 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoSE: Skill-by-Skill Mixture-of-Expert Learning for Autonomous Driving
Jul 10, 2025
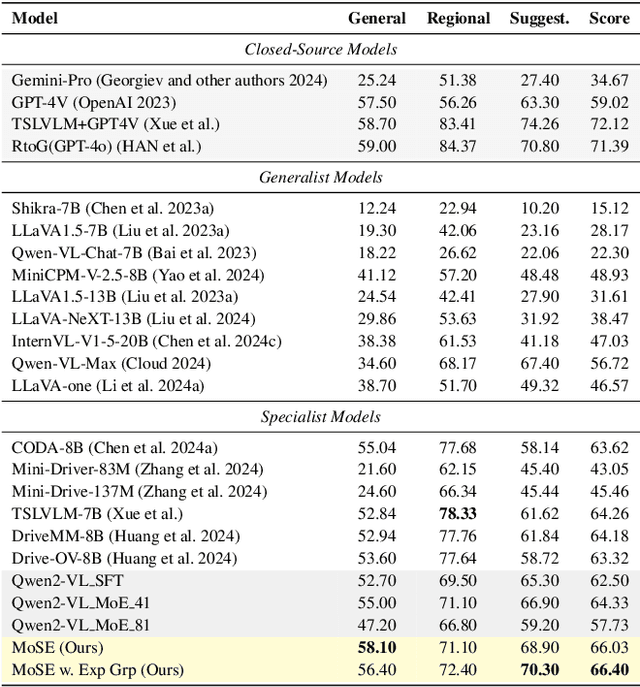
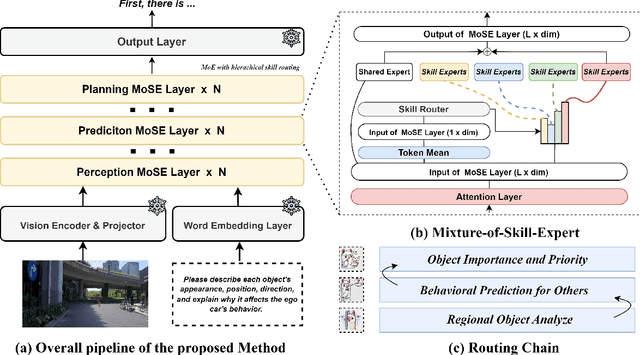
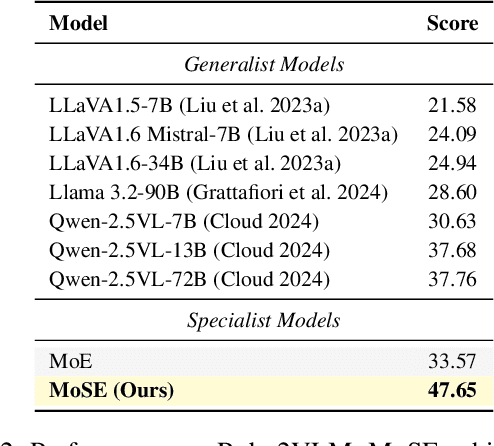
Recent studies show large language models (LLMs) and vision language models (VLMs) trained using web-scale data can empower end-to-end autonomous driving systems for a better generalization and interpretation. Specifically, by dynamically routing inputs to specialized subsets of parameters, the Mixture-of-Experts (MoE) technique enables general LLMs or VLMs to achieve substantial performance improvements while maintaining computational efficiency. However, general MoE models usually demands extensive training data and complex optimization. In this work, inspired by the learning process of human drivers, we propose a skill-oriented MoE, called MoSE, which mimics human drivers' learning process and reasoning process, skill-by-skill and step-by-step. We propose a skill-oriented routing mechanism that begins with defining and annotating specific skills, enabling experts to identify the necessary driving competencies for various scenarios and reasoning tasks, thereby facilitating skill-by-skill learning. Further align the driving process to multi-step planning in human reasoning and end-to-end driving models, we build a hierarchical skill dataset and pretrain the router to encourage the model to think step-by-step. Unlike multi-round dialogs, MoSE integrates valuable auxiliary tasks (e.g.\ description, reasoning, planning) in one single forward process without introducing any extra computational cost. With less than 3B sparsely activated parameters, our model outperforms several 8B+ parameters on CODA AD corner case reasoning task. Compared to existing methods based on open-source models and data, our approach achieves state-of-the-art performance with significantly reduced activated model size (at least by $62.5\%$) with a single-turn conversation.
