 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA$^2$LC: Active and Automated Label Correction for Semantic Segmentation
Jun 13, 2025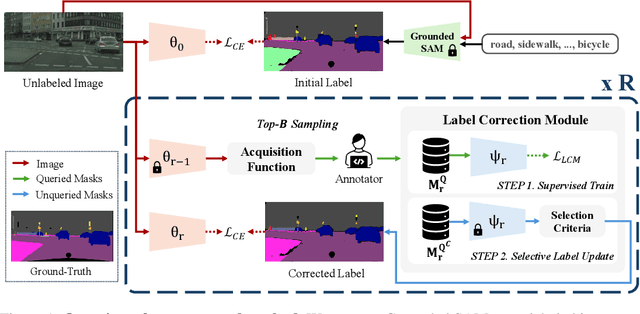
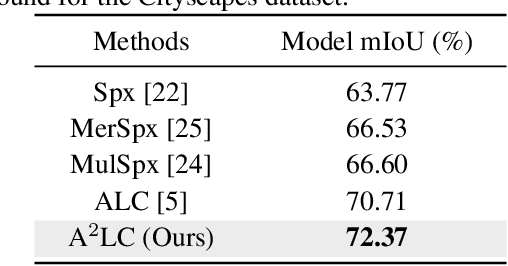
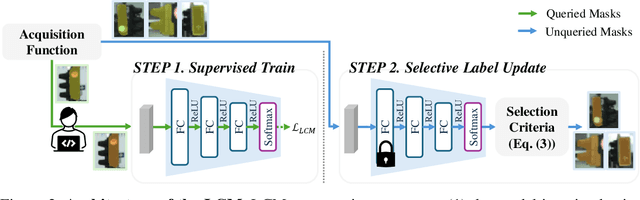
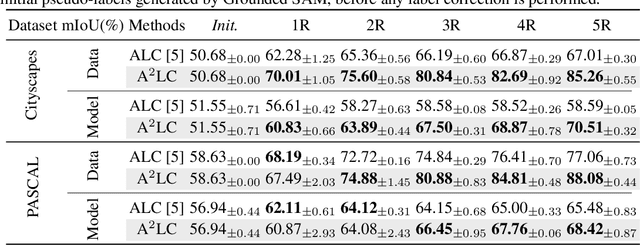
Active Label Correction (ALC) has emerged as a promising solution to the high cost and error-prone nature of manual pixel-wise annotation in semantic segmentation, by selectively identifying and correcting mislabeled data. Although recent work has improved correction efficiency by generating pseudo-labels using foundation models, substantial inefficiencies still remain. In this paper, we propose Active and Automated Label Correction for semantic segmentation (A$^2$LC), a novel and efficient ALC framework that integrates an automated correction stage into the conventional pipeline. Specifically, the automated correction stage leverages annotator feedback to perform label correction beyond the queried samples, thereby maximizing cost efficiency. In addition, we further introduce an adaptively balanced acquisition function that emphasizes underrepresented tail classes and complements the automated correction mechanism. Extensive experiments on Cityscapes and PASCAL VOC 2012 demonstrate that A$^2$LC significantly outperforms previous state-of-the-art methods. Notably, A$^2$LC achieves high efficiency by outperforming previous methods using only 20% of their budget, and demonstrates strong effectiveness by yielding a 27.23% performance improvement under an equivalent budget constraint on the Cityscapes dataset. The code will be released upon acceptance.
Environmental Change Detection: Toward a Practical Task of Scene Change Detection
Jun 13, 2025Humans do not memorize everything. Thus, humans recognize scene changes by exploring the past images. However, available past (i.e., reference) images typically represent nearby viewpoints of the present (i.e., query) scene, rather than the identical view. Despite this practical limitation, conventional Scene Change Detection (SCD) has been formalized under an idealized setting in which reference images with matching viewpoints are available for every query. In this paper, we push this problem toward a practical task and introduce Environmental Change Detection (ECD). A key aspect of ECD is to avoid unrealistically aligned query-reference pairs and rely solely on environmental cues. Inspired by real-world practices, we provide these cues through a large-scale database of uncurated images. To address this new task, we propose a novel framework that jointly understands spatial environments and detects changes. The main idea is that matching at the same spatial locations between a query and a reference may lead to a suboptimal solution due to viewpoint misalignment and limited field-of-view (FOV) coverage. We deal with this limitation by leveraging multiple reference candidates and aggregating semantically rich representations for change detection. We evaluate our framework on three standard benchmark sets reconstructed for ECD, and significantly outperform a naive combination of state-of-the-art methods while achieving comparable performance to the oracle setting. The code will be released upon acceptance.
