 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Pose Refinement in 3D Gaussian Splatting under Pose Prior and Geometric Uncertainty
Mar 17, 20263D Gaussian Splatting (3DGS) has recently emerged as a powerful scene representation and is increasingly used for visual localization and pose refinement. However, despite its high-quality differentiable rendering, the robustness of 3DGS-based pose refinement remains highly sensitive to both the initial camera pose and the reconstructed geometry. In this work, we take a closer look at these limitations and identify two major sources of uncertainty: (i) pose prior uncertainty, which often arises from regression or retrieval models that output a single deterministic estimate, and (ii) geometric uncertainty, caused by imperfections in the 3DGS reconstruction that propagate errors into PnP solvers. Such uncertainties can distort reprojection geometry and destabilize optimization, even when the rendered appearance still looks plausible. To address these uncertainties, we introduce a relocalization framework that combines Monte Carlo pose sampling with Fisher Information-based PnP optimization. Our method explicitly accounts for both pose and geometric uncertainty and requires no retraining or additional supervision. Across diverse indoor and outdoor benchmarks, our approach consistently improves localization accuracy and significantly increases stability under pose and depth noise.
HypeVPR: Exploring Hyperbolic Space for Perspective to Equirectangular Visual Place Recognition
Jun 05, 2025When applying Visual Place Recognition (VPR) to real-world mobile robots and similar applications, perspective-to-equirectangular (P2E) formulation naturally emerges as a suitable approach to accommodate diverse query images captured from various viewpoints. In this paper, we introduce HypeVPR, a novel hierarchical embedding framework in hyperbolic space, designed to address the unique challenges of P2E VPR. The key idea behind HypeVPR is that visual environments captured by panoramic views exhibit inherent hierarchical structures. To leverage this property, we employ hyperbolic space to represent hierarchical feature relationships and preserve distance properties within the feature space. To achieve this, we propose a hierarchical feature aggregation mechanism that organizes local-to-global feature representations within hyperbolic space. Additionally, HypeVPR adopts an efficient coarse-to-fine search strategy, optimally balancing speed and accuracy to ensure robust matching, even between descriptors from different image types. This approach enables HypeVPR to outperform state-of-the-art methods while significantly reducing retrieval time, achieving up to 5x faster retrieval across diverse benchmark datasets. The code and models will be released at https://github.com/suhan-woo/HypeVPR.git.
Lazy-DaSH: Lazy Approach for Hypergraph-based Multi-robot Task and Motion Planning
Apr 07, 2025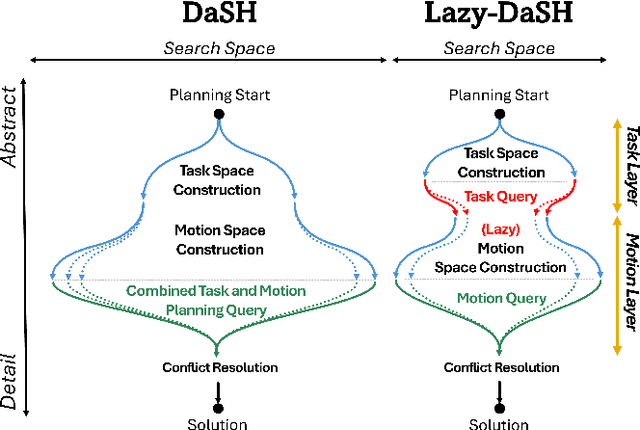
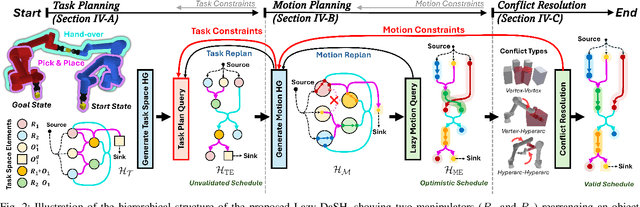
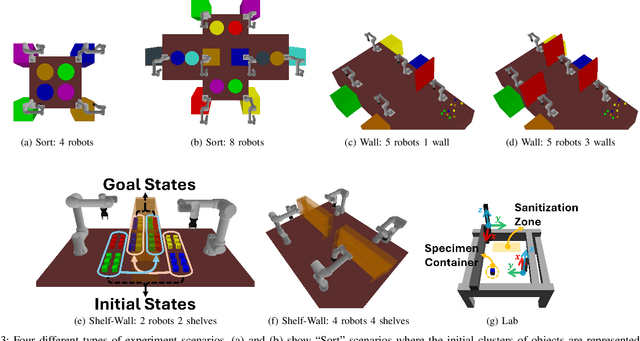

We introduce Lazy-DaSH, an improvement over the recent state of the art multi-robot task and motion planning method DaSH, which scales to more than double the number of robots and objects compared to the original method and achieves an order of magnitude faster planning time when applied to a multi-manipulator object rearrangement problem. We achieve this improvement through a hierarchical approach, where a high-level task planning layer identifies planning spaces required for task completion, and motion feasibility is validated lazily only within these spaces. In contrast, DaSH precomputes the motion feasibility of all possible actions, resulting in higher costs for constructing state space representations. Lazy-DaSH maintains efficient query performance by utilizing a constraint feedback mechanism within its hierarchical structure, ensuring that motion feasibility is effectively conveyed to the query process. By maintaining smaller state space representations, our method significantly reduces both representation construction time and query time. We evaluate Lazy-DaSH in four distinct scenarios, demonstrating its scalability to increasing numbers of robots and objects, as well as its adaptability in resolving conflicts through the constraint feedback mechanism.
