 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Pose Refinement in 3D Gaussian Splatting under Pose Prior and Geometric Uncertainty
Mar 17, 20263D Gaussian Splatting (3DGS) has recently emerged as a powerful scene representation and is increasingly used for visual localization and pose refinement. However, despite its high-quality differentiable rendering, the robustness of 3DGS-based pose refinement remains highly sensitive to both the initial camera pose and the reconstructed geometry. In this work, we take a closer look at these limitations and identify two major sources of uncertainty: (i) pose prior uncertainty, which often arises from regression or retrieval models that output a single deterministic estimate, and (ii) geometric uncertainty, caused by imperfections in the 3DGS reconstruction that propagate errors into PnP solvers. Such uncertainties can distort reprojection geometry and destabilize optimization, even when the rendered appearance still looks plausible. To address these uncertainties, we introduce a relocalization framework that combines Monte Carlo pose sampling with Fisher Information-based PnP optimization. Our method explicitly accounts for both pose and geometric uncertainty and requires no retraining or additional supervision. Across diverse indoor and outdoor benchmarks, our approach consistently improves localization accuracy and significantly increases stability under pose and depth noise.
Swap-guided Preference Learning for Personalized Reinforcement Learning from Human Feedback
Mar 13, 2026Reinforcement Learning from Human Feedback (RLHF) is a widely used approach to align large-scale AI systems with human values. However, RLHF typically assumes a single, universal reward, which overlooks diverse preferences and limits personalization. Variational Preference Learning (VPL) seeks to address this by introducing user-specific latent variables. Despite its promise, we found that VPL suffers from posterior collapse. While this phenomenon is well known in VAEs, it has not previously been identified in preference learning frameworks. Under sparse preference data and with overly expressive decoders, VPL may cause latent variables to be ignored, reverting to a single-reward model. To overcome this limitation, we propose Swap-guided Preference Learning (SPL). The key idea is to construct fictitious swap annotators and use the mirroring property of their preferences to guide the encoder. SPL introduces three components: (1) swap-guided base regularization, (2) Preferential Inverse Autoregressive Flow (P-IAF), and (3) adaptive latent conditioning. Experiments show that SPL mitigates collapse, enriches user-specific latents, and improves preference prediction. Our code and data are available at https://github.com/cobang0111/SPL
A$^2$LC: Active and Automated Label Correction for Semantic Segmentation
Jun 13, 2025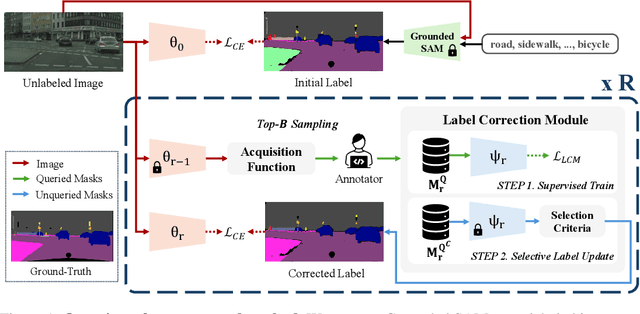
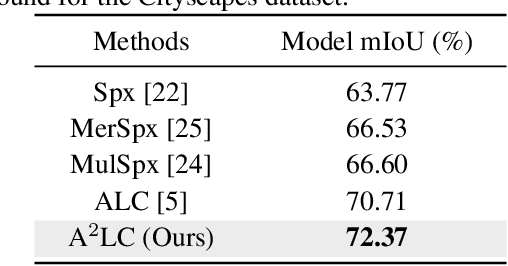
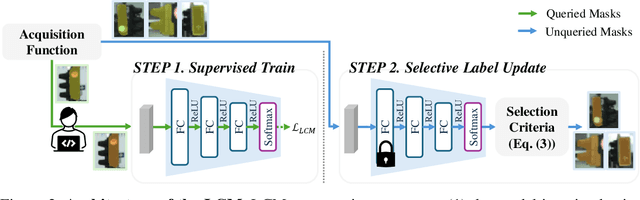
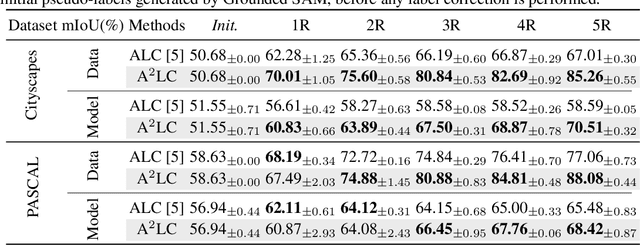
Active Label Correction (ALC) has emerged as a promising solution to the high cost and error-prone nature of manual pixel-wise annotation in semantic segmentation, by selectively identifying and correcting mislabeled data. Although recent work has improved correction efficiency by generating pseudo-labels using foundation models, substantial inefficiencies still remain. In this paper, we propose Active and Automated Label Correction for semantic segmentation (A$^2$LC), a novel and efficient ALC framework that integrates an automated correction stage into the conventional pipeline. Specifically, the automated correction stage leverages annotator feedback to perform label correction beyond the queried samples, thereby maximizing cost efficiency. In addition, we further introduce an adaptively balanced acquisition function that emphasizes underrepresented tail classes and complements the automated correction mechanism. Extensive experiments on Cityscapes and PASCAL VOC 2012 demonstrate that A$^2$LC significantly outperforms previous state-of-the-art methods. Notably, A$^2$LC achieves high efficiency by outperforming previous methods using only 20% of their budget, and demonstrates strong effectiveness by yielding a 27.23% performance improvement under an equivalent budget constraint on the Cityscapes dataset. The code will be released upon acceptance.
