 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Occupancy Prediction with Low-Resolution Queries via Prototype-aware View Transformation
Mar 19, 2025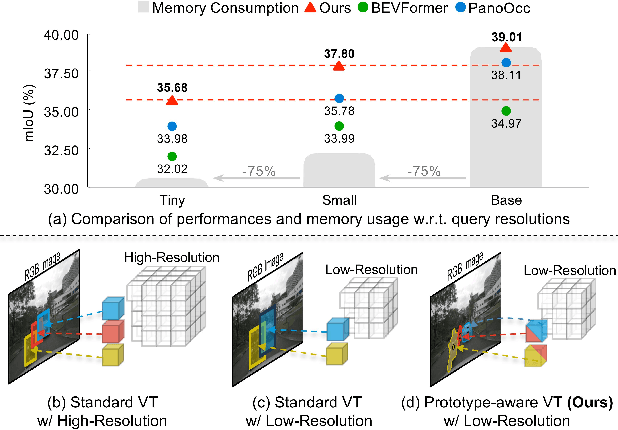
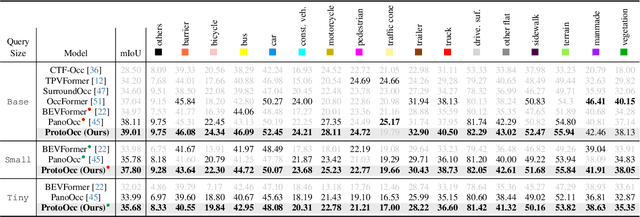
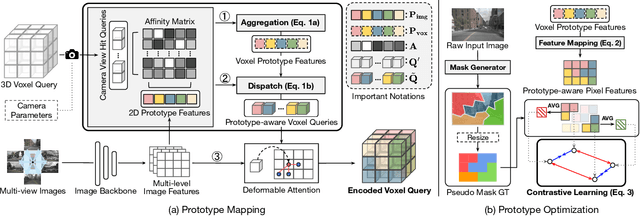
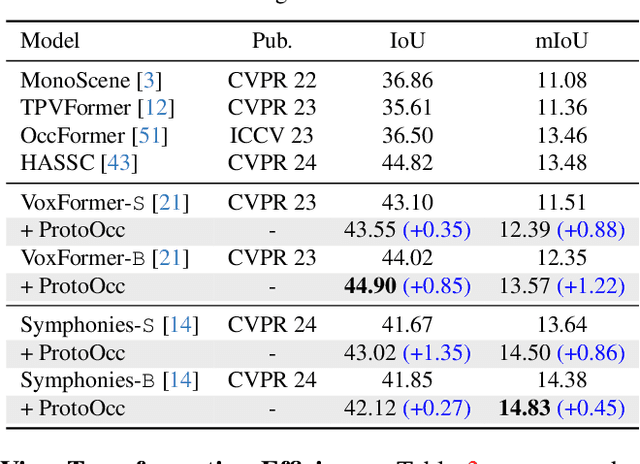
The resolution of voxel queries significantly influences the quality of view transformation in camera-based 3D occupancy prediction. However, computational constraints and the practical necessity for real-time deployment require smaller query resolutions, which inevitably leads to an information loss. Therefore, it is essential to encode and preserve rich visual details within limited query sizes while ensuring a comprehensive representation of 3D occupancy. To this end, we introduce ProtoOcc, a novel occupancy network that leverages prototypes of clustered image segments in view transformation to enhance low-resolution context. In particular, the mapping of 2D prototypes onto 3D voxel queries encodes high-level visual geometries and complements the loss of spatial information from reduced query resolutions. Additionally, we design a multi-perspective decoding strategy to efficiently disentangle the densely compressed visual cues into a high-dimensional 3D occupancy scene. Experimental results on both Occ3D and SemanticKITTI benchmarks demonstrate the effectiveness of the proposed method, showing clear improvements over the baselines. More importantly, ProtoOcc achieves competitive performance against the baselines even with 75\% reduced voxel resolution.
M2D2M: Multi-Motion Generation from Text with Discrete Diffusion Models
Jul 19, 2024



We introduce the Multi-Motion Discrete Diffusion Models (M2D2M), a novel approach for human motion generation from textual descriptions of multiple actions, utilizing the strengths of discrete diffusion models. This approach adeptly addresses the challenge of generating multi-motion sequences, ensuring seamless transitions of motions and coherence across a series of actions. The strength of M2D2M lies in its dynamic transition probability within the discrete diffusion model, which adapts transition probabilities based on the proximity between motion tokens, encouraging mixing between different modes. Complemented by a two-phase sampling strategy that includes independent and joint denoising steps, M2D2M effectively generates long-term, smooth, and contextually coherent human motion sequences, utilizing a model trained for single-motion generation. Extensive experiments demonstrate that M2D2M surpasses current state-of-the-art benchmarks for motion generation from text descriptions, showcasing its efficacy in interpreting language semantics and generating dynamic, realistic motions.
