 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Learning Optical Flow in Multi-frame Dynamic Environment Using Temporal Dynamic Modeling
Apr 14, 2023

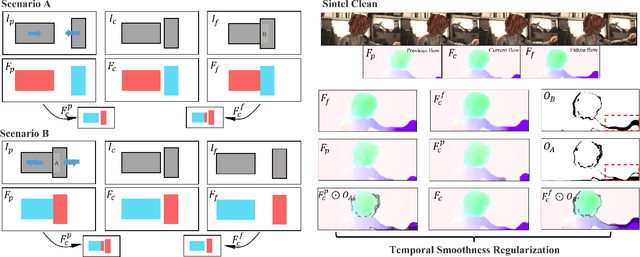

For visual estimation of optical flow, a crucial function for many vision tasks, unsupervised learning, using the supervision of view synthesis has emerged as a promising alternative to supervised methods, since ground-truth flow is not readily available in many cases. However, unsupervised learning is likely to be unstable when pixel tracking is lost due to occlusion and motion blur, or the pixel matching is impaired due to variation in image content and spatial structure over time. In natural environments, dynamic occlusion or object variation is a relatively slow temporal process spanning several frames. We, therefore, explore the optical flow estimation from multiple-frame sequences of dynamic scenes, whereas most of the existing unsupervised approaches are based on temporal static models. We handle the unsupervised optical flow estimation with a temporal dynamic model by introducing a spatial-temporal dual recurrent block based on the predictive coding structure, which feeds the previous high-level motion prior to the current optical flow estimator. Assuming temporal smoothness of optical flow, we use motion priors of the adjacent frames to provide more reliable supervision of the occluded regions. To grasp the essence of challenging scenes, we simulate various scenarios across long sequences, including dynamic occlusion, content variation, and spatial variation, and adopt self-supervised distillation to make the model understand the object's motion patterns in a prolonged dynamic environment. Experiments on KITTI 2012, KITTI 2015, Sintel Clean, and Sintel Final datasets demonstrate the effectiveness of our methods on unsupervised optical flow estimation. The proposal achieves state-of-the-art performance with advantages in memory overhead.
Biomedical image analysis competitions: The state of current participation practice
Dec 16, 2022The number of international benchmarking competitions is steadily increasing in various fields of machine learning (ML) research and practice. So far, however, little is known about the common practice as well as bottlenecks faced by the community in tackling the research questions posed. To shed light on the status quo of algorithm development in the specific field of biomedical imaging analysis, we designed an international survey that was issued to all participants of challenges conducted in conjunction with the IEEE ISBI 2021 and MICCAI 2021 conferences (80 competitions in total). The survey covered participants' expertise and working environments, their chosen strategies, as well as algorithm characteristics. A median of 72% challenge participants took part in the survey. According to our results, knowledge exchange was the primary incentive (70%) for participation, while the reception of prize money played only a minor role (16%). While a median of 80 working hours was spent on method development, a large portion of participants stated that they did not have enough time for method development (32%). 25% perceived the infrastructure to be a bottleneck. Overall, 94% of all solutions were deep learning-based. Of these, 84% were based on standard architectures. 43% of the respondents reported that the data samples (e.g., images) were too large to be processed at once. This was most commonly addressed by patch-based training (69%), downsampling (37%), and solving 3D analysis tasks as a series of 2D tasks. K-fold cross-validation on the training set was performed by only 37% of the participants and only 50% of the participants performed ensembling based on multiple identical models (61%) or heterogeneous models (39%). 48% of the respondents applied postprocessing steps.
Rethinking ResNets: Improved Stacking Strategies With High Order Schemes
Apr 12, 2021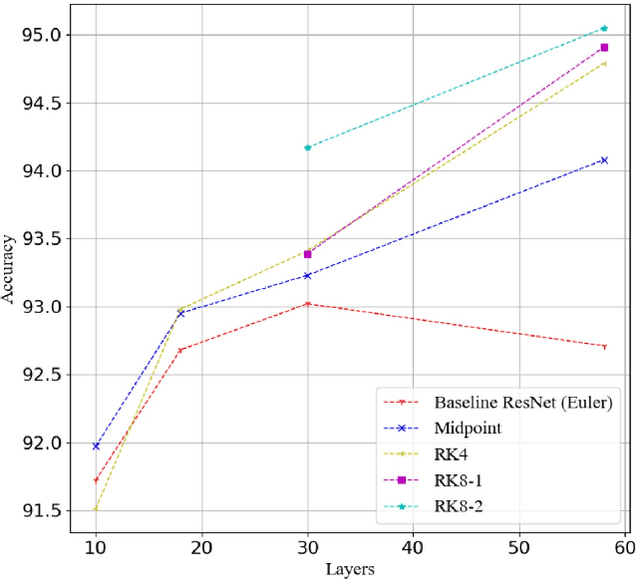