DGS-SLAM: Gaussian Splatting SLAM in Dynamic Environment
Nov 16, 2024
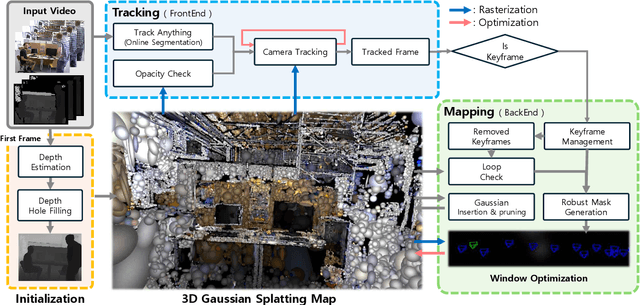


We introduce Dynamic Gaussian Splatting SLAM (DGS-SLAM), the first dynamic SLAM framework built on the foundation of Gaussian Splatting. While recent advancements in dense SLAM have leveraged Gaussian Splatting to enhance scene representation, most approaches assume a static environment, making them vulnerable to photometric and geometric inconsistencies caused by dynamic objects. To address these challenges, we integrate Gaussian Splatting SLAM with a robust filtering process to handle dynamic objects throughout the entire pipeline, including Gaussian insertion and keyframe selection. Within this framework, to further improve the accuracy of dynamic object removal, we introduce a robust mask generation method that enforces photometric consistency across keyframes, reducing noise from inaccurate segmentation and artifacts such as shadows. Additionally, we propose the loop-aware window selection mechanism, which utilizes unique keyframe IDs of 3D Gaussians to detect loops between the current and past frames, facilitating joint optimization of the current camera poses and the Gaussian map. DGS-SLAM achieves state-of-the-art performance in both camera tracking and novel view synthesis on various dynamic SLAM benchmarks, proving its effectiveness in handling real-world dynamic scenes.
Fast Global Localization on Neural Radiance Field
Jun 18, 2024



Neural Radiance Fields (NeRF) presented a novel way to represent scenes, allowing for high-quality 3D reconstruction from 2D images. Following its remarkable achievements, global localization within NeRF maps is an essential task for enabling a wide range of applications. Recently, Loc-NeRF demonstrated a localization approach that combines traditional Monte Carlo Localization with NeRF, showing promising results for using NeRF as an environment map. However, despite its advancements, Loc-NeRF encounters the challenge of a time-intensive ray rendering process, which can be a significant limitation in practical applications. To address this issue, we introduce Fast Loc-NeRF, which leverages a coarse-to-fine approach to enable more efficient and accurate NeRF map-based global localization. Specifically, Fast Loc-NeRF matches rendered pixels and observed images on a multi-resolution from low to high resolution. As a result, it speeds up the costly particle update process while maintaining precise localization results. Additionally, to reject the abnormal particles, we propose particle rejection weighting, which estimates the uncertainty of particles by exploiting NeRF's characteristics and considers them in the particle weighting process. Our Fast Loc-NeRF sets new state-of-the-art localization performances on several benchmarks, convincing its accuracy and efficiency.
