 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Gait Signature of Frailty: Transfer Learning based Deep Gait Models for Scalable Frailty Assessment
Mar 25, 2026Frailty is a condition in aging medicine characterized by diminished physiological reserve and increased vulnerability to stressors. However, frailty assessment remains subjective, heterogeneous, and difficult to scale in clinical practice. Gait is a sensitive marker of biological aging, capturing multisystem decline before overt disability. Yet the application of modern computer vision to gait-based frailty assessment has been limited by small, imbalanced datasets and a lack of clinically representative benchmarks. In this work, we introduce a publicly available silhouette-based frailty gait dataset collected in a clinically realistic setting, spanning the full frailty spectrum and including older adults who use walking aids. Using this dataset, we evaluate how pretrained gait recognition models can be adapted for frailty classification under limited data conditions. We study both convolutional and hybrid attention-based architectures and show that predictive performance depends primarily on how pretrained representations are transferred rather than architectural complexity alone. Across models, selectively freezing low-level gait representations while allowing higher-level features to adapt yields more stable and generalizable performance than either full fine-tuning or rigid freezing. Conservative handling of class imbalance further improves training stability, and combining complementary learning objectives enhances discrimination between clinically adjacent frailty states. Interpretability analyses reveal consistent model attention to lower-limb and pelvic regions, aligning with established biomechanical correlates of frailty. Together, these findings establish gait-based representation learning as a scalable, non-invasive, and interpretable framework for frailty assessment and support the integration of modern biometric modeling approaches into aging research and clinical practice.
InstantHDR: Single-forward Gaussian Splatting for High Dynamic Range 3D Reconstruction
Mar 11, 2026High dynamic range (HDR) novel view synthesis (NVS) aims to reconstruct HDR scenes from multi-exposure low dynamic range (LDR) images. Existing HDR pipelines heavily rely on known camera poses, well-initialized dense point clouds, and time-consuming per-scene optimization. Current feed-forward alternatives overlook the HDR problem by assuming exposure-invariant appearance. To bridge this gap, we propose InstantHDR, a feed-forward network that reconstructs 3D HDR scenes from uncalibrated multi-exposure LDR collections in a single forward pass. Specifically, we design a geometry-guided appearance modeling for multi-exposure fusion, and a meta-network for generalizable scene-specific tone mapping. Due to the lack of HDR scene data, we build a pre-training dataset, called HDR-Pretrain, for generalizable feed-forward HDR models, featuring 168 Blender-rendered scenes, diverse lighting types, and multiple camera response functions. Comprehensive experiments show that our InstantHDR delivers comparable synthesis performance to the state-of-the-art optimization-based HDR methods while enjoying $\sim700\times$ and $\sim20\times$ reconstruction speed improvement with our single-forward and post-optimization settings. All code, models, and datasets will be released after the review process.
DTBench: A Synthetic Benchmark for Document-to-Table Extraction
Feb 17, 2026Document-to-table (Doc2Table) extraction derives structured tables from unstructured documents under a target schema, enabling reliable and verifiable SQL-based data analytics. Although large language models (LLMs) have shown promise in flexible information extraction, their ability to produce precisely structured tables remains insufficiently understood, particularly for indirect extraction that requires complex capabilities such as reasoning and conflict resolution. Existing benchmarks neither explicitly distinguish nor comprehensively cover the diverse capabilities required in Doc2Table extraction. We argue that a capability-aware benchmark is essential for systematic evaluation. However, constructing such benchmarks using human-annotated document-table pairs is costly, difficult to scale, and limited in capability coverage. To address this, we adopt a reverse Table2Doc paradigm and design a multi-agent synthesis workflow to generate documents from ground-truth tables. Based on this approach, we present DTBench, a synthetic benchmark that adopts a proposed two-level taxonomy of Doc2Table capabilities, covering 5 major categories and 13 subcategories. We evaluate several mainstream LLMs on DTBench, and demonstrate substantial performance gaps across models, as well as persistent challenges in reasoning, faithfulness, and conflict resolution. DTBench provides a comprehensive testbed for data generation and evaluation, facilitating future research on Doc2Table extraction. The benchmark is publicly available at https://github.com/ZJU-DAILY/DTBench.
