 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Domain Adaptation for Semantic Segmentation by Content Transfer
Dec 23, 2020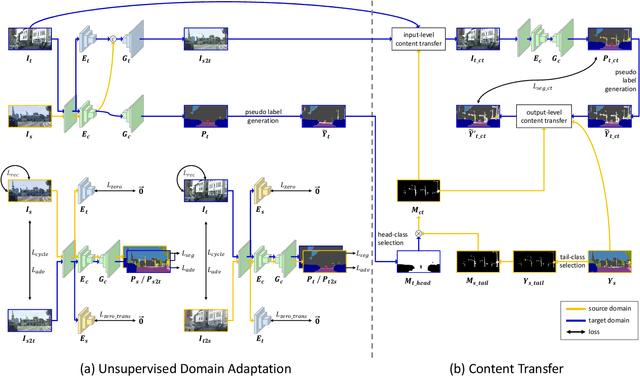
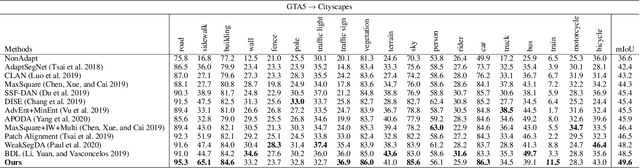


In this paper, we tackle the unsupervised domain adaptation (UDA) for semantic segmentation, which aims to segment the unlabeled real data using labeled synthetic data. The main problem of UDA for semantic segmentation relies on reducing the domain gap between the real image and synthetic image. To solve this problem, we focused on separating information in an image into content and style. Here, only the content has cues for semantic segmentation, and the style makes the domain gap. Thus, precise separation of content and style in an image leads to effect as supervision of real data even when learning with synthetic data. To make the best of this effect, we propose a zero-style loss. Even though we perfectly extract content for semantic segmentation in the real domain, another main challenge, the class imbalance problem, still exists in UDA for semantic segmentation. We address this problem by transferring the contents of tail classes from synthetic to real domain. Experimental results show that the proposed method achieves the state-of-the-art performance in semantic segmentation on the major two UDA settings.
Kernelized Memory Network for Video Object Segmentation
Jul 16, 2020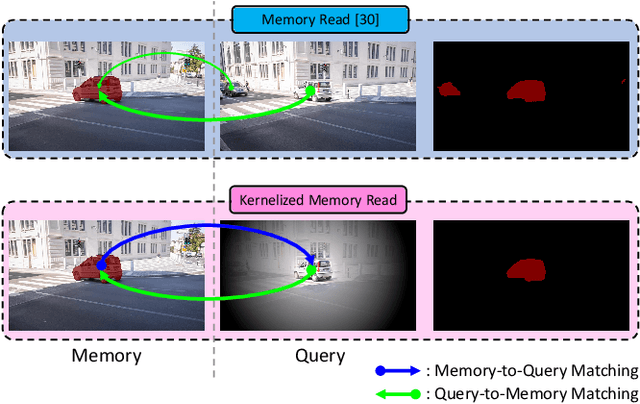
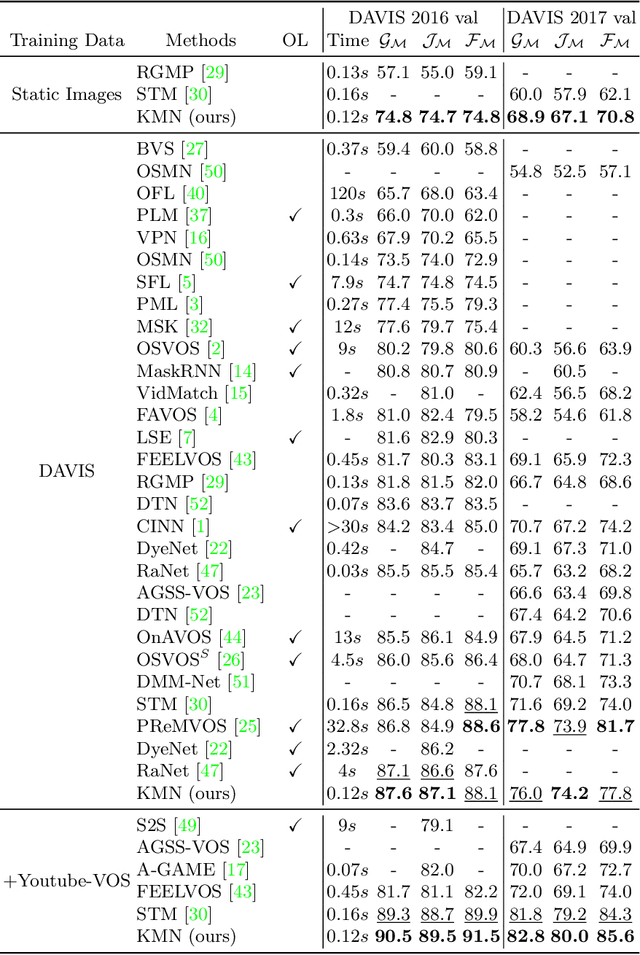
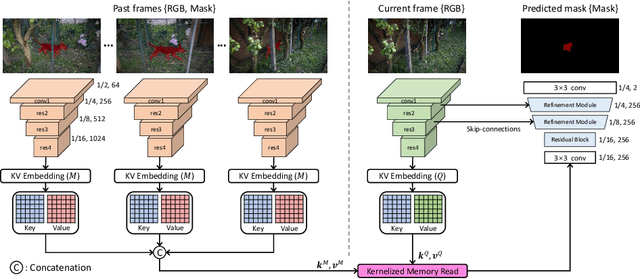
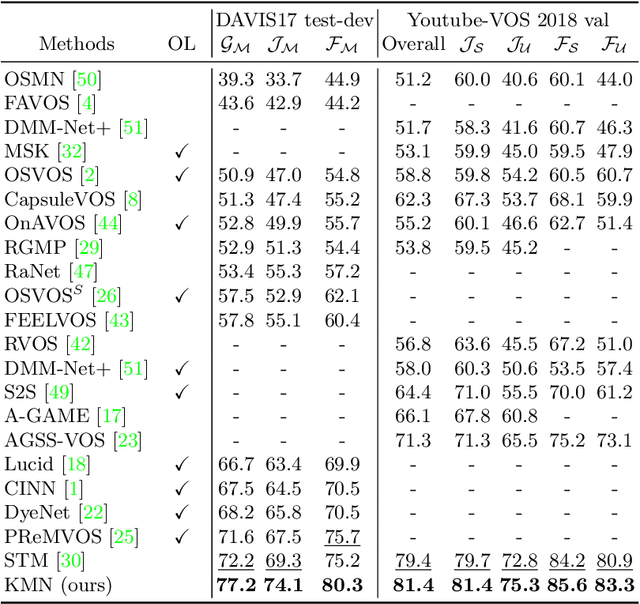
Semi-supervised video object segmentation (VOS) is a task that involves predicting a target object in a video when the ground truth segmentation mask of the target object is given in the first frame. Recently, space-time memory networks (STM) have received significant attention as a promising solution for semi-supervised VOS. However, an important point is overlooked when applying STM to VOS. The solution (STM) is non-local, but the problem (VOS) is predominantly local. To solve the mismatch between STM and VOS, we propose a kernelized memory network (KMN). Before being trained on real videos, our KMN is pre-trained on static images, as in previous works. Unlike in previous works, we use the Hide-and-Seek strategy in pre-training to obtain the best possible results in handling occlusions and segment boundary extraction. The proposed KMN surpasses the state-of-the-art on standard benchmarks by a significant margin (+5% on DAVIS 2017 test-dev set). In addition, the runtime of KMN is 0.12 seconds per frame on the DAVIS 2016 validation set, and the KMN rarely requires extra computation, when compared with STM.
Universal Pooling -- A New Pooling Method for Convolutional Neural Networks
Jul 26, 2019

