 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViewSplat: View-Adaptive Dynamic Gaussian Splatting for Feed-Forward Synthesis
Mar 26, 2026We present ViewSplat, a view-adaptive 3D Gaussian splatting network for novel view synthesis from unposed images. While recent feed-forward 3D Gaussian splatting has significantly accelerated 3D scene reconstruction by bypassing per-scene optimization, a fundamental fidelity gap remains. We attribute this bottleneck to the limited capacity of single-step feed-forward networks to regress static Gaussian primitives that satisfy all viewpoints. To address this limitation, we shift the paradigm from static primitive regression to view-adaptive dynamic splatting. Instead of a rigid Gaussian representation, our pipeline learns a view-adaptable latent representation. Specifically, ViewSplat initially predicts base Gaussian primitives alongside the weights of dynamic MLPs. During rendering, these MLPs take target view coordinates as input and predict view-dependent residual updates for each Gaussian attribute (i.e., 3D position, scale, rotation, opacity, and color). This mechanism, which we term view-adaptive dynamic splatting, allows each primitive to rectify initial estimation errors, effectively capturing high-fidelity appearances. Extensive experiments demonstrate that ViewSplat achieves state-of-the-art fidelity while maintaining fast inference (17 FPS) and real-time rendering (154 FPS).
Environmental Change Detection: Toward a Practical Task of Scene Change Detection
Jun 13, 2025Humans do not memorize everything. Thus, humans recognize scene changes by exploring the past images. However, available past (i.e., reference) images typically represent nearby viewpoints of the present (i.e., query) scene, rather than the identical view. Despite this practical limitation, conventional Scene Change Detection (SCD) has been formalized under an idealized setting in which reference images with matching viewpoints are available for every query. In this paper, we push this problem toward a practical task and introduce Environmental Change Detection (ECD). A key aspect of ECD is to avoid unrealistically aligned query-reference pairs and rely solely on environmental cues. Inspired by real-world practices, we provide these cues through a large-scale database of uncurated images. To address this new task, we propose a novel framework that jointly understands spatial environments and detects changes. The main idea is that matching at the same spatial locations between a query and a reference may lead to a suboptimal solution due to viewpoint misalignment and limited field-of-view (FOV) coverage. We deal with this limitation by leveraging multiple reference candidates and aggregating semantically rich representations for change detection. We evaluate our framework on three standard benchmark sets reconstructed for ECD, and significantly outperform a naive combination of state-of-the-art methods while achieving comparable performance to the oracle setting. The code will be released upon acceptance.
Unveiling the Hidden: Online Vectorized HD Map Construction with Clip-Level Token Interaction and Propagation
Nov 17, 2024Predicting and constructing road geometric information (e.g., lane lines, road markers) is a crucial task for safe autonomous driving, while such static map elements can be repeatedly occluded by various dynamic objects on the road. Recent studies have shown significantly improved vectorized high-definition (HD) map construction performance, but there has been insufficient investigation of temporal information across adjacent input frames (i.e., clips), which may lead to inconsistent and suboptimal prediction results. To tackle this, we introduce a novel paradigm of clip-level vectorized HD map construction, MapUnveiler, which explicitly unveils the occluded map elements within a clip input by relating dense image representations with efficient clip tokens. Additionally, MapUnveiler associates inter-clip information through clip token propagation, effectively utilizing long-term temporal map information. MapUnveiler runs efficiently with the proposed clip-level pipeline by avoiding redundant computation with temporal stride while building a global map relationship. Our extensive experiments demonstrate that MapUnveiler achieves state-of-the-art performance on both the nuScenes and Argoverse2 benchmark datasets. We also showcase that MapUnveiler significantly outperforms state-of-the-art approaches in a challenging setting, achieving +10.7% mAP improvement in heavily occluded driving road scenes. The project page can be found at https://mapunveiler.github.io.
