 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding Reasonable Inference for Vision-Language Models in Blind Image Quality Assessment
Dec 10, 2025Recent progress in BIQA has been driven by VLMs, whose semantic reasoning abilities suggest that they might extract visual features, generate descriptive text, and infer quality in a human-like manner. However, these models often produce textual descriptions that contradict their final quality predictions, and the predicted scores can change unstably during inference - behaviors not aligned with human reasoning. To understand these issues, we analyze the factors that cause contradictory assessments and instability. We first estimate the relationship between the final quality predictions and the generated visual features, finding that the predictions are not fully grounded in the features and that the logical connection between them is weak. Moreover, decoding intermediate VLM layers shows that the model frequently relies on a limited set of candidate tokens, which contributes to prediction instability. To encourage more human-like reasoning, we introduce a two-stage tuning method that explicitly separates visual perception from quality inference. In the first stage, the model learns visual features; in the second, it infers quality solely from these features. Experiments on SPAQ and KONIQ demonstrate that our approach reduces prediction instability from 22.00% to 12.39% and achieves average gains of 0.3124/0.3507 in SRCC/PLCC across LIVE, CSIQ, SPAQ, and KONIQ compared to the baseline. Further analyses show that our method improves both stability and the reliability of the inference process.
* Accepted to the ICONIP (International Conference on Neural Information Processing), 2025
Investigate the Low-level Visual Perception in Vision-Language based Image Quality Assessment
Dec 10, 2025Recent advances in Image Quality Assessment (IQA) have leveraged Multi-modal Large Language Models (MLLMs) to generate descriptive explanations. However, despite their strong visual perception modules, these models often fail to reliably detect basic low-level distortions such as blur, noise, and compression, and may produce inconsistent evaluations across repeated inferences. This raises an essential question: do MLLM-based IQA systems truly perceive the visual features that matter? To examine this issue, we introduce a low-level distortion perception task that requires models to classify specific distortion types. Our component-wise analysis shows that although MLLMs are structurally capable of representing such distortions, they tend to overfit training templates, leading to biases in quality scoring. As a result, critical low-level features are weakened or lost during the vision-language alignment transfer stage. Furthermore, by computing the semantic distance between visual features and corresponding semantic tokens before and after component-wise fine-tuning, we show that improving the alignment of the vision encoder dramatically enhances distortion recognition accuracy, increasing it from 14.92% to 84.43%. Overall, these findings indicate that incorporating dedicated constraints on the vision encoder can strengthen text-explainable visual representations and enable MLLM-based pipelines to produce more coherent and interpretable reasoning in vision-centric tasks.
Online Data Curation for Object Detection via Marginal Contributions to Dataset-level Average Precision
Nov 18, 2025High-quality data has become a primary driver of progress under scale laws, with curated datasets often outperforming much larger unfiltered ones at lower cost. Online data curation extends this idea by dynamically selecting training samples based on the model's evolving state. While effective in classification and multimodal learning, existing online sampling strategies rarely extend to object detection because of its structural complexity and domain gaps. We introduce DetGain, an online data curation method specifically for object detection that estimates the marginal perturbation of each image to dataset-level Average Precision (AP) based on its prediction quality. By modeling global score distributions, DetGain efficiently estimates the global AP change and computes teacher-student contribution gaps to select informative samples at each iteration. The method is architecture-agnostic and minimally intrusive, enabling straightforward integration into diverse object detection architectures. Experiments on the COCO dataset with multiple representative detectors show consistent improvements in accuracy. DetGain also demonstrates strong robustness under low-quality data and can be effectively combined with knowledge distillation techniques to further enhance performance, highlighting its potential as a general and complementary strategy for data-efficient object detection.