Correlation Verification for Image Retrieval
Apr 04, 2022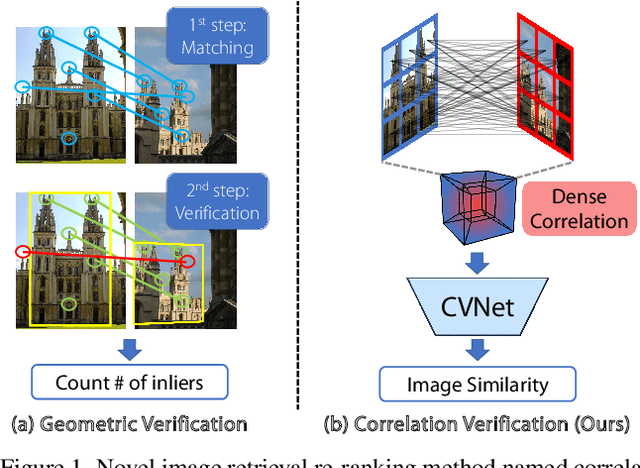
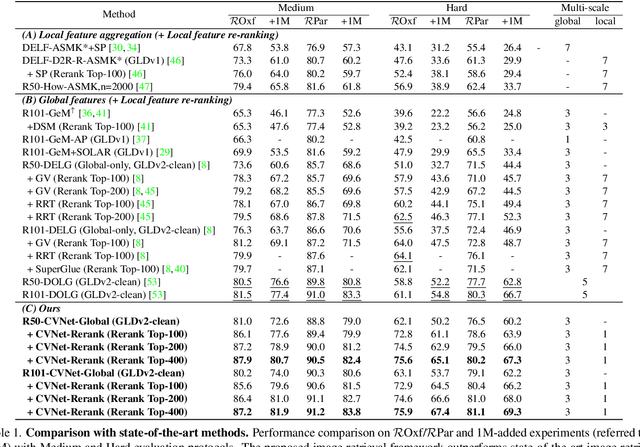

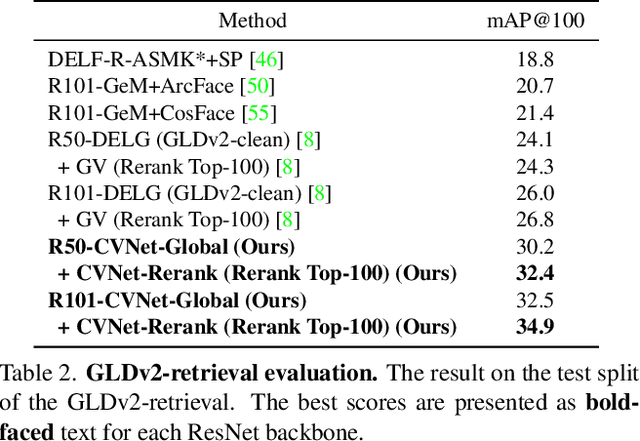
Geometric verification is considered a de facto solution for the re-ranking task in image retrieval. In this study, we propose a novel image retrieval re-ranking network named Correlation Verification Networks (CVNet). Our proposed network, comprising deeply stacked 4D convolutional layers, gradually compresses dense feature correlation into image similarity while learning diverse geometric matching patterns from various image pairs. To enable cross-scale matching, it builds feature pyramids and constructs cross-scale feature correlations within a single inference, replacing costly multi-scale inferences. In addition, we use curriculum learning with the hard negative mining and Hide-and-Seek strategy to handle hard samples without losing generality. Our proposed re-ranking network shows state-of-the-art performance on several retrieval benchmarks with a significant margin (+12.6% in mAP on ROxford-Hard+1M set) over state-of-the-art methods. The source code and models are available online: https://github.com/sungonce/CVNet.