SHUNIT: Style Harmonization for Unpaired Image-to-Image Translation
Jan 11, 2023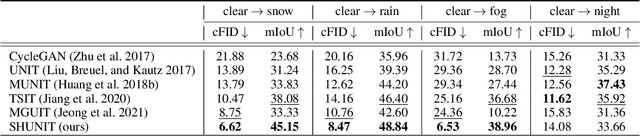
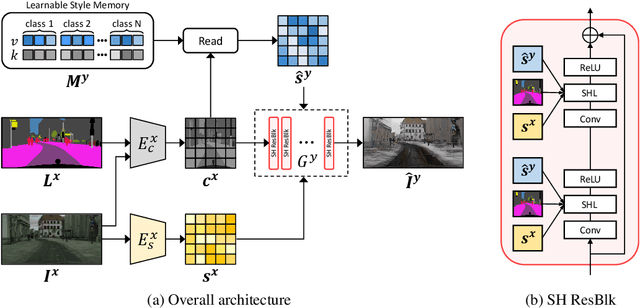
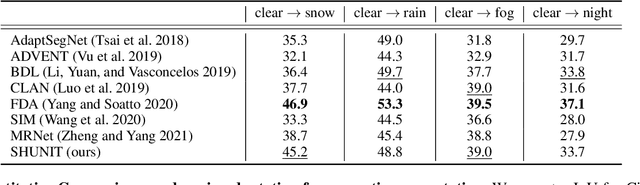
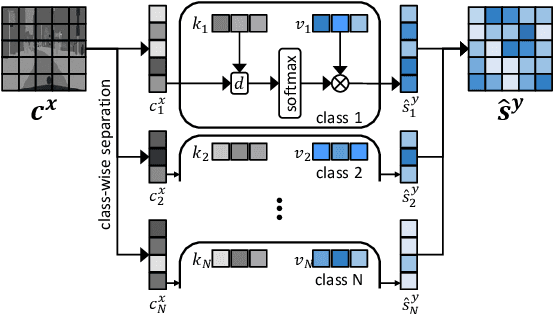
We propose a novel solution for unpaired image-to-image (I2I) translation. To translate complex images with a wide range of objects to a different domain, recent approaches often use the object annotations to perform per-class source-to-target style mapping. However, there remains a point for us to exploit in the I2I. An object in each class consists of multiple components, and all the sub-object components have different characteristics. For example, a car in CAR class consists of a car body, tires, windows and head and tail lamps, etc., and they should be handled separately for realistic I2I translation. The simplest solution to the problem will be to use more detailed annotations with sub-object component annotations than the simple object annotations, but it is not possible. The key idea of this paper is to bypass the sub-object component annotations by leveraging the original style of the input image because the original style will include the information about the characteristics of the sub-object components. Specifically, for each pixel, we use not only the per-class style gap between the source and target domains but also the pixel's original style to determine the target style of a pixel. To this end, we present Style Harmonization for unpaired I2I translation (SHUNIT). Our SHUNIT generates a new style by harmonizing the target domain style retrieved from a class memory and an original source image style. Instead of direct source-to-target style mapping, we aim for source and target styles harmonization. We validate our method with extensive experiments and achieve state-of-the-art performance on the latest benchmark sets. The source code is available online: https://github.com/bluejangbaljang/SHUNIT.
Domain Adaptive Video Semantic Segmentation via Cross-Domain Moving Object Mixing
Nov 04, 2022The network trained for domain adaptation is prone to bias toward the easy-to-transfer classes. Since the ground truth label on the target domain is unavailable during training, the bias problem leads to skewed predictions, forgetting to predict hard-to-transfer classes. To address this problem, we propose Cross-domain Moving Object Mixing (CMOM) that cuts several objects, including hard-to-transfer classes, in the source domain video clip and pastes them into the target domain video clip. Unlike image-level domain adaptation, the temporal context should be maintained to mix moving objects in two different videos. Therefore, we design CMOM to mix with consecutive video frames, so that unrealistic movements are not occurring. We additionally propose Feature Alignment with Temporal Context (FATC) to enhance target domain feature discriminability. FATC exploits the robust source domain features, which are trained with ground truth labels, to learn discriminative target domain features in an unsupervised manner by filtering unreliable predictions with temporal consensus. We demonstrate the effectiveness of the proposed approaches through extensive experiments. In particular, our model reaches mIoU of 53.81% on VIPER to Cityscapes-Seq benchmark and mIoU of 56.31% on SYNTHIA-Seq to Cityscapes-Seq benchmark, surpassing the state-of-the-art methods by large margins.