Modelling Human Visual Motion Processing with Trainable Motion Energy Sensing and a Self-attention Network for Adaptive Motion Integration
May 16, 2023



Visual motion processing is essential for organisms to perceive and interact with dynamic environments. Despite extensive research in cognitive neuroscience, image-computable models that can extract informative motion flow from natural scenes in a manner consistent with human visual processing have yet to be established. Meanwhile, recent advancements in computer vision (CV), propelled by deep learning, have led to significant progress in optical flow estimation, a task closely related to motion perception. Here we propose an image-computable model of human motion perception by bridging the gap between human and CV models. Specifically, we introduce a novel two-stage approach that combines trainable motion energy sensing with a recurrent self-attention network for adaptive motion integration and segregation. This model architecture aims to capture the computations in V1-MT, the core structure for motion perception in the biological visual system. In silico neurophysiology reveals that our model's unit responses are similar to mammalian neural recordings regarding motion pooling and speed tuning. The proposed model can also replicate human responses to a range of stimuli examined in past psychophysical studies. The experimental results on the Sintel benchmark demonstrate that our model predicts human responses better than the ground truth, whereas the CV models show the opposite. Further partial correlation analysis indicates our model outperforms several state-of-the-art CV models in explaining the human responses that deviate from the ground truth. Our study provides a computational architecture consistent with human visual motion processing, although the physiological correspondence may not be exact.
Unsupervised Learning Optical Flow in Multi-frame Dynamic Environment Using Temporal Dynamic Modeling
Apr 14, 2023

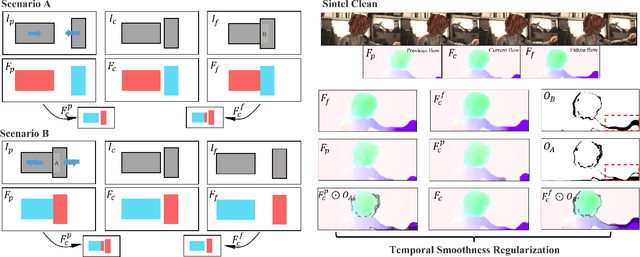

For visual estimation of optical flow, a crucial function for many vision tasks, unsupervised learning, using the supervision of view synthesis has emerged as a promising alternative to supervised methods, since ground-truth flow is not readily available in many cases. However, unsupervised learning is likely to be unstable when pixel tracking is lost due to occlusion and motion blur, or the pixel matching is impaired due to variation in image content and spatial structure over time. In natural environments, dynamic occlusion or object variation is a relatively slow temporal process spanning several frames. We, therefore, explore the optical flow estimation from multiple-frame sequences of dynamic scenes, whereas most of the existing unsupervised approaches are based on temporal static models. We handle the unsupervised optical flow estimation with a temporal dynamic model by introducing a spatial-temporal dual recurrent block based on the predictive coding structure, which feeds the previous high-level motion prior to the current optical flow estimator. Assuming temporal smoothness of optical flow, we use motion priors of the adjacent frames to provide more reliable supervision of the occluded regions. To grasp the essence of challenging scenes, we simulate various scenarios across long sequences, including dynamic occlusion, content variation, and spatial variation, and adopt self-supervised distillation to make the model understand the object's motion patterns in a prolonged dynamic environment. Experiments on KITTI 2012, KITTI 2015, Sintel Clean, and Sintel Final datasets demonstrate the effectiveness of our methods on unsupervised optical flow estimation. The proposal achieves state-of-the-art performance with advantages in memory overhead.