WildNet: Learning Domain Generalized Semantic Segmentation from the Wild
Apr 04, 2022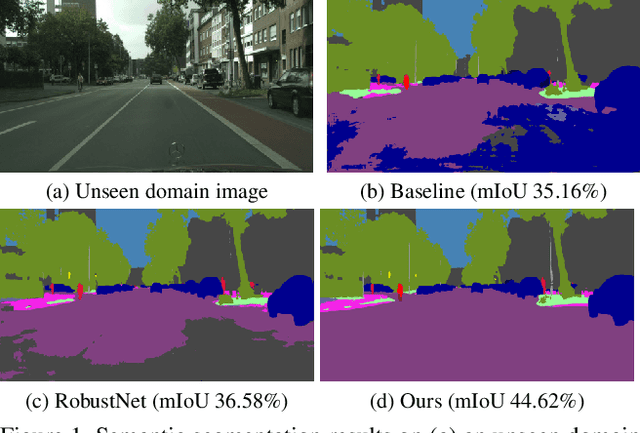
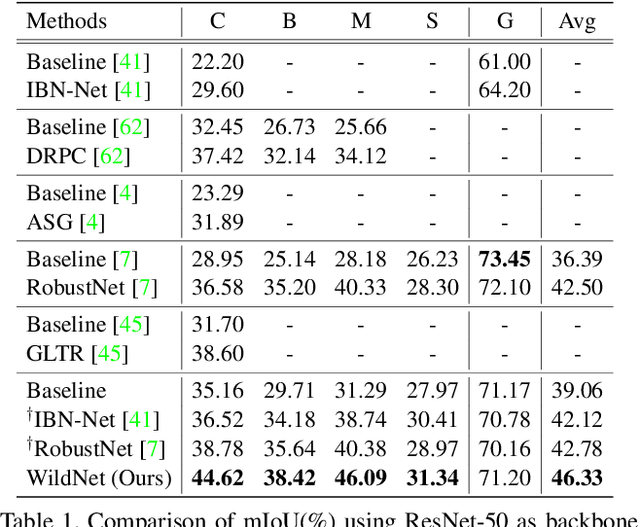
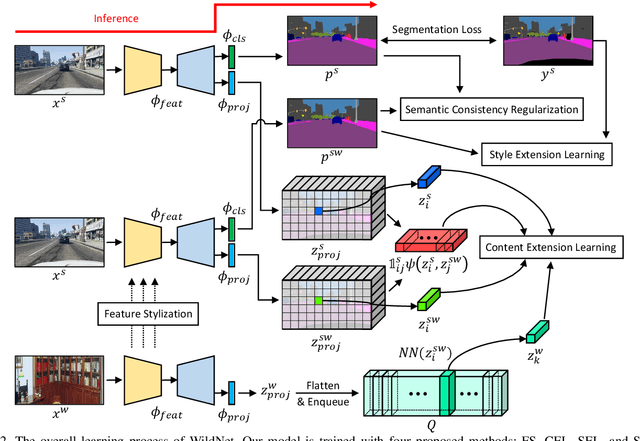
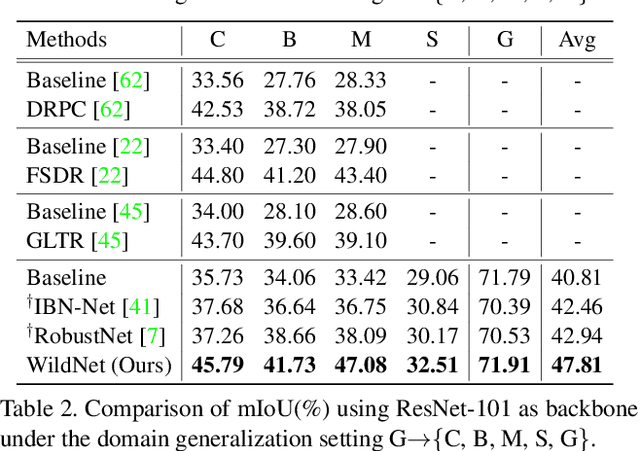
We present a new domain generalized semantic segmentation network named WildNet, which learns domain-generalized features by leveraging a variety of contents and styles from the wild. In domain generalization, the low generalization ability for unseen target domains is clearly due to overfitting to the source domain. To address this problem, previous works have focused on generalizing the domain by removing or diversifying the styles of the source domain. These alleviated overfitting to the source-style but overlooked overfitting to the source-content. In this paper, we propose to diversify both the content and style of the source domain with the help of the wild. Our main idea is for networks to naturally learn domain-generalized semantic information from the wild. To this end, we diversify styles by augmenting source features to resemble wild styles and enable networks to adapt to a variety of styles. Furthermore, we encourage networks to learn class-discriminant features by providing semantic variations borrowed from the wild to source contents in the feature space. Finally, we regularize networks to capture consistent semantic information even when both the content and style of the source domain are extended to the wild. Extensive experiments on five different datasets validate the effectiveness of our WildNet, and we significantly outperform state-of-the-art methods. The source code and model are available online: https://github.com/suhyeonlee/WildNet.