One-Trimap Video Matting
Jul 27, 2022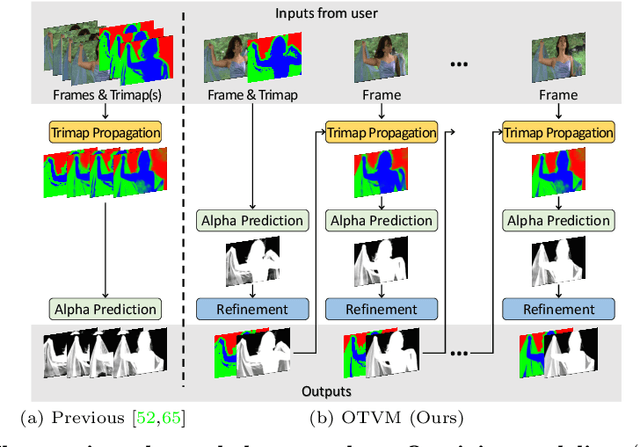
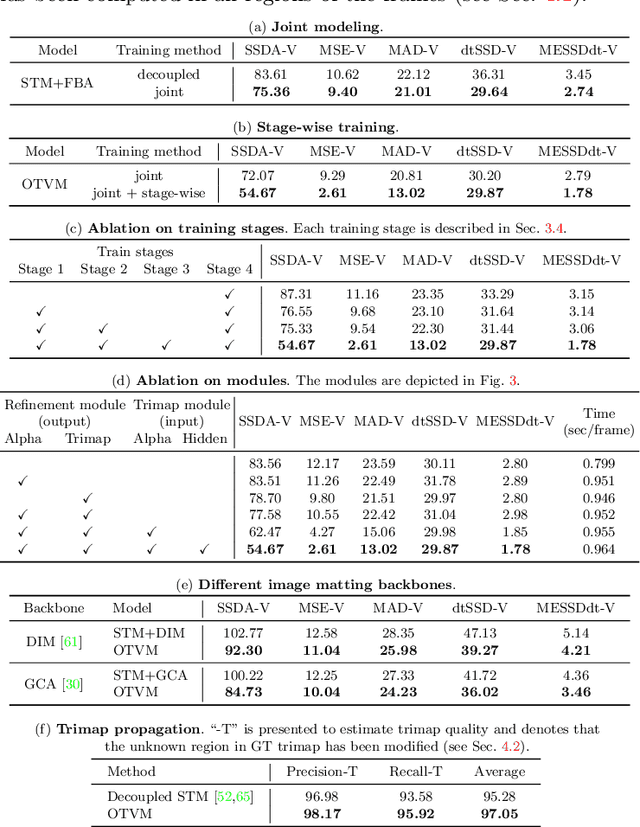
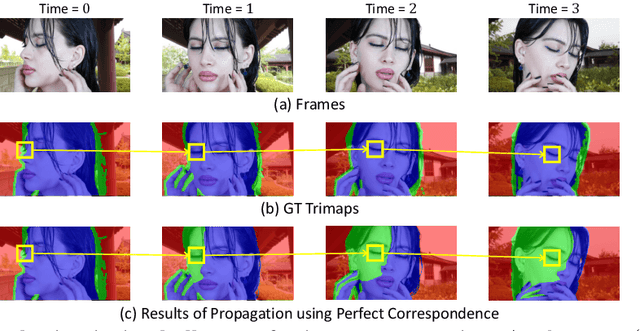
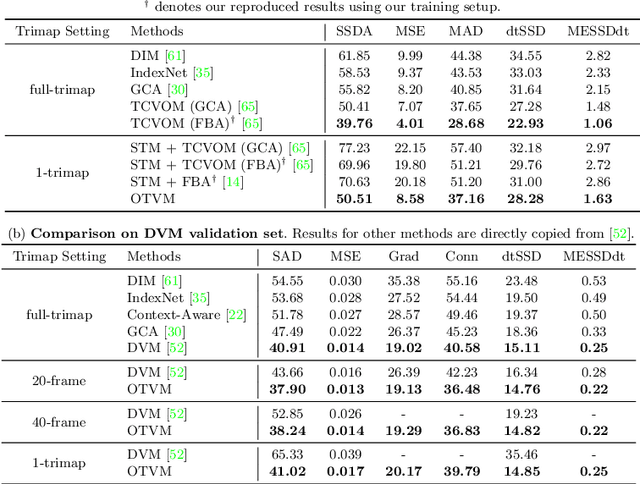
Recent studies made great progress in video matting by extending the success of trimap-based image matting to the video domain. In this paper, we push this task toward a more practical setting and propose One-Trimap Video Matting network (OTVM) that performs video matting robustly using only one user-annotated trimap. A key of OTVM is the joint modeling of trimap propagation and alpha prediction. Starting from baseline trimap propagation and alpha prediction networks, our OTVM combines the two networks with an alpha-trimap refinement module to facilitate information flow. We also present an end-to-end training strategy to take full advantage of the joint model. Our joint modeling greatly improves the temporal stability of trimap propagation compared to the previous decoupled methods. We evaluate our model on two latest video matting benchmarks, Deep Video Matting and VideoMatting108, and outperform state-of-the-art by significant margins (MSE improvements of 56.4% and 56.7%, respectively). The source code and model are available online: https://github.com/Hongje/OTVM.