Rethinking ResNets: Improved Stacking Strategies With High Order Schemes
Apr 12, 2021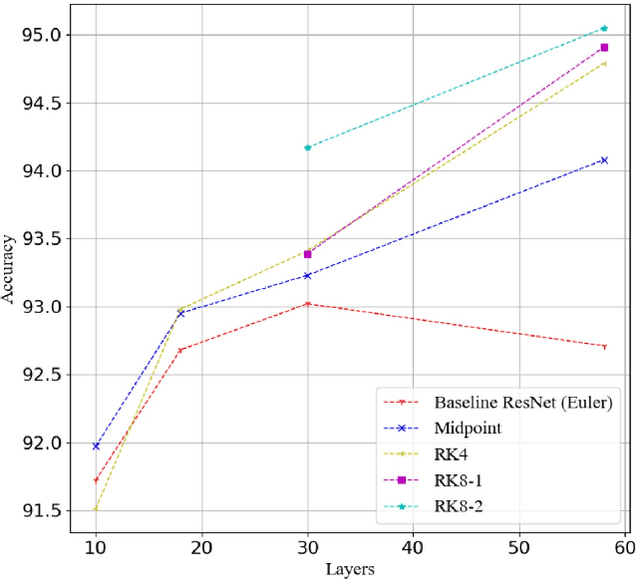

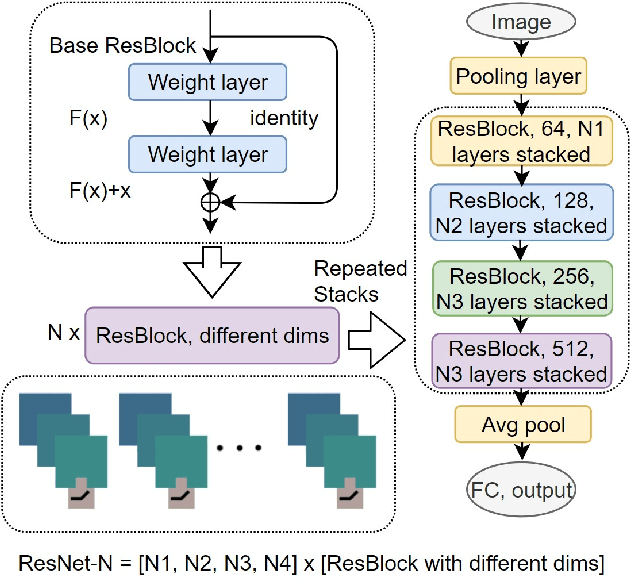
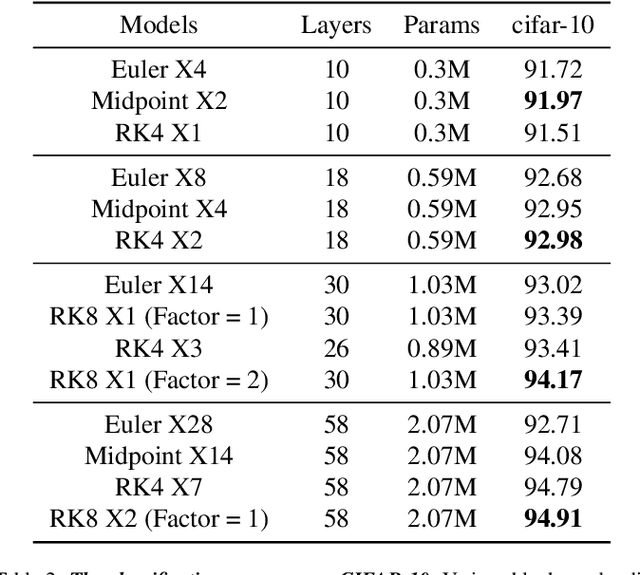
Various Deep Neural Network architectures are keeping massive vital records in computer vision. While drawing attention worldwide, the design of the overall structure somehow lacks general guidance. Based on the relationship between DNN design with numerical differential equations, which several researchers observed in recent years, we perform a fair comparison of residual design with higher-order perspectives. We show that the widely used DNN design strategy, constantly stacking a small design, could be easily improved, supported by solid theoretical knowledge and no extra parameters needed. We reorganize the residual design in higher-order ways, which is inspired by the observation that many effective networks could be interpreted as different numerical discretizations of differential equations. The design of ResNet follows a relatively simple scheme which is Euler forward; however, the situation is getting complicated rapidly while stacking. We suppose stacked ResNet is somehow equalled to a higher order scheme, then the current way of forwarding propagation might be relatively weak compared with a typical high-order method like Runge-Kutta. We propose higher order ResNet to verify the hypothesis on widely used CV benchmarks with sufficient experiments. Stable and noticeable rises in performance are observed, convergence and robustness are benefited.