 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient MAP Estimation of LLM Judgment Performance with Prior Transfer
Apr 17, 2025



LLM ensembles are widely used for LLM judges. However, how to estimate their accuracy, especially in an efficient way, is unknown. In this paper, we present a principled maximum a posteriori (MAP) framework for an economical and precise estimation of the performance of LLM ensemble judgment. We first propose a mixture of Beta-Binomial distributions to model the judgment distribution, revising from the vanilla Binomial distribution. Next, we introduce a conformal prediction-driven approach that enables adaptive stopping during iterative sampling to balance accuracy with efficiency. Furthermore, we design a prior transfer mechanism that utilizes learned distributions on open-source datasets to improve estimation on a target dataset when only scarce annotations are available. Finally, we present BetaConform, a framework that integrates our distribution assumption, adaptive stopping, and the prior transfer mechanism to deliver a theoretically guaranteed distribution estimation of LLM ensemble judgment with minimum labeled samples. BetaConform is also validated empirically. For instance, with only 10 samples from the TruthfulQA dataset, for a Llama ensembled judge, BetaConform gauges its performance with error margin as small as 3.37%.
Filter Images First, Generate Instructions Later: Pre-Instruction Data Selection for Visual Instruction Tuning
Mar 10, 2025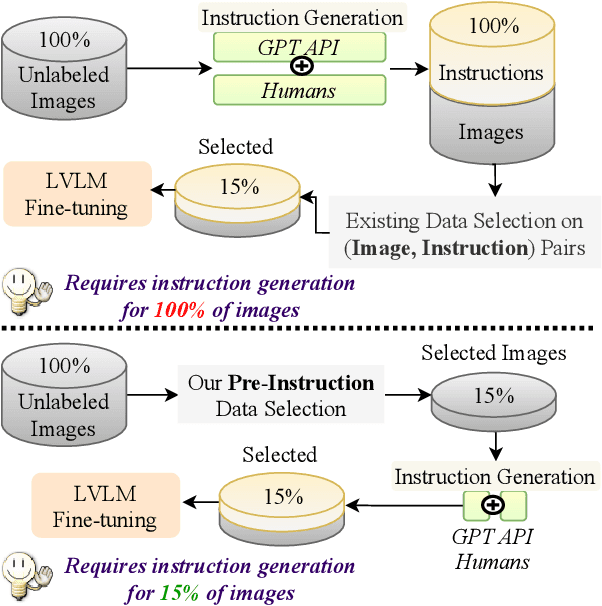



Visual instruction tuning (VIT) for large vision-language models (LVLMs) requires training on expansive datasets of image-instruction pairs, which can be costly. Recent efforts in VIT data selection aim to select a small subset of high-quality image-instruction pairs, reducing VIT runtime while maintaining performance comparable to full-scale training. However, a major challenge often overlooked is that generating instructions from unlabeled images for VIT is highly expensive. Most existing VIT datasets rely heavily on human annotations or paid services like the GPT API, which limits users with constrained resources from creating VIT datasets for custom applications. To address this, we introduce Pre-Instruction Data Selection (PreSel), a more practical data selection paradigm that directly selects the most beneficial unlabeled images and generates instructions only for the selected images. PreSel first estimates the relative importance of each vision task within VIT datasets to derive task-wise sampling budgets. It then clusters image features within each task, selecting the most representative images with the budget. This approach reduces computational overhead for both instruction generation during VIT data formation and LVLM fine-tuning. By generating instructions for only 15% of the images, PreSel achieves performance comparable to full-data VIT on the LLaVA-1.5 and Vision-Flan datasets. The link to our project page: https://bardisafa.github.io/PreSel
StimuVAR: Spatiotemporal Stimuli-aware Video Affective Reasoning with Multimodal Large Language Models
Aug 31, 2024Predicting and reasoning how a video would make a human feel is crucial for developing socially intelligent systems. Although Multimodal Large Language Models (MLLMs) have shown impressive video understanding capabilities, they tend to focus more on the semantic content of videos, often overlooking emotional stimuli. Hence, most existing MLLMs fall short in estimating viewers' emotional reactions and providing plausible explanations. To address this issue, we propose StimuVAR, a spatiotemporal Stimuli-aware framework for Video Affective Reasoning (VAR) with MLLMs. StimuVAR incorporates a two-level stimuli-aware mechanism: frame-level awareness and token-level awareness. Frame-level awareness involves sampling video frames with events that are most likely to evoke viewers' emotions. Token-level awareness performs tube selection in the token space to make the MLLM concentrate on emotion-triggered spatiotemporal regions. Furthermore, we create VAR instruction data to perform affective training, steering MLLMs' reasoning strengths towards emotional focus and thereby enhancing their affective reasoning ability. To thoroughly assess the effectiveness of VAR, we provide a comprehensive evaluation protocol with extensive metrics. StimuVAR is the first MLLM-based method for viewer-centered VAR. Experiments demonstrate its superiority in understanding viewers' emotional responses to videos and providing coherent and insightful explanations.
M2D2M: Multi-Motion Generation from Text with Discrete Diffusion Models
Jul 19, 2024



We introduce the Multi-Motion Discrete Diffusion Models (M2D2M), a novel approach for human motion generation from textual descriptions of multiple actions, utilizing the strengths of discrete diffusion models. This approach adeptly addresses the challenge of generating multi-motion sequences, ensuring seamless transitions of motions and coherence across a series of actions. The strength of M2D2M lies in its dynamic transition probability within the discrete diffusion model, which adapts transition probabilities based on the proximity between motion tokens, encouraging mixing between different modes. Complemented by a two-phase sampling strategy that includes independent and joint denoising steps, M2D2M effectively generates long-term, smooth, and contextually coherent human motion sequences, utilizing a model trained for single-motion generation. Extensive experiments demonstrate that M2D2M surpasses current state-of-the-art benchmarks for motion generation from text descriptions, showcasing its efficacy in interpreting language semantics and generating dynamic, realistic motions.