Snoopy: Effective and Efficient Semantic Join Discovery via Proxy Columns
Feb 24, 2025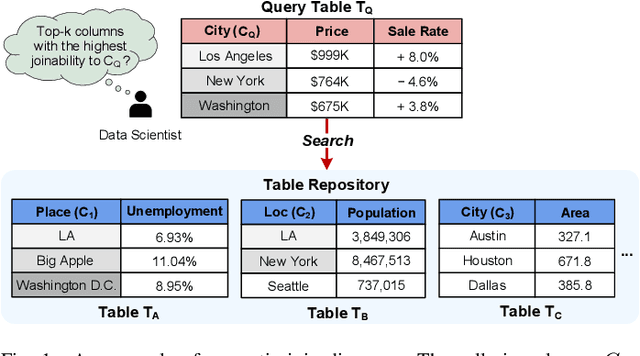
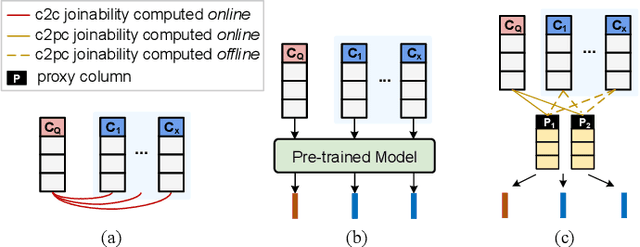
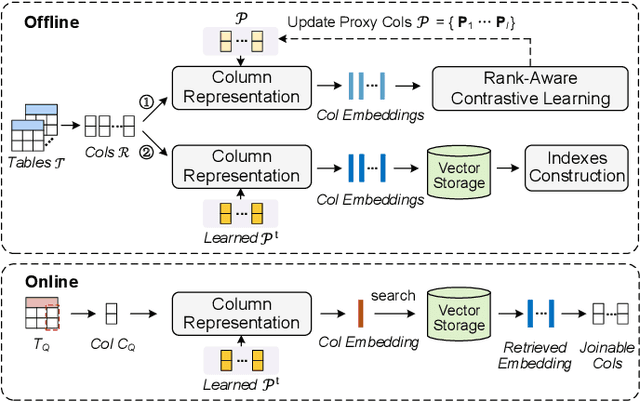

Semantic join discovery, which aims to find columns in a table repository with high semantic joinabilities to a query column, is crucial for dataset discovery. Existing methods can be divided into two categories: cell-level methods and column-level methods. However, neither of them ensures both effectiveness and efficiency simultaneously. Cell-level methods, which compute the joinability by counting cell matches between columns, enjoy ideal effectiveness but suffer poor efficiency. In contrast, column-level methods, which determine joinability only by computing the similarity of column embeddings, enjoy proper efficiency but suffer poor effectiveness due to the issues occurring in their column embeddings: (i) semantics-joinability-gap, (ii) size limit, and (iii) permutation sensitivity. To address these issues, this paper proposes to compute column embeddings via proxy columns; furthermore, a novel column-level semantic join discovery framework, Snoopy, is presented, leveraging proxy-column-based embeddings to bridge effectiveness and efficiency. Specifically, the proposed column embeddings are derived from the implicit column-to-proxy-column relationships, which are captured by the lightweight approximate-graph-matching-based column projection.To acquire good proxy columns for guiding the column projection, we introduce a rank-aware contrastive learning paradigm. Extensive experiments on four real-world datasets demonstrate that Snoopy outperforms SOTA column-level methods by 16% in Recall@25 and 10% in NDCG@25, and achieves superior efficiency--being at least 5 orders of magnitude faster than cell-level solutions, and 3.5x faster than existing column-level methods.