Correlation Verification for Image Retrieval
Apr 04, 2022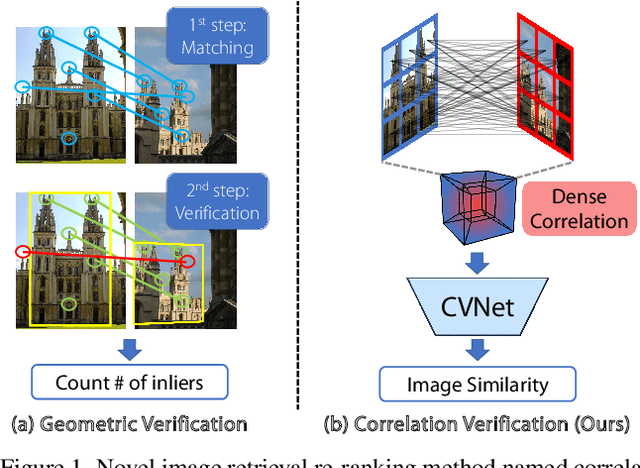
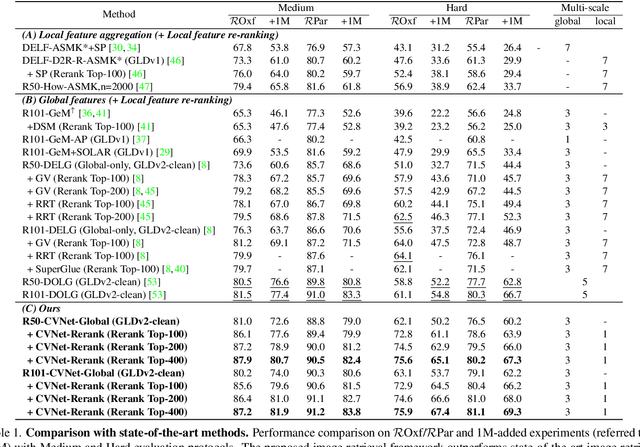

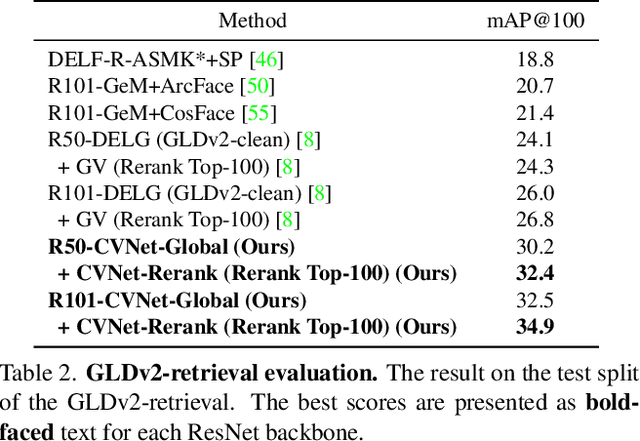
Geometric verification is considered a de facto solution for the re-ranking task in image retrieval. In this study, we propose a novel image retrieval re-ranking network named Correlation Verification Networks (CVNet). Our proposed network, comprising deeply stacked 4D convolutional layers, gradually compresses dense feature correlation into image similarity while learning diverse geometric matching patterns from various image pairs. To enable cross-scale matching, it builds feature pyramids and constructs cross-scale feature correlations within a single inference, replacing costly multi-scale inferences. In addition, we use curriculum learning with the hard negative mining and Hide-and-Seek strategy to handle hard samples without losing generality. Our proposed re-ranking network shows state-of-the-art performance on several retrieval benchmarks with a significant margin (+12.6% in mAP on ROxford-Hard+1M set) over state-of-the-art methods. The source code and models are available online: https://github.com/sungonce/CVNet.
