 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Segmentation Meets Hyperspectral Image: New Paradigm for Hyperspectral Image Classification
Feb 18, 2025Hyperspectral image (HSI) classification is a cornerstone of remote sensing, enabling precise material and land-cover identification through rich spectral information. While deep learning has driven significant progress in this task, small patch-based classifiers, which account for over 90% of the progress, face limitations: (1) the small patch (e.g., 7x7, 9x9)-based sampling approach considers a limited receptive field, resulting in insufficient spatial structural information critical for object-level identification and noise-like misclassifications even within uniform regions; (2) undefined optimal patch sizes lead to coarse label predictions, which degrade performance; and (3) a lack of multi-shape awareness around objects. To address these challenges, we draw inspiration from large-scale image segmentation techniques, which excel at handling object boundaries-a capability essential for semantic labeling in HSI classification. However, their application remains under-explored in this task due to (1) the prevailing notion that larger patch sizes degrade performance, (2) the extensive unlabeled regions in HSI groundtruth, and (3) the misalignment of input shapes between HSI data and segmentation models. Thus, in this study, we propose a novel paradigm and baseline, HSIseg, for HSI classification that leverages segmentation techniques combined with a novel Dynamic Shifted Regional Transformer (DSRT) to overcome these challenges. We also introduce an intuitive progressive learning framework with adaptive pseudo-labeling to iteratively incorporate unlabeled regions into the training process, thereby advancing the application of segmentation techniques. Additionally, we incorporate auxiliary data through multi-source data collaboration, promoting better feature interaction. Validated on five public HSI datasets, our proposal outperforms state-of-the-art methods.
Mamba-in-Mamba: Centralized Mamba-Cross-Scan in Tokenized Mamba Model for Hyperspectral Image Classification
May 20, 2024



Hyperspectral image (HSI) classification is pivotal in the remote sensing (RS) field, particularly with the advancement of deep learning techniques. Sequential models, adapted from the natural language processing (NLP) field such as Recurrent Neural Networks (RNNs) and Transformers, have been tailored to this task, offering a unique viewpoint. However, several challenges persist 1) RNNs struggle with centric feature aggregation and are sensitive to interfering pixels, 2) Transformers require significant computational resources and often underperform with limited HSI training samples, and 3) Current scanning methods for converting images into sequence-data are simplistic and inefficient. In response, this study introduces the innovative Mamba-in-Mamba (MiM) architecture for HSI classification, the first attempt of deploying State Space Model (SSM) in this task. The