 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIteratively Selecting an Easy Reference Frame Makes Unsupervised Video Object Segmentation Easier
Paper and Code
Dec 23, 2021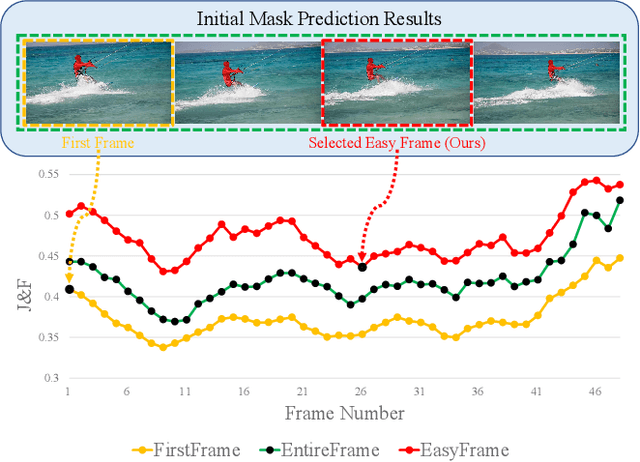



Unsupervised video object segmentation (UVOS) is a per-pixel binary labeling problem which aims at separating the foreground object from the background in the video without using the ground truth (GT) mask of the foreground object. Most of the previous UVOS models use the first frame or the entire video as a reference frame to specify the mask of the foreground object. Our question is why the first frame should be selected as a reference frame or why the entire video should be used to specify the mask. We believe that we can select a better reference frame to achieve the better UVOS performance than using only the first frame or the entire video as a reference frame. In our paper, we propose Easy Frame Selector (EFS). The EFS enables us to select an 'easy' reference frame that makes the subsequent VOS become easy, thereby improving the VOS performance. Furthermore, we propose a new framework named as Iterative Mask Prediction (IMP). In the framework, we repeat applying EFS to the given video and selecting an 'easier' reference frame from the video than the previous iteration, increasing the VOS performance incrementally. The IMP consists of EFS, Bi-directional Mask Prediction (BMP), and Temporal Information Updating (TIU). From the proposed framework, we achieve state-of-the-art performance in three UVOS benchmark sets: DAVIS16, FBMS, and SegTrack-V2.