VisionTrap: Vision-Augmented Trajectory Prediction Guided by Textual Descriptions
Jul 17, 2024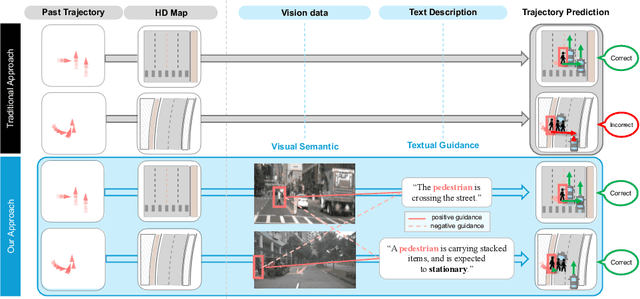
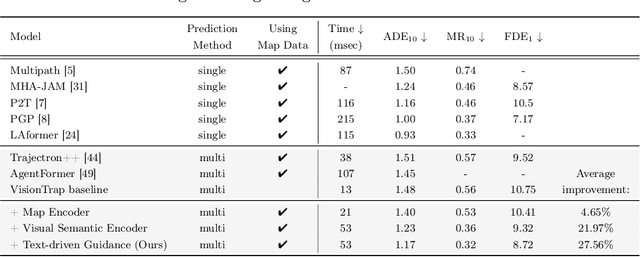

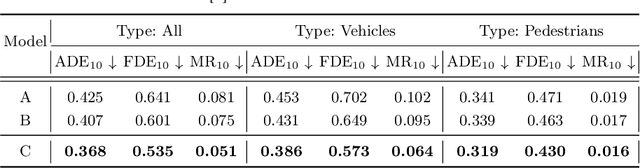
Predicting future trajectories for other road agents is an essential task for autonomous vehicles. Established trajectory prediction methods primarily use agent tracks generated by a detection and tracking system and HD map as inputs. In this work, we propose a novel method that also incorporates visual input from surround-view cameras, allowing the model to utilize visual cues such as human gazes and gestures, road conditions, vehicle turn signals, etc, which are typically hidden from the model in prior methods. Furthermore, we use textual descriptions generated by a Vision-Language Model (VLM) and refined by a Large Language Model (LLM) as supervision during training to guide the model on what to learn from the input data. Despite using these extra inputs, our method achieves a latency of 53 ms, making it feasible for real-time processing, which is significantly faster than that of previous single-agent prediction methods with similar performance. Our experiments show that both the visual inputs and the textual descriptions contribute to improvements in trajectory prediction performance, and our qualitative analysis highlights how the model is able to exploit these additional inputs. Lastly, in this work we create and release the nuScenes-Text dataset, which augments the established nuScenes dataset with rich textual annotations for every scene, demonstrating the positive impact of utilizing VLM on trajectory prediction. Our project page is at https://moonseokha.github.io/VisionTrap/
InfoGCN++: Learning Representation by Predicting the Future for Online Human Skeleton-based Action Recognition
Oct 16, 2023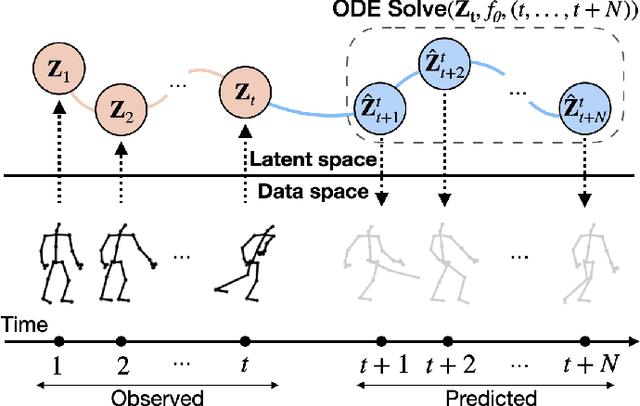
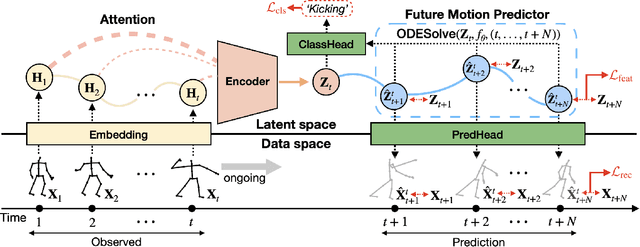
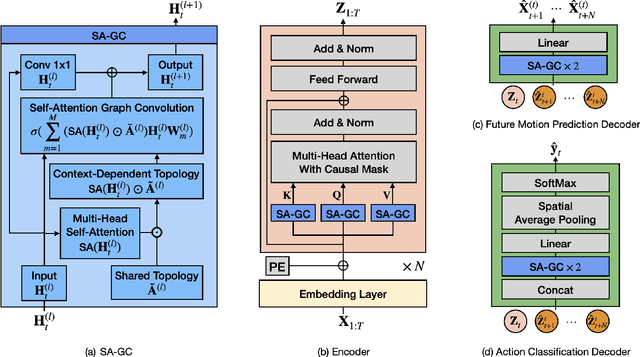
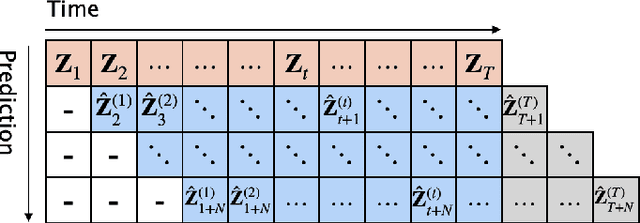
Skeleton-based action recognition has made significant advancements recently, with models like InfoGCN showcasing remarkable accuracy. However, these models exhibit a key limitation: they necessitate complete action observation prior to classification, which constrains their applicability in real-time situations such as surveillance and robotic systems. To overcome this barrier, we introduce InfoGCN++, an innovative extension of InfoGCN, explicitly developed for online skeleton-based action recognition. InfoGCN++ augments the abilities of the original InfoGCN model by allowing real-time categorization of action types, independent of the