Hierarchical Memory Matching Network for Video Object Segmentation
Sep 23, 2021
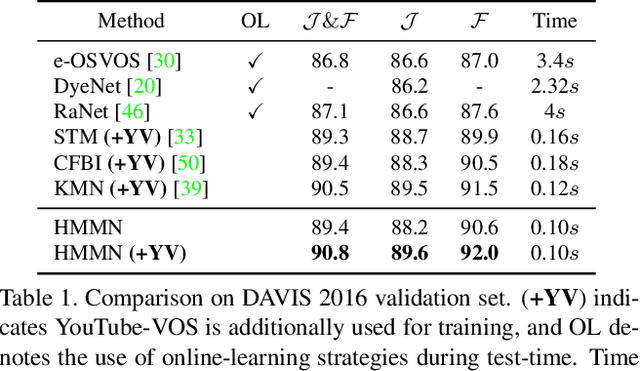
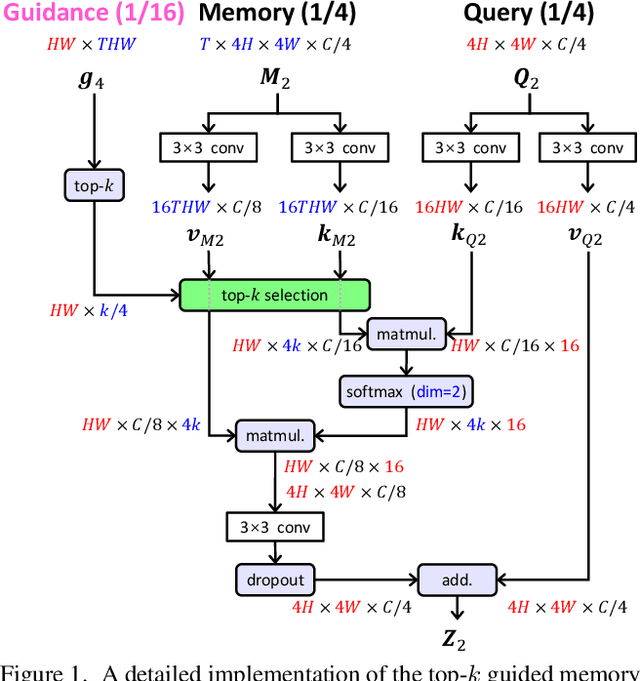
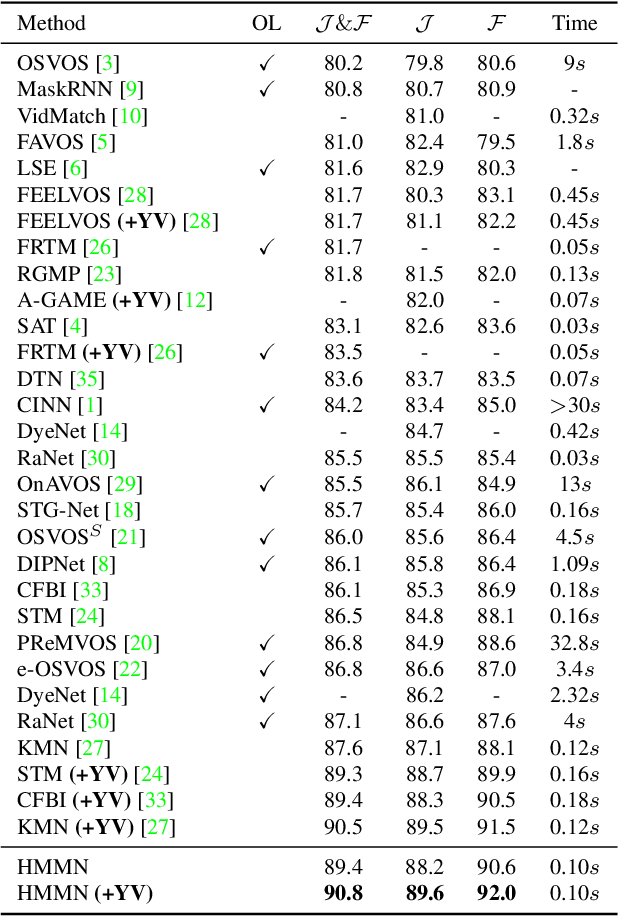
We present Hierarchical Memory Matching Network (HMMN) for semi-supervised video object segmentation. Based on a recent memory-based method [33], we propose two advanced memory read modules that enable us to perform memory reading in multiple scales while exploiting temporal smoothness. We first propose a kernel guided memory matching module that replaces the non-local dense memory read, commonly adopted in previous memory-based methods. The module imposes the temporal smoothness constraint in the memory read, leading to accurate memory retrieval. More importantly, we introduce a hierarchical memory matching scheme and propose a top-k guided memory matching module in which memory read on a fine-scale is guided by that on a coarse-scale. With the module, we perform memory read in multiple scales efficiently and leverage both high-level semantic and low-level fine-grained memory features to predict detailed object masks. Our network achieves state-of-the-art performance on the validation sets of DAVIS 2016/2017 (90.8% and 84.7%) and YouTube-VOS 2018/2019 (82.6% and 82.5%), and test-dev set of DAVIS 2017 (78.6%). The source code and model are available online: https://github.com/Hongje/HMMN.