3D Occupancy Prediction with Low-Resolution Queries via Prototype-aware View Transformation
Mar 19, 2025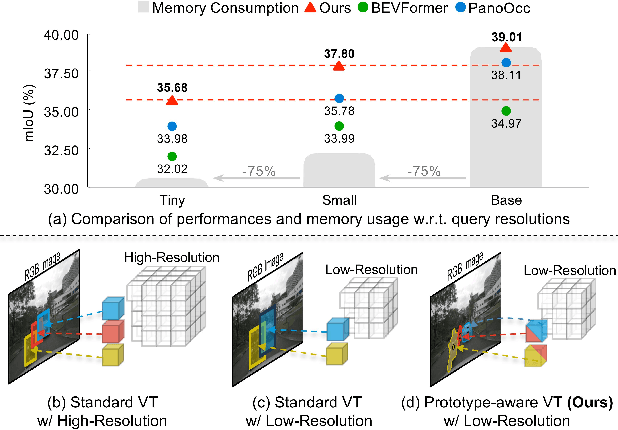
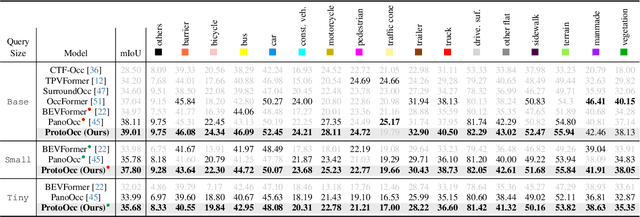
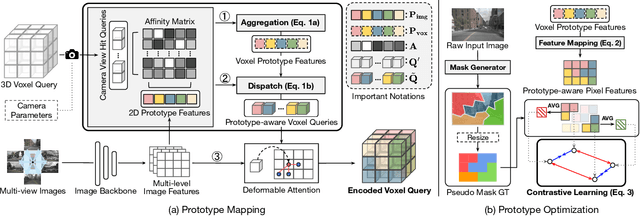
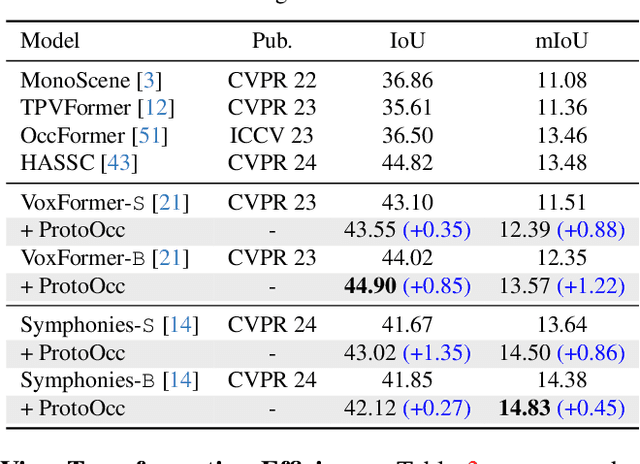
The resolution of voxel queries significantly influences the quality of view transformation in camera-based 3D occupancy prediction. However, computational constraints and the practical necessity for real-time deployment require smaller query resolutions, which inevitably leads to an information loss. Therefore, it is essential to encode and preserve rich visual details within limited query sizes while ensuring a comprehensive representation of 3D occupancy. To this end, we introduce ProtoOcc, a novel occupancy network that leverages prototypes of clustered image segments in view transformation to enhance low-resolution context. In particular, the mapping of 2D prototypes onto 3D voxel queries encodes high-level visual geometries and complements the loss of spatial information from reduced query resolutions. Additionally, we design a multi-perspective decoding strategy to efficiently disentangle the densely compressed visual cues into a high-dimensional 3D occupancy scene. Experimental results on both Occ3D and SemanticKITTI benchmarks demonstrate the effectiveness of the proposed method, showing clear improvements over the baselines. More importantly, ProtoOcc achieves competitive performance against the baselines even with 75\% reduced voxel resolution.