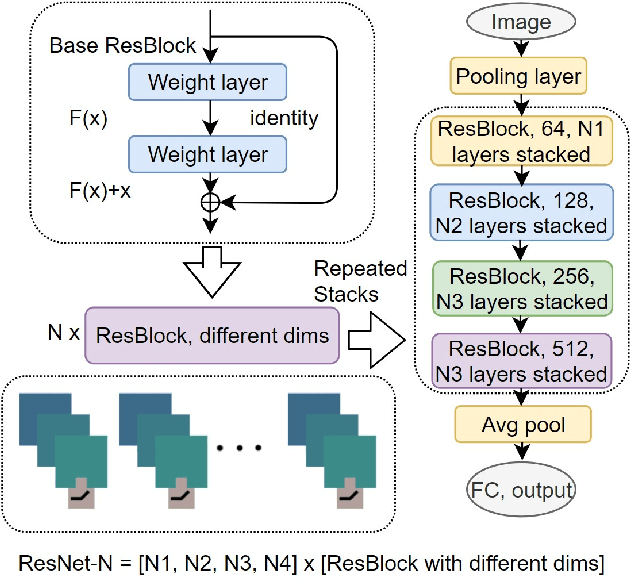
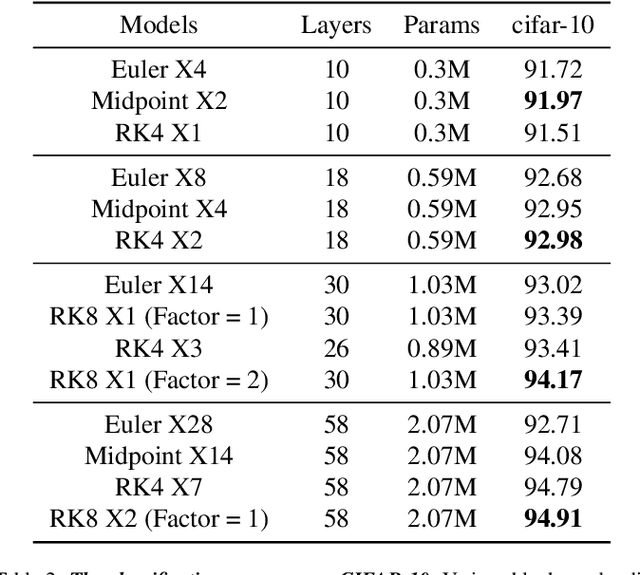
Various Deep Neural Network architectures are keeping massive vital records in computer vision. While drawing attention worldwide, the design of the overall structure somehow lacks general guidance. Based on the relationship between DNN design with numerical differential equations, which several researchers observed in recent years, we perform a fair comparison of residual design with higher-order perspectives. We show that the widely used DNN design strategy, constantly stacking a small design, could be easily improved, supported by solid theoretical knowledge and no extra parameters needed. We reorganize the residual design in higher-order ways, which is inspired by the observation that many effective networks could be interpreted as different numerical discretizations of differential equations. The design of ResNet follows a relatively simple scheme which is Euler forward; however, the situation is getting complicated rapidly while stacking. We suppose stacked ResNet is somehow equalled to a higher order scheme, then the current way of forwarding propagation might be relatively weak compared with a typical high-order method like Runge-Kutta. We propose higher order ResNet to verify the hypothesis on widely used CV benchmarks with sufficient experiments. Stable and noticeable rises in performance are observed, convergence and robustness are benefited.