Environmental Change Detection: Toward a Practical Task of Scene Change Detection
Jun 13, 2025Humans do not memorize everything. Thus, humans recognize scene changes by exploring the past images. However, available past (i.e., reference) images typically represent nearby viewpoints of the present (i.e., query) scene, rather than the identical view. Despite this practical limitation, conventional Scene Change Detection (SCD) has been formalized under an idealized setting in which reference images with matching viewpoints are available for every query. In this paper, we push this problem toward a practical task and introduce Environmental Change Detection (ECD). A key aspect of ECD is to avoid unrealistically aligned query-reference pairs and rely solely on environmental cues. Inspired by real-world practices, we provide these cues through a large-scale database of uncurated images. To address this new task, we propose a novel framework that jointly understands spatial environments and detects changes. The main idea is that matching at the same spatial locations between a query and a reference may lead to a suboptimal solution due to viewpoint misalignment and limited field-of-view (FOV) coverage. We deal with this limitation by leveraging multiple reference candidates and aggregating semantically rich representations for change detection. We evaluate our framework on three standard benchmark sets reconstructed for ECD, and significantly outperform a naive combination of state-of-the-art methods while achieving comparable performance to the oracle setting. The code will be released upon acceptance.
HypeVPR: Exploring Hyperbolic Space for Perspective to Equirectangular Visual Place Recognition
Jun 05, 2025When applying Visual Place Recognition (VPR) to real-world mobile robots and similar applications, perspective-to-equirectangular (P2E) formulation naturally emerges as a suitable approach to accommodate diverse query images captured from various viewpoints. In this paper, we introduce HypeVPR, a novel hierarchical embedding framework in hyperbolic space, designed to address the unique challenges of P2E VPR. The key idea behind HypeVPR is that visual environments captured by panoramic views exhibit inherent hierarchical structures. To leverage this property, we employ hyperbolic space to represent hierarchical feature relationships and preserve distance properties within the feature space. To achieve this, we propose a hierarchical feature aggregation mechanism that organizes local-to-global feature representations within hyperbolic space. Additionally, HypeVPR adopts an efficient coarse-to-fine search strategy, optimally balancing speed and accuracy to ensure robust matching, even between descriptors from different image types. This approach enables HypeVPR to outperform state-of-the-art methods while significantly reducing retrieval time, achieving up to 5x faster retrieval across diverse benchmark datasets. The code and models will be released at https://github.com/suhan-woo/HypeVPR.git.
RE-TRIP : Reflectivity Instance Augmented Triangle Descriptor for 3D Place Recognition
May 22, 2025While most people associate LiDAR primarily with its ability to measure distances and provide geometric information about the environment (via point clouds), LiDAR also captures additional data, including reflectivity or intensity values. Unfortunately, when LiDAR is applied to Place Recognition (PR) in mobile robotics, most previous works on LiDAR-based PR rely only on geometric measurements, neglecting the additional reflectivity information that LiDAR provides. In this paper, we propose a novel descriptor for 3D PR, named RE-TRIP (REflectivity-instance augmented TRIangle descriPtor). This new descriptor leverages both geometric measurements and reflectivity to enhance robustness in challenging scenarios such as geometric degeneracy, high geometric similarity, and the presence of dynamic objects. To implement RE-TRIP in real-world applications, we further propose (1) a keypoint extraction method, (2) a key instance segmentation method, (3) a RE-TRIP matching method, and (4) a reflectivity-combined loop verification method. Finally, we conduct a series of experiments to demonstrate the effectiveness of RE-TRIP. Applied to public datasets (i.e., HELIPR, FusionPortable) containing diverse scenarios such as long corridors, bridges, large-scale urban areas, and highly dynamic environments -- our experimental results show that the proposed method outperforms existing state-of-the-art methods in terms of Scan Context, Intensity Scan Context, and STD.