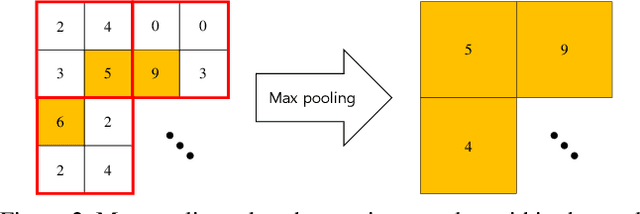

Pooling is one of the main elements in convolutional neural networks. The pooling reduces the size of the feature map, enabling training and testing with a limited amount of computation. This paper proposes a new pooling method named universal pooling. Unlike the existing pooling methods such as average pooling, max pooling, and stride pooling with fixed pooling function, universal pooling generates any pooling function, depending on a given problem and dataset. Universal pooling was inspired by attention methods and can be considered as a channel-wise form of local spatial attention. Universal pooling is trained jointly with the main network and it is shown that it includes the existing pooling methods. Finally, when applied to two benchmark problems, the proposed method outperformed the existing pooling methods and performed with the expected diversity, adapting to the given problem.
FOSNet: An End-to-End Trainable Deep Neural Network for Scene Recognition
Jul 18, 2019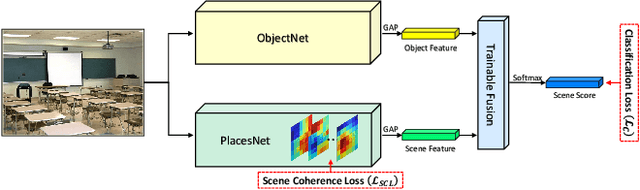
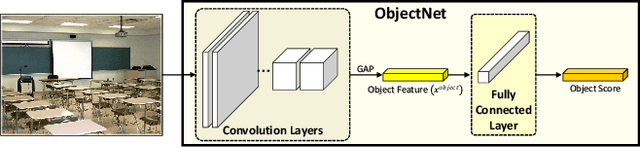


Scene recognition is an image recognition problem aimed at predicting the category of the place at which the image is taken. In this paper, a new scene recognition method using the convolutional neural network (CNN) is proposed. The proposed method is based on the fusion of the object and the scene information in the given image and the CNN framework is named as FOS (fusion of object and scene) Net. In addition, a new loss named scene coherence loss (SCL) is developed to train the FOSNet and to improve the scene recognition performance. The proposed SCL is based on the unique traits of the scene that the 'sceneness' spreads and the scene class does not change all over the image. The proposed FOSNet was experimented with three most popular scene recognition datasets, and their state-of-the-art performance is obtained in two sets: 60.14% on Places 2 and 90.37% on MIT indoor 67. The second highest performance of 77.28% is obtained on SUN 397.