An Immersive Multi-Elevation Multi-Seasonal Dataset for 3D Reconstruction and Visualization
Dec 19, 2024



Significant progress has been made in photo-realistic scene reconstruction over recent years. Various disparate efforts have enabled capabilities such as multi-appearance or large-scale modeling; however, there lacks a welldesigned dataset that can evaluate the holistic progress of scene reconstruction. We introduce a collection of imagery of the Johns Hopkins Homewood Campus, acquired at different seasons, times of day, in multiple elevations, and across a large scale. We perform a multi-stage calibration process, which efficiently recover camera parameters from phone and drone cameras. This dataset can enable researchers to rigorously explore challenges in unconstrained settings, including effects of inconsistent illumination, reconstruction from large scale and from significantly different perspectives, etc.
SPARS3R: Semantic Prior Alignment and Regularization for Sparse 3D Reconstruction
Nov 15, 2024



Recent efforts in Gaussian-Splat-based Novel View Synthesis can achieve photorealistic rendering; however, such capability is limited in sparse-view scenarios due to sparse initialization and over-fitting floaters. Recent progress in depth estimation and alignment can provide dense point cloud with few views; however, the resulting pose accuracy is suboptimal. In this work, we present SPARS3R, which combines the advantages of accurate pose estimation from Structure-from-Motion and dense point cloud from depth estimation. To this end, SPARS3R first performs a Global Fusion Alignment process that maps a prior dense point cloud to a sparse point cloud from Structure-from-Motion based on triangulated correspondences. RANSAC is applied during this process to distinguish inliers and outliers. SPARS3R then performs a second, Semantic Outlier Alignment step, which extracts semantically coherent regions around the outliers and performs local alignment in these regions. Along with several improvements in the evaluation process, we demonstrate that SPARS3R can achieve photorealistic rendering with sparse images and significantly outperforms existing approaches.
TODO: Enhancing LLM Alignment with Ternary Preferences
Nov 02, 2024



Aligning large language models (LLMs) with human intent is critical for enhancing their performance across a variety of tasks. Standard alignment techniques, such as Direct Preference Optimization (DPO), often rely on the binary Bradley-Terry (BT) model, which can struggle to capture the complexities of human preferences -- particularly in the presence of noisy or inconsistent labels and frequent ties. To address these limitations, we introduce the Tie-rank Oriented Bradley-Terry model (TOBT), an extension of the BT model that explicitly incorporates ties, enabling more nuanced preference representation. Building on this, we propose Tie-rank Oriented Direct Preference Optimization (TODO), a novel alignment algorithm that leverages TOBT's ternary ranking system to improve preference alignment. In evaluations on Mistral-7B and Llama 3-8B models, TODO consistently outperforms DPO in modeling preferences across both in-distribution and out-of-distribution datasets. Additional assessments using MT Bench and benchmarks such as Piqa, ARC-c, and MMLU further demonstrate TODO's superior alignment performance. Notably, TODO also shows strong results in binary preference alignment, highlighting its versatility and potential for broader integration into LLM alignment. The implementation details can be found in https://github.com/XXares/TODO.
StimuVAR: Spatiotemporal Stimuli-aware Video Affective Reasoning with Multimodal Large Language Models
Aug 31, 2024Predicting and reasoning how a video would make a human feel is crucial for developing socially intelligent systems. Although Multimodal Large Language Models (MLLMs) have shown impressive video understanding capabilities, they tend to focus more on the semantic content of videos, often overlooking emotional stimuli. Hence, most existing MLLMs fall short in estimating viewers' emotional reactions and providing plausible explanations. To address this issue, we propose StimuVAR, a spatiotemporal Stimuli-aware framework for Video Affective Reasoning (VAR) with MLLMs. StimuVAR incorporates a two-level stimuli-aware mechanism: frame-level awareness and token-level awareness. Frame-level awareness involves sampling video frames with events that are most likely to evoke viewers' emotions. Token-level awareness performs tube selection in the token space to make the MLLM concentrate on emotion-triggered spatiotemporal regions. Furthermore, we create VAR instruction data to perform affective training, steering MLLMs' reasoning strengths towards emotional focus and thereby enhancing their affective reasoning ability. To thoroughly assess the effectiveness of VAR, we provide a comprehensive evaluation protocol with extensive metrics. StimuVAR is the first MLLM-based method for viewer-centered VAR. Experiments demonstrate its superiority in understanding viewers' emotional responses to videos and providing coherent and insightful explanations.