DGS-SLAM: Gaussian Splatting SLAM in Dynamic Environment
Nov 16, 2024
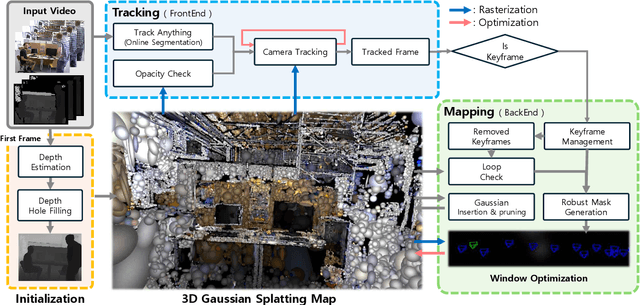


We introduce Dynamic Gaussian Splatting SLAM (DGS-SLAM), the first dynamic SLAM framework built on the foundation of Gaussian Splatting. While recent advancements in dense SLAM have leveraged Gaussian Splatting to enhance scene representation, most approaches assume a static environment, making them vulnerable to photometric and geometric inconsistencies caused by dynamic objects. To address these challenges, we integrate Gaussian Splatting SLAM with a robust filtering process to handle dynamic objects throughout the entire pipeline, including Gaussian insertion and keyframe selection. Within this framework, to further improve the accuracy of dynamic object removal, we introduce a robust mask generation method that enforces photometric consistency across keyframes, reducing noise from inaccurate segmentation and artifacts such as shadows. Additionally, we propose the loop-aware window selection mechanism, which utilizes unique keyframe IDs of 3D Gaussians to detect loops between the current and past frames, facilitating joint optimization of the current camera poses and the Gaussian map. DGS-SLAM achieves state-of-the-art performance in both camera tracking and novel view synthesis on various dynamic SLAM benchmarks, proving its effectiveness in handling real-world dynamic scenes.
Decomposition of Neural Discrete Representations for Large-Scale 3D Mapping
Jul 22, 2024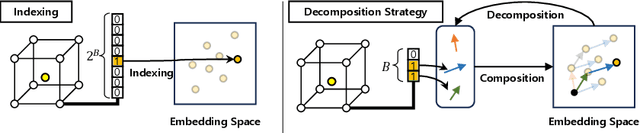
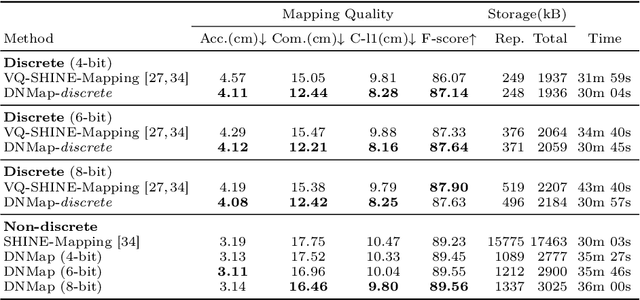
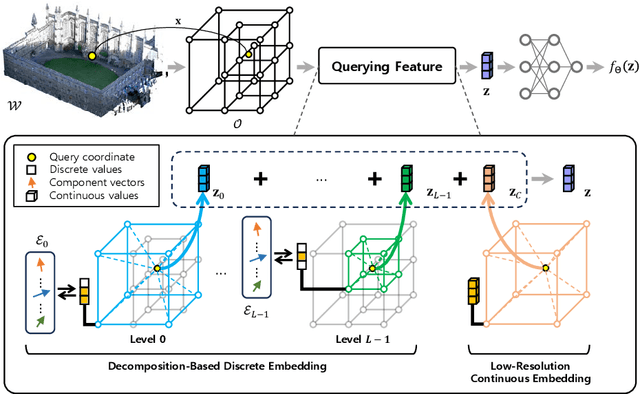
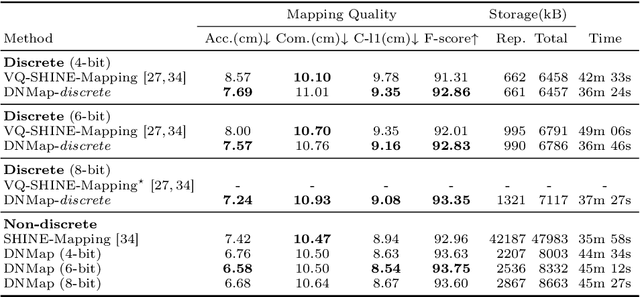
Learning efficient representations of local features is a key challenge in feature volume-based 3D neural mapping, especially in large-scale environments. In this paper, we introduce Decomposition-based Neural Mapping (DNMap), a storage-efficient large-scale 3D mapping method that employs a discrete representation based on a decomposition strategy. This decomposition strategy aims to efficiently capture repetitive and representative patterns of shapes by decomposing each discrete embedding into component vectors that are shared across the embedding space. Our DNMap optimizes a set of component vectors, rather than entire discrete embeddings, and learns composition rather than indexing the discrete embeddings. Furthermore, to complement the mapping quality, we additionally learn low-resolution continuous embeddings that require tiny storage space. By combining these representations with a shallow neural network and an efficient octree-based feature volume, our DNMap successfully approximates signed distance functions and compresses the feature volume while preserving mapping quality. Our source code is available at https://github.com/minseong-p/dnmap.
