dedicated components: global context modeling (GCM), location quality-driven pseudo labeling generation (LPG), and prototype contrastive learning (PCL). GCM effectively enhances the network's representation of objects by attention maps which is formed through the capture of long sequential positional relationships. LPG leverages clues about object positions and shapes to optimize localization quality, avoiding overfitting to known category information and enhancing generalization to potential unknown objects. PCL employs prototype-based contrastive encoding loss to promote instance-level intra-class compactness and inter-class variance, aiming to minimize the overlap between known and unknown distributions and reduce the empirical classification risk of known categories. Extensive experiments have demonstrated that the proposed method can effectively detect unknown objects and exhibit competitive performance without compromising closed-set performance. The highest absolute gain which ranges from 0 to 18.36% can be achieved on the average precision of unknown objects.
EMWaveNet: Physically Explainable Neural Network Based on Microwave Propagation for SAR Target Recognition
Oct 13, 2024



Deep learning technologies have achieved significant performance improvements in the field of synthetic aperture radar (SAR) image target recognition over traditional methods. However, the inherent "black box" property of deep learning models leads to a lack of transparency in decision-making processes, making them difficult to be convincingly applied in practice. This is especially true in SAR applications, where the credibility and reliability of model predictions are crucial. The complexity and insufficient explainability of deep networks have become a bottleneck for their application. To tackle this issue, this study proposes a physically explainable framework for complex-valued SAR image recognition, designed based on the physical process of microwave propagation. This framework utilizes complex-valued SAR data to explore the amplitude and phase information and its intrinsic physical properties. The network architecture is fully parameterized, with all learnable parameters endowed with clear physical meanings, and the computational process is completed entirely in the frequency domain. Experiments on both the complex-valued MSTAR dataset and a self-built Qilu-1 complex-valued dataset were conducted to validate the effectiveness of framework. In conditions of target overlap, our model discerns categories others find challenging. Against 0dB forest background noise, it boasts a 20% accuracy improvement over traditional neural networks. When targets are 60% masked by noise, it still outperforms other models by 9%. An end-to-end complex-valued synthetic aperture radar automatic target recognition (SAR-ATR) system has also been constructed to perform recognition tasks in interference SAR scenarios. The results demonstrate that the proposed method possesses a strong physical decision logic, high physical explainability and robustness, as well as excellent dealiasing capabilities.
FDiff-Fusion:Denoising diffusion fusion network based on fuzzy learning for 3D medical image segmentation
Jul 22, 2024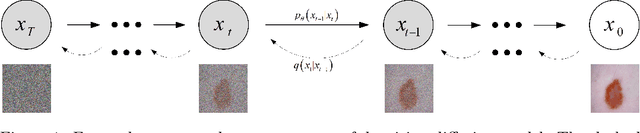

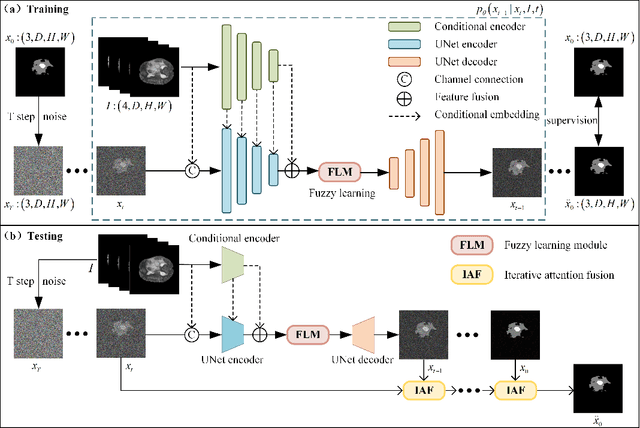
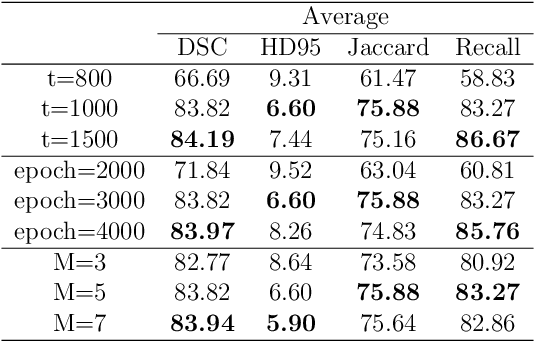
In recent years, the denoising diffusion model has achieved remarkable success in image segmentation modeling. With its powerful nonlinear modeling capabilities and superior generalization performance, denoising diffusion models have gradually been applied to medical image segmentation tasks, bringing new perspectives and methods to this field. However, existing methods overlook the uncertainty of segmentation boundaries and the fuzziness of regions, resulting in the instability and inaccuracy of the segmentation results. To solve this problem, a denoising diffusion fusion network based on fuzzy learning for 3D medical image segmentation (FDiff-Fusion) is proposed in this paper. By integrating the denoising diffusion model into the classical U-Net network, this model can effectively extract rich semantic information from input medical images, thus providing excellent pixel-level representation for medical image segmentation. ... Finally, to validate the effectiveness of FDiff-Fusion, we compare it with existing advanced segmentation networks on the BRATS 2020 brain tumor dataset and the BTCV abdominal multi-organ dataset. The results show that FDiff-Fusion significantly improves the Dice scores and HD95 distance on these two datasets, demonstrating its superiority in medical image segmentation tasks.
* This paper has been accepted by Information Fusion. Permission from Elsevier must be obtained for all other uses, in any current or future media. The final version is available at [doi:10.1016/J.INFFUS.2024.102540]