Unveiling the Hidden: Online Vectorized HD Map Construction with Clip-Level Token Interaction and Propagation
Nov 17, 2024Predicting and constructing road geometric information (e.g., lane lines, road markers) is a crucial task for safe autonomous driving, while such static map elements can be repeatedly occluded by various dynamic objects on the road. Recent studies have shown significantly improved vectorized high-definition (HD) map construction performance, but there has been insufficient investigation of temporal information across adjacent input frames (i.e., clips), which may lead to inconsistent and suboptimal prediction results. To tackle this, we introduce a novel paradigm of clip-level vectorized HD map construction, MapUnveiler, which explicitly unveils the occluded map elements within a clip input by relating dense image representations with efficient clip tokens. Additionally, MapUnveiler associates inter-clip information through clip token propagation, effectively utilizing long-term temporal map information. MapUnveiler runs efficiently with the proposed clip-level pipeline by avoiding redundant computation with temporal stride while building a global map relationship. Our extensive experiments demonstrate that MapUnveiler achieves state-of-the-art performance on both the nuScenes and Argoverse2 benchmark datasets. We also showcase that MapUnveiler significantly outperforms state-of-the-art approaches in a challenging setting, achieving +10.7% mAP improvement in heavily occluded driving road scenes. The project page can be found at https://mapunveiler.github.io.
Unified Domain Generalization and Adaptation for Multi-View 3D Object Detection
Oct 29, 2024



Recent advances in 3D object detection leveraging multi-view cameras have demonstrated their practical and economical value in various challenging vision tasks. However, typical supervised learning approaches face challenges in achieving satisfactory adaptation toward unseen and unlabeled target datasets (\ie, direct transfer) due to the inevitable geometric misalignment between the source and target domains. In practice, we also encounter constraints on resources for training models and collecting annotations for the successful deployment of 3D object detectors. In this paper, we propose Unified Domain Generalization and Adaptation (UDGA), a practical solution to mitigate those drawbacks. We first propose Multi-view Overlap Depth Constraint that leverages the strong association between multi-view, significantly alleviating geometric gaps due to perspective view changes. Then, we present a Label-Efficient Domain Adaptation approach to handle unfamiliar targets with significantly fewer amounts of labels (\ie, 1$\%$ and 5$\%)$, while preserving well-defined source knowledge for training efficiency. Overall, UDGA framework enables stable detection performance in both source and target domains, effectively bridging inevitable domain gaps, while demanding fewer annotations. We demonstrate the robustness of UDGA with large-scale benchmarks: nuScenes, Lyft, and Waymo, where our framework outperforms the current state-of-the-art methods.
CMDA: Cross-Modal and Domain Adversarial Adaptation for LiDAR-Based 3D Object Detection
Mar 07, 2024Recent LiDAR-based 3D Object Detection (3DOD) methods show promising results, but they often do not generalize well to target domains outside the source (or training) data distribution. To reduce such domain gaps and thus to make 3DOD models more generalizable, we introduce a novel unsupervised domain adaptation (UDA) method, called CMDA, which (i) leverages visual semantic cues from an image modality (i.e., camera images) as an effective semantic bridge to close the domain gap in the cross-modal Bird's Eye View (BEV) representations. Further, (ii) we also introduce a self-training-based learning strategy, wherein a model is adversarially trained to generate domain-invariant features, which disrupt the discrimination of whether a feature instance comes from a source or an unseen target domain. Overall, our CMDA framework guides the 3DOD model to generate highly informative and domain-adaptive features for novel data distributions. In our extensive experiments with large-scale benchmarks, such as nuScenes, Waymo, and KITTI, those mentioned above provide significant performance gains for UDA tasks, achieving state-of-the-art performance.