observation sequence's length. It transcends conventional approaches by learning from current and anticipated future movements, thereby creating a more thorough representation of the entire sequence. Our approach to prediction is managed as an extrapolation issue, grounded on observed actions. To enable this, InfoGCN++ incorporates Neural Ordinary Differential Equations, a concept that lets it effectively model the continuous evolution of hidden states. Following rigorous evaluations on three skeleton-based action recognition benchmarks, InfoGCN++ demonstrates exceptional performance in online action recognition. It consistently equals or exceeds existing techniques, highlighting its significant potential to reshape the landscape of real-time action recognition applications. Consequently, this work represents a major leap forward from InfoGCN, pushing the limits of what's possible in online, skeleton-based action recognition. The code for InfoGCN++ is publicly available at https://github.com/stnoah1/infogcn2 for further exploration and validation.
Uncovering the Missing Pattern: Unified Framework Towards Trajectory Imputation and Prediction
Mar 28, 2023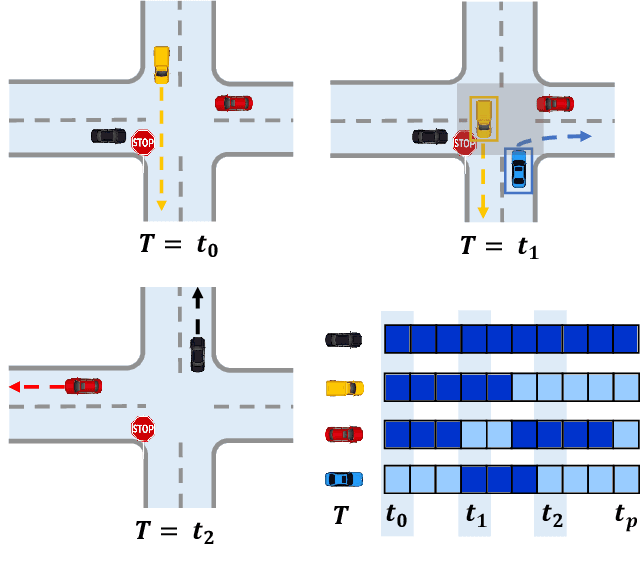
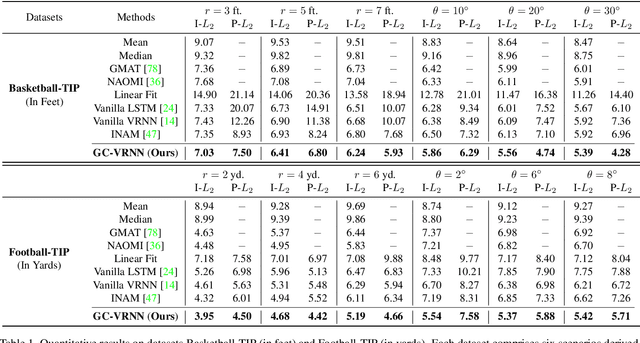

Trajectory prediction is a crucial undertaking in understanding entity movement or human behavior from observed sequences. However, current methods often assume that the observed sequences are complete while ignoring the potential for missing values caused by object occlusion, scope limitation, sensor failure, etc. This limitation inevitably hinders the accuracy of trajectory prediction. To address this issue, our paper presents a unified framework, the Graph-based Conditional Variational Recurrent Neural Network (GC-VRNN), which can perform trajectory imputation and prediction simultaneously. Specifically, we introduce a novel Multi-Space Graph Neural Network (MS-GNN) that can extract spatial features from incomplete observations and leverage missing patterns. Additionally, we employ a Conditional VRNN with a specifically designed Temporal Decay (TD) module to capture temporal dependencies and temporal missing patterns in incomplete trajectories. The inclusion of the TD module allows for valuable information to be conveyed through the temporal flow. We also curate and benchmark three practical datasets for the joint problem of trajectory imputation and prediction. Extensive experiments verify the exceptional performance of our proposed method. As far as we know, this is the first work to address the lack of benchmarks and techniques for trajectory imputation and prediction in a unified manner.