WildNet: Learning Domain Generalized Semantic Segmentation from the Wild
Apr 04, 2022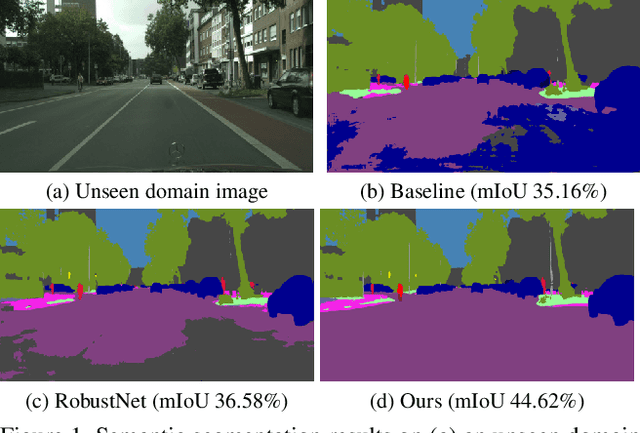
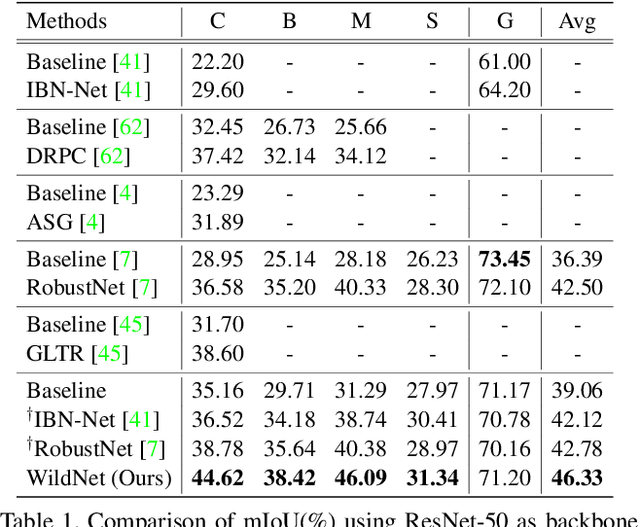
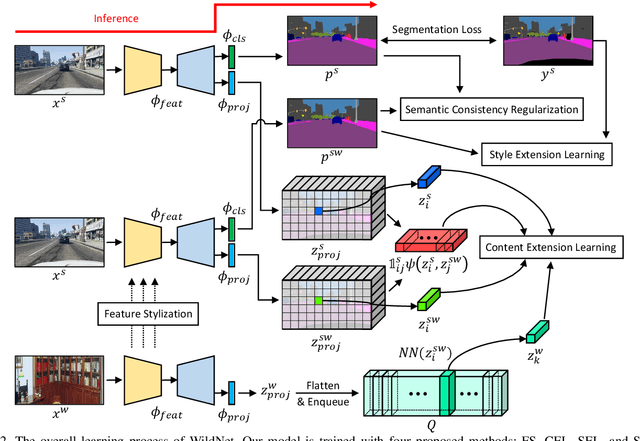
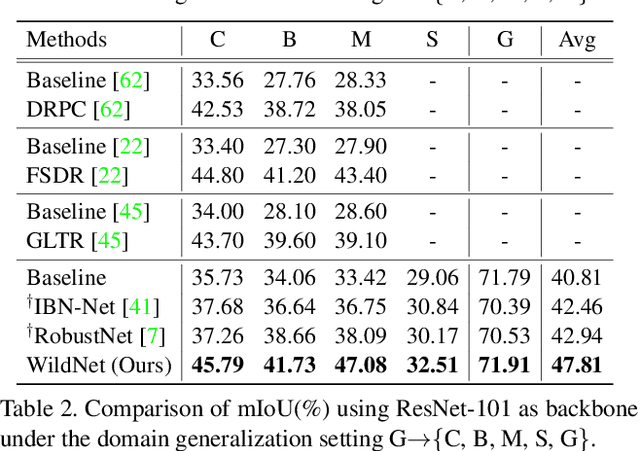
We present a new domain generalized semantic segmentation network named WildNet, which learns domain-generalized features by leveraging a variety of contents and styles from the wild. In domain generalization, the low generalization ability for unseen target domains is clearly due to overfitting to the source domain. To address this problem, previous works have focused on generalizing the domain by removing or diversifying the styles of the source domain. These alleviated overfitting to the source-style but overlooked overfitting to the source-content. In this paper, we propose to diversify both the content and style of the source domain with the help of the wild. Our main idea is for networks to naturally learn domain-generalized semantic information from the wild. To this end, we diversify styles by augmenting source features to resemble wild styles and enable networks to adapt to a variety of styles. Furthermore, we encourage networks to learn class-discriminant features by providing semantic variations borrowed from the wild to source contents in the feature space. Finally, we regularize networks to capture consistent semantic information even when both the content and style of the source domain are extended to the wild. Extensive experiments on five different datasets validate the effectiveness of our WildNet, and we significantly outperform state-of-the-art methods. The source code and model are available online: https://github.com/suhyeonlee/WildNet.