Zero-Shot Scene Change Detection
Jun 17, 2024
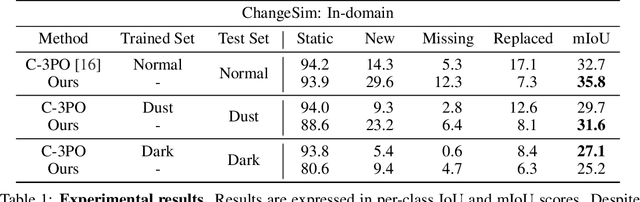
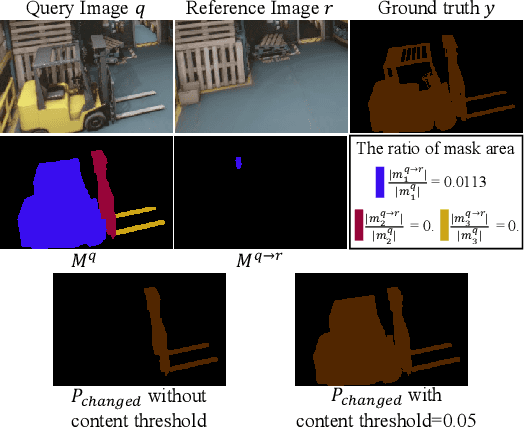
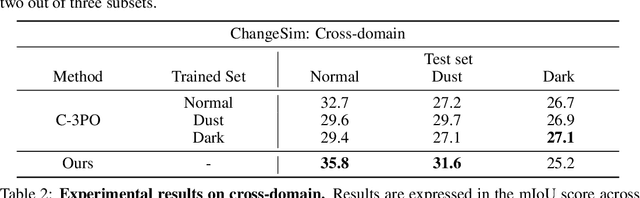
We present a novel, training-free approach to scene change detection. Our method leverages tracking models, which inherently perform change detection between consecutive frames of video by identifying common objects and detecting new or missing objects. Specifically, our method takes advantage of the change detection effect of the tracking model by inputting reference and query images instead of consecutive frames. Furthermore, we focus on the content gap and style gap between two input images in change detection, and address both issues by proposing adaptive content threshold and style bridging layers, respectively. Finally, we extend our approach to video to exploit rich temporal information, enhancing scene change detection performance. We compare our approach and baseline through various experiments. While existing train-based baseline tend to specialize only in the trained domain, our method shows consistent performance across various domains, proving the competitiveness of our approach.
Domain Adaptive Video Semantic Segmentation via Cross-Domain Moving Object Mixing
Nov 04, 2022The network trained for domain adaptation is prone to bias toward the easy-to-transfer classes. Since the ground truth label on the target domain is unavailable during training, the bias problem leads to skewed predictions, forgetting to predict hard-to-transfer classes. To address this problem, we propose Cross-domain Moving Object Mixing (CMOM) that cuts several objects, including hard-to-transfer classes, in the source domain video clip and pastes them into the target domain video clip. Unlike image-level domain adaptation, the temporal context should be maintained to mix moving objects in two different videos. Therefore, we design CMOM to mix with consecutive video frames, so that unrealistic movements are not occurring. We additionally propose Feature Alignment with Temporal Context (FATC) to enhance target domain feature discriminability. FATC exploits the robust source domain features, which are trained with ground truth labels, to learn discriminative target domain features in an unsupervised manner by filtering unreliable predictions with temporal consensus. We demonstrate the effectiveness of the proposed approaches through extensive experiments. In particular, our model reaches mIoU of 53.81% on VIPER to Cityscapes-Seq benchmark and mIoU of 56.31% on SYNTHIA-Seq to Cityscapes-Seq benchmark, surpassing the state-of-the-art methods by large margins.