SCCA: Shifted Cross Chunk Attention for long contextual semantic expansion
Dec 12, 2023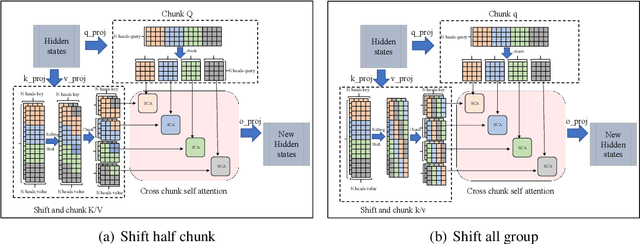

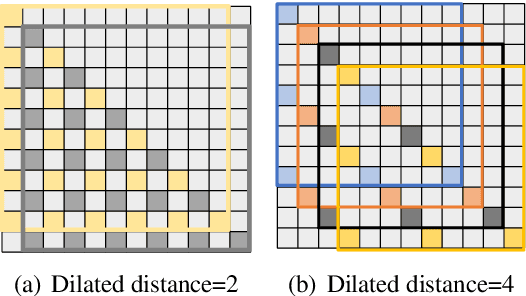
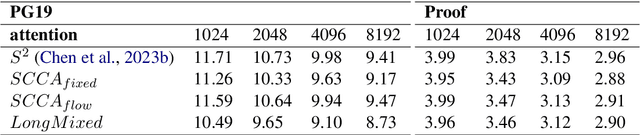
Sparse attention as a efficient method can significantly decrease the computation cost, but current sparse attention tend to rely on window self attention which block the global information flow. For this problem, we present Shifted Cross Chunk Attention (SCCA), using different KV shifting strategy to extend respective field in each attention layer. Except, we combine Dilated Attention(DA) and Dilated Neighborhood Attention(DNA) to present Shifted Dilated Attention(SDA). Both SCCA and SDA can accumulate attention results in multi head attention to obtain approximate respective field in full attention. In this paper, we conduct language modeling experiments using different pattern of SCCA and combination of SCCA and SDA. The proposed shifted cross chunk attention (SCCA) can effectively extend large language models (LLMs) to longer context combined with Positional interpolation(PI) and LoRA than current sparse attention. Notably, SCCA adopts LLaMA2 7B from 4k context to 8k in single V100. This attention pattern can provide a Plug-and-play fine-tuning method to extend model context while retaining their original architectures, and is compatible with most existing techniques.
GaitContour: Efficient Gait Recognition based on a Contour-Pose Representation
Nov 27, 2023Gait recognition holds the promise to robustly identify subjects based on walking patterns instead of appearance information. In recent years, this field has been dominated by learning methods based on two principal input representations: dense silhouette masks or sparse pose keypoints. In this work, we propose a novel, point-based Contour-Pose representation, which compactly expresses both body shape and body parts information. We further propose a local-to-global architecture, called GaitContour, to leverage this novel representation and efficiently compute subject embedding in two stages. The first stage consists of a local transformer that extracts features from five different body regions. The second stage then aggregates the regional features to estimate a global human gait representation. Such a design significantly reduces the complexity of the attention operation and improves efficiency and performance simultaneously. Through large scale experiments, GaitContour is shown to perform significantly better than previous point-based methods, while also being significantly more efficient than silhouette-based methods. On challenging datasets with significant distractors, GaitContour can even outperform silhouette-based methods.