Iteratively Selecting an Easy Reference Frame Makes Unsupervised Video Object Segmentation Easier
Dec 23, 2021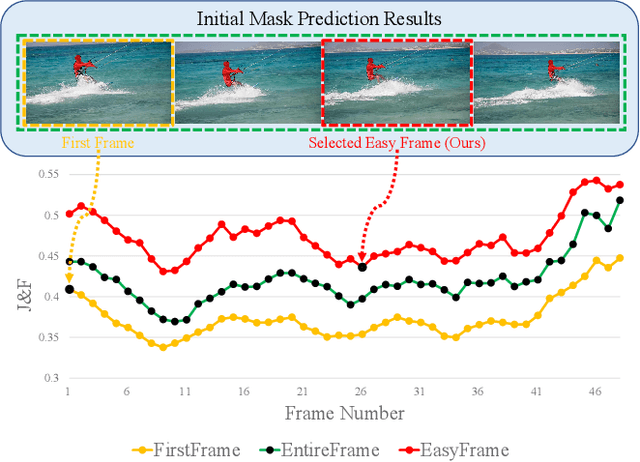



Unsupervised video object segmentation (UVOS) is a per-pixel binary labeling problem which aims at separating the foreground object from the background in the video without using the ground truth (GT) mask of the foreground object. Most of the previous UVOS models use the first frame or the entire video as a reference frame to specify the mask of the foreground object. Our question is why the first frame should be selected as a reference frame or why the entire video should be used to specify the mask. We believe that we can select a better reference frame to achieve the better UVOS performance than using only the first frame or the entire video as a reference frame. In our paper, we propose Easy Frame Selector (EFS). The EFS enables us to select an 'easy' reference frame that makes the subsequent VOS become easy, thereby improving the VOS performance. Furthermore, we propose a new framework named as Iterative Mask Prediction (IMP). In the framework, we repeat applying EFS to the given video and selecting an 'easier' reference frame from the video than the previous iteration, increasing the VOS performance incrementally. The IMP consists of EFS, Bi-directional Mask Prediction (BMP), and Temporal Information Updating (TIU). From the proposed framework, we achieve state-of-the-art performance in three UVOS benchmark sets: DAVIS16, FBMS, and SegTrack-V2.
