 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA3Rank: Augmentation Alignment Analysis for Prioritizing Overconfident Failing Samples for Deep Learning Models
Jul 19, 2024
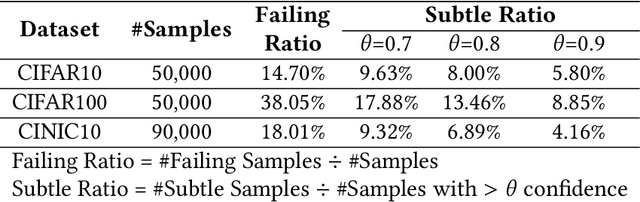
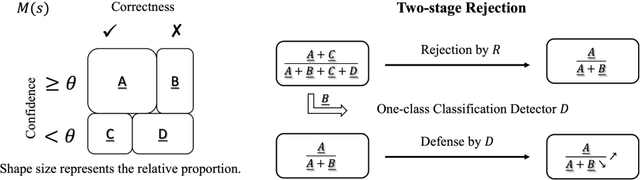
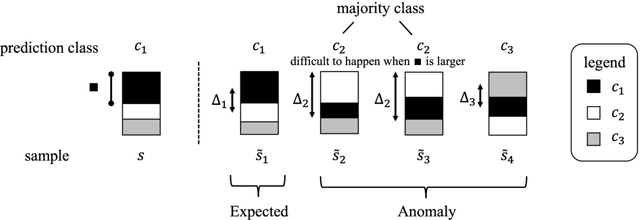
Sharpening deep learning models by training them with examples close to the decision boundary is a well-known best practice. Nonetheless, these models are still error-prone in producing predictions. In practice, the inference of the deep learning models in many application systems is guarded by a rejector, such as a confidence-based rejector, to filter out samples with insufficient prediction confidence. Such confidence-based rejectors cannot effectively guard against failing samples with high confidence. Existing test case prioritization techniques effectively distinguish confusing samples from confident samples to identify failing samples among the confusing ones, yet prioritizing the failing ones high among many confident ones is challenging. In this paper, we propose $A^3$Rank, a novel test case prioritization technique with augmentation alignment analysis, to address this problem. $A^3$Rank generates augmented versions of each test case and assesses the extent of the prediction result for the test case misaligned with these of the augmented versions and vice versa. Our experiment shows that $A^3$Rank can effectively rank failing samples escaping from the checking of confidence-based rejectors, which significantly outperforms the peer techniques by 163.63\% in the detection ratio of top-ranked samples. We also provide a framework to construct a detector devoted to augmenting these rejectors to defend these failing samples, and our detector can achieve a significantly higher defense success rate.
CrossCert: A Cross-Checking Detection Approach to Patch Robustness Certification for Deep Learning Models
May 13, 2024Patch robustness certification is an emerging kind of defense technique against adversarial patch attacks with provable guarantees. There are two research lines: certified recovery and certified detection. They aim to label malicious samples with provable guarantees correctly and issue warnings for malicious samples predicted to non-benign labels with provable guarantees, respectively. However, existing certified detection defenders suffer from protecting labels subject to manipulation, and existing certified recovery defenders cannot systematically warn samples about their labels. A certified defense that simultaneously offers robust labels and systematic warning protection against patch attacks is desirable. This paper proposes a novel certified defense technique called CrossCert. CrossCert formulates a novel approach by cross-checking two certified recovery defenders to provide unwavering certification and detection certification. Unwavering certification ensures that a certified sample, when subjected to a patched perturbation, will always be returned with a benign label without triggering any warnings with a provable guarantee. To our knowledge, CrossCert is the first certified detection technique to offer this guarantee. Our experiments show that, with a slightly lower performance than ViP and comparable performance with PatchCensor in terms of detection certification, CrossCert certifies a significant proportion of samples with the guarantee of unwavering certification.
A study on the impact of pre-trained model on Just-In-Time defect prediction
Sep 05, 2023
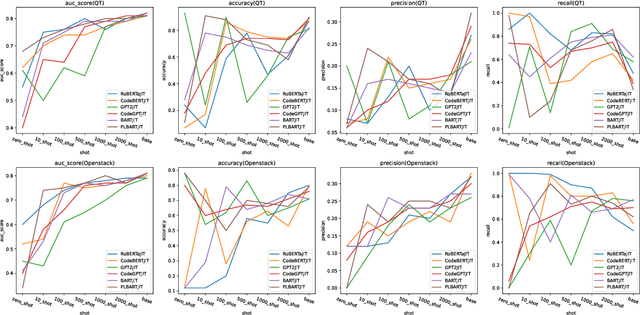
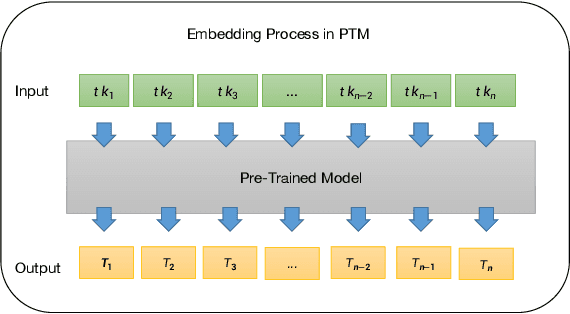
Previous researchers conducting Just-In-Time (JIT) defect prediction tasks have primarily focused on the performance of individual pre-trained models, without exploring the relationship between different pre-trained models as backbones. In this study, we build six models: RoBERTaJIT, CodeBERTJIT, BARTJIT, PLBARTJIT, GPT2JIT, and CodeGPTJIT, each with a distinct pre-trained model as its backbone. We systematically explore the differences and connections between these models. Specifically, we investigate the performance of the models when using Commit code and Commit message as inputs, as well as the relationship between training efficiency and model distribution among these six models. Additionally, we conduct an ablation experiment to explore the sensitivity of each model to inputs. Furthermore, we investigate how the models perform in zero-shot and few-shot scenarios. Our findings indicate that each model based on different backbones shows improvements, and when the backbone's pre-training model is similar, the training resources that need to be consumed are much more closer. We also observe that Commit code plays a significant role in defect detection, and different pre-trained models demonstrate better defect detection ability with a balanced dataset under few-shot scenarios. These results provide new insights for optimizing JIT defect prediction tasks using pre-trained models and highlight the factors that require more attention when constructing such models. Additionally, CodeGPTJIT and GPT2JIT achieved better performance than DeepJIT and CC2Vec on the two datasets respectively under 2000 training samples. These findings emphasize the effectiveness of transformer-based pre-trained models in JIT defect prediction tasks, especially in scenarios with limited training data.
A Majority Invariant Approach to Patch Robustness Certification for Deep Learning Models
Aug 01, 2023Patch robustness certification ensures no patch within a given bound on a sample can manipulate a deep learning model to predict a different label. However, existing techniques cannot certify samples that cannot meet their strict bars at the classifier or patch region levels. This paper proposes MajorCert. MajorCert firstly finds all possible label sets manipulatable by the same patch region on the same sample across the underlying classifiers, then enumerates their combinations element-wise, and finally checks whether the majority invariant of all these combinations is intact to certify samples.