Fast Global Localization on Neural Radiance Field
Jun 18, 2024



Neural Radiance Fields (NeRF) presented a novel way to represent scenes, allowing for high-quality 3D reconstruction from 2D images. Following its remarkable achievements, global localization within NeRF maps is an essential task for enabling a wide range of applications. Recently, Loc-NeRF demonstrated a localization approach that combines traditional Monte Carlo Localization with NeRF, showing promising results for using NeRF as an environment map. However, despite its advancements, Loc-NeRF encounters the challenge of a time-intensive ray rendering process, which can be a significant limitation in practical applications. To address this issue, we introduce Fast Loc-NeRF, which leverages a coarse-to-fine approach to enable more efficient and accurate NeRF map-based global localization. Specifically, Fast Loc-NeRF matches rendered pixels and observed images on a multi-resolution from low to high resolution. As a result, it speeds up the costly particle update process while maintaining precise localization results. Additionally, to reject the abnormal particles, we propose particle rejection weighting, which estimates the uncertainty of particles by exploiting NeRF's characteristics and considers them in the particle weighting process. Our Fast Loc-NeRF sets new state-of-the-art localization performances on several benchmarks, convincing its accuracy and efficiency.
Zero-Shot Scene Change Detection
Jun 17, 2024
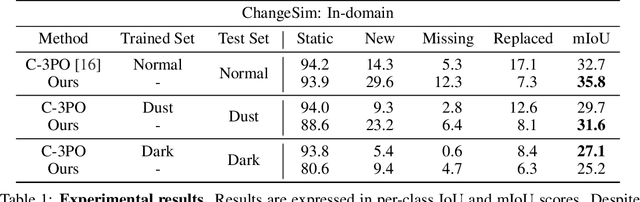
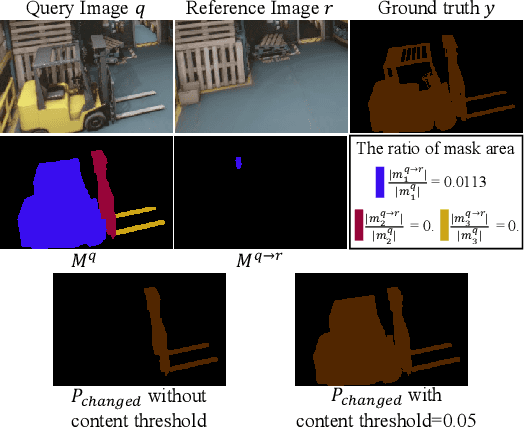
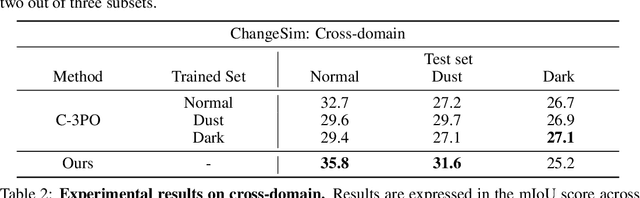
We present a novel, training-free approach to scene change detection. Our method leverages tracking models, which inherently perform change detection between consecutive frames of video by identifying common objects and detecting new or missing objects. Specifically, our method takes advantage of the change detection effect of the tracking model by inputting reference and query images instead of consecutive frames. Furthermore, we focus on the content gap and style gap between two input images in change detection, and address both issues by proposing adaptive content threshold and style bridging layers, respectively. Finally, we extend our approach to video to exploit rich temporal information, enhancing scene change detection performance. We compare our approach and baseline through various experiments. While existing train-based baseline tend to specialize only in the trained domain, our method shows consistent performance across various domains, proving the competitiveness of our approach.