Hierarchical Memory Matching Network for Video Object Segmentation
Sep 23, 2021
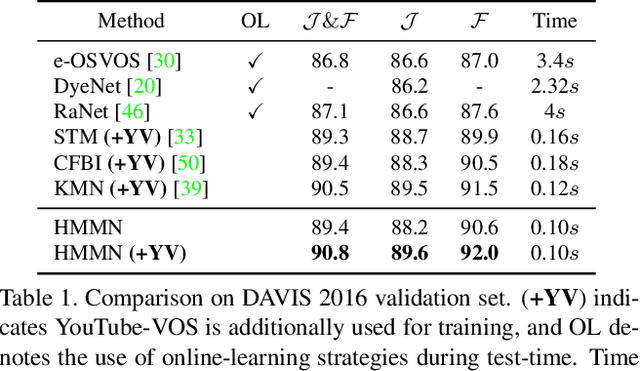
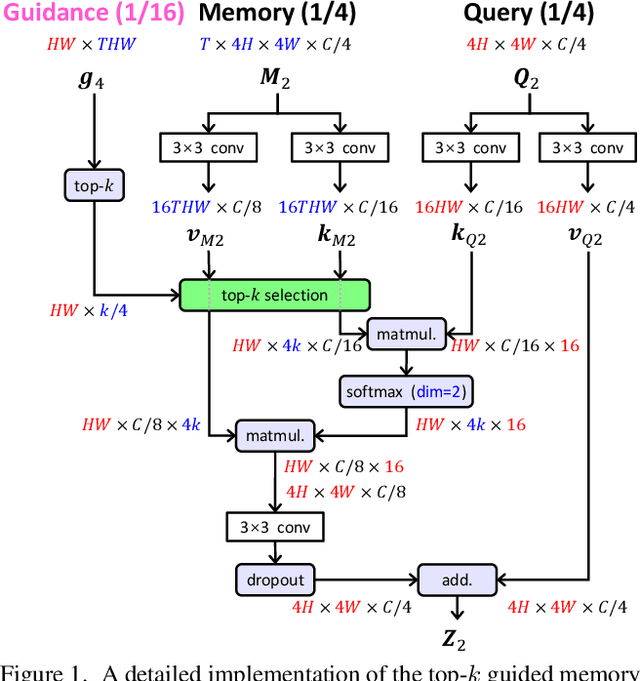
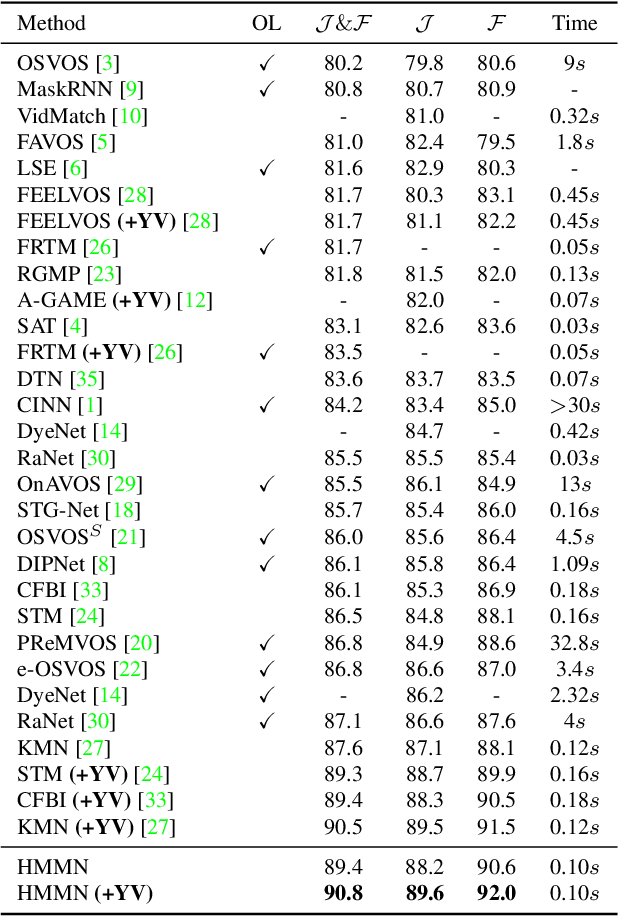
We present Hierarchical Memory Matching Network (HMMN) for semi-supervised video object segmentation. Based on a recent memory-based method [33], we propose two advanced memory read modules that enable us to perform memory reading in multiple scales while exploiting temporal smoothness. We first propose a kernel guided memory matching module that replaces the non-local dense memory read, commonly adopted in previous memory-based methods. The module imposes the temporal smoothness constraint in the memory read, leading to accurate memory retrieval. More importantly, we introduce a hierarchical memory matching scheme and propose a top-k guided memory matching module in which memory read on a fine-scale is guided by that on a coarse-scale. With the module, we perform memory read in multiple scales efficiently and leverage both high-level semantic and low-level fine-grained memory features to predict detailed object masks. Our network achieves state-of-the-art performance on the validation sets of DAVIS 2016/2017 (90.8% and 84.7%) and YouTube-VOS 2018/2019 (82.6% and 82.5%), and test-dev set of DAVIS 2017 (78.6%). The source code and model are available online: https://github.com/Hongje/HMMN.