MiM model includes 1) A novel centralized Mamba-Cross-Scan (MCS) mechanism for transforming images into sequence-data, 2) A Tokenized Mamba (T-Mamba) encoder that incorporates a Gaussian Decay Mask (GDM), a Semantic Token Learner (STL), and a Semantic Token Fuser (STF) for enhanced feature generation and concentration, and 3) A Weighted MCS Fusion (WMF) module coupled with a Multi-Scale Loss Design to improve decoding efficiency. Experimental results from three public HSI datasets with fixed and disjoint training-testing samples demonstrate that our method outperforms existing baselines and state-of-the-art approaches, highlighting its efficacy and potential in HSI applications.
Rethinking ResNets: Improved Stacking Strategies With High Order Schemes
Apr 12, 2021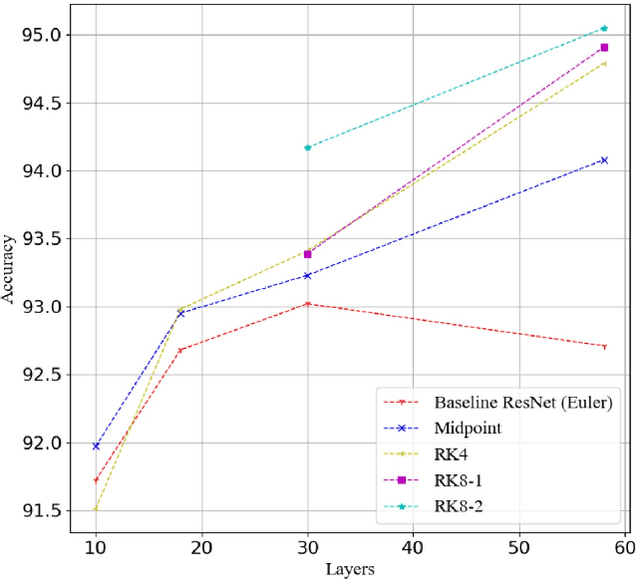

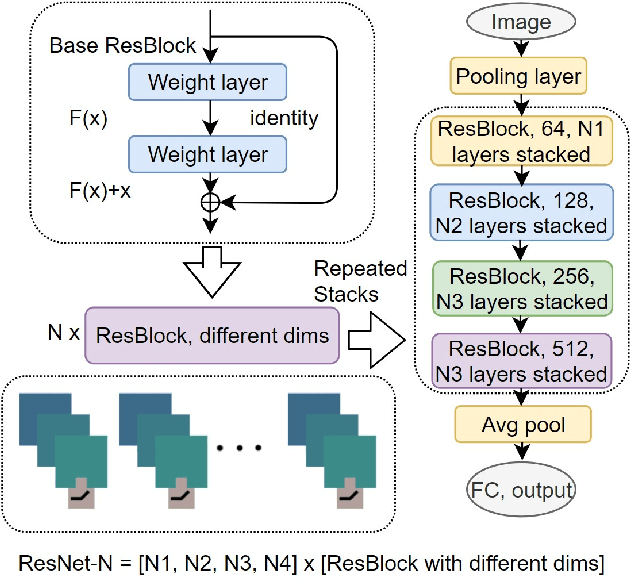
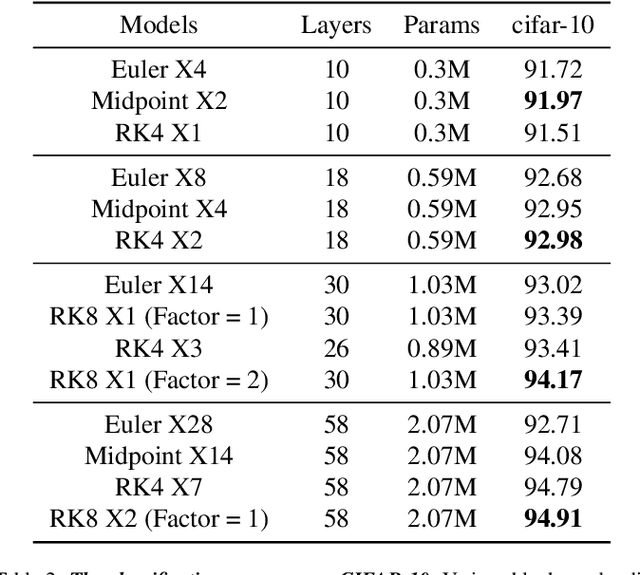
Various Deep Neural Network architectures are keeping massive vital records in computer vision. While drawing attention worldwide, the design of the overall structure somehow lacks general guidance. Based on the relationship between DNN design with numerical differential equations, which several researchers observed in recent years, we perform a fair comparison of residual design with higher-order perspectives. We show that the widely used DNN design strategy, constantly stacking a small design, could be easily improved, supported by solid theoretical knowledge and no extra parameters needed. We reorganize the residual design in higher-order ways, which is inspired by the observation that many effective networks could be interpreted as different numerical discretizations of differential equations. The design of ResNet follows a relatively simple scheme which is Euler forward; however, the situation is getting complicated rapidly while stacking. We suppose stacked ResNet is somehow equalled to a higher order scheme, then the current way of forwarding propagation might be relatively weak compared with a typical high-order method like Runge-Kutta. We propose higher order ResNet to verify the hypothesis on widely used CV benchmarks with sufficient experiments. Stable and noticeable rises in performance are observed, convergence and robustness are benefited.
Learning Gaussian Graphical Models Using Discriminated Hub Graphical Lasso
May 17, 2017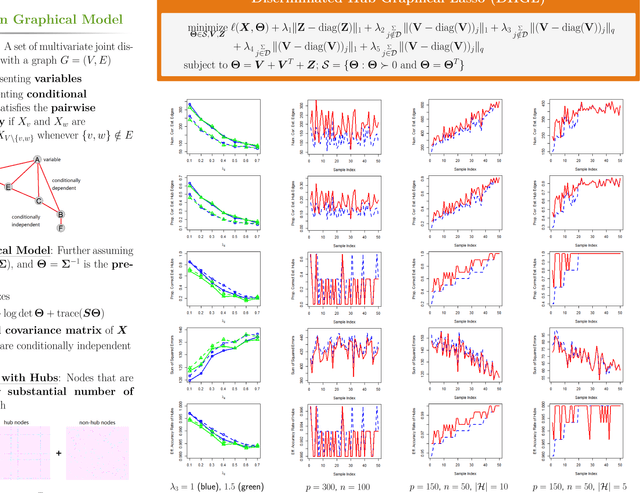
We develop a new method called Discriminated Hub Graphical Lasso (DHGL) based on Hub Graphical Lasso (HGL) by providing prior information of hubs. We apply this new method in two situations: with known hubs and without known hubs. Then we compare DHGL with HGL using several measures of performance. When some hubs are known, we can always estimate the precision matrix better via DHGL than HGL. When no hubs are known, we use Graphical Lasso (GL) to provide information of hubs and find that the performance of DHGL will always be better than HGL if correct prior information is given and will seldom